2020-04-07
2020-04-07 509
509Мы не будем детально обсуждать вопрос о том, как реализуются трансляторы и интерпретаторы - это тема отдельного курса. Но нам необходимо понимать, какой смысл заключён в программе как в тексте на языке программирования хотя бы для того, чтобы наше представление соответствовало тому, что реализует система програмирования. Как и в естественных языках нам приходится решать две задачи:
· Как на данном языке выразить то, что мы хотим сказать? То есть нам требуется преобразовать смысл во фразу – задача синтеза;
· Как понять смысл фразы на данном языке? Это задача анализа или разбора фразы.
В своей практике программисты постоянно решают эти две задачи, пытаясь написать новую программу и понять то, что написали другие программисты.
Отличие от естественных языков состоит в том, то что языки программирования намного проще и, чаще всего, однозначнее, а их правила могут быть в значительной степени описаны формально[2]. Ниже мы рассмотрим некоторые аспекты языков программирования и способы их описания.
Целью языка программирования как знаковой системы является сопоставление последовательности символов некоторого смысла:
| Знак |
| Смысл (денотат) |
Продемонстрируем это на простом примере. Попробуем понять, что означает запись
45.7
Естественным ответом будет: "Действительное число 45.7". Однако, если мы попытаемся проанализировать, каким образом мы дали такой ответ, то всё окажется не так просто. Во-первых, исходно мы видим не число, а линии и пятна на бумаге или экране дисплея, которые мы идентифицируем как символы - десятичные цифры и точку, записанные в определённой последовательности. Далее мы анализируем эти символы и понимаем, что они образуют запись десятичного числа с дробной частью. Для этого мы убеждаемся, например, в том, что точка встречается только один раз; запись "8.383.363.40.20" как десятичное число не воспринимается. Далее мы подсознательно сопоставляем каждой цифре число в пределах от 0 до 9, применяем позиционную форму записи, умножая каждое из чисел на соответствующую (положительную или отрицательную) степень 10, и, наконец, всё суммируя, получаем некоторый абстрактный объект, принадлежащий полю действительных чисел. Для того чтобы выразить полученный результат, мы делаем обратное преобразование.
Заметим, что в ходе этого мыслительного процесса мы подсознательно сделали несколько важных предположений. Во-первых, мы сразу решили, что это действительное число, а не, скажем, номер дома. Во-вторых, мы воспользовались десятичной системой счисления, хотя никто нам не говорил, что это именно десятичные цифры, а не восьмеричные или шестнадцатеричные. В-третьих, мы решили, что точка используется для отделения целой части от дробной, хотя в русской нотации для этого следовало бы использовать запятую.
Так или иначе, мы вложили в исходную запись смысл, а весь процесс сопоставления реализовал семантическую функцию, отображающую последовательнось символов в абстактные действительные числа:
Sem("45.7") = 4*101 + 5*100 + 7*10-1 = 45.7
Аналогичные, но гораздо более сложные процессы происходят и при сопоставлении смысла программам, исходным представлением которых является последовательность символов[3], а конечным, например, функция, реализующая отображение входных данных программы в выходные. Концептуально процесс разбивается на отдельные фазы:
- лексический анализ подобен орфографии естественного языка, где мы выделяем слова и знаки препинания, классифицируя при этом слова как существительные, глаголы, наречия, частицы и т.п. Лексический анализ выделяет так называемые лексемы, для каждой из которой известен её класс - идентификатор, служебное слово, число, служебный символ и т.п. Отметим, что лексемы, хотя и могут иметь привязку к исходому тексту, являются абстрактными объектами, и для последующих стадий уже не важно, каким образом было получена, скажем, лексема "действительно число 45.7" - как запись "45.7" или "0.457e+2". Важно лишь знать класс лексемы - "число" и специфичный для этого класса атрибут - действительное число.
- синтаксический анализ получает на входе последовательность лексем и восстанавливает структуру программы, подобно тому как в естественных языках из слов и знаков препинания строятся предложения с указанием того, что является подлежащим, сказуемым, дополнением, подчинённым оборотом и т.п. Из предложений могут собираться параграфы, сноски, разделы, эпиграфы, главы, послесловия т.д. Таким образом, результатом анализа является иерархия объектов, относящихся к определённым языком синтаксическим категориям.
- семантический анализ на основе известной структуры текста определяет его смысл. В большинстве случаев семантика имеет композиционный характер. Например, смысл параграфа получается как композиция смысла составляющих его предложений. Однако, зачастую для того, чтобы понять смысл отдельной фразы, необходимы определённые знания о тексте в целом. Простейшим примером является упоминание имени какого-либо персонажа, который появляется в предыдущей главе. Может также оказаться, что один и тот же текст имеет совершенно разные смыслы в зависимости от обстановки, в которой он воспринимается.
Помимо этих ключевых фаз осмысления текста есть и другие важные свойства, такие как лаконичность, стиль и т.п.
Лексика
Лексика языка программирования описывает, из каких слов строятся фразы, то есть словарный запас. Под словами мы будем далее понимать произвольную последовательность символов входного алфавита. Абстракция понятия слова, при котором мы отвлекаемся от его написания, произношения и словоформы, называется лексемой. Типичными классами лексем в языках программирования являются следующие:
· Числа: 123.4e2, 12, 0x25
· Знаки: +,!=, [, <<, <
· Идентификаторы: i, Pi2, PersonID
· Ключевые слова: while, if
· Строки: "Hello, World", "while + 1"
· Символы: 'a'
Задачей лексического анализа является разбиение входного текста программы на поток[4] лексем, каждый элемент которого содержит
· класс лексемы - признак того, является ли лексема идентификатором, строкой, числом и т.д.;
· значение лексемы, зависящее от её класса: для чисел это значение числа, для строк - последовательность составляющих её символов, для идентификаторов - приведённое к каноническому виду имя, либо номер идентификатора в глобальной таблице идентификаторов, и т.д.;
· привязку к исходному тексту, т.е. имя файла, номер строки и позицию в строке, где лексема появилась.
Для лексического анализа необходимо определение того, что же является лексемой в данном языке. Попробуем начать с неформального определения. Например, мы можем сказать, что в языке имеются идентификаторы, которые представляются последовательностями букв и цифр, начинающихся с буквы. На первый взгляд, это вполне понятное определение, но при детальном рассмотрении приходится делать много уточнений:
· Что понимается под «буквой»? Допускается ли кириллица? Например, является ли идентификатором слово "индекс"?
· Различаются ли прописные и строчные буквы? Например, PersonID и PerSoniD – это один и тот же идентификатор или разные?
· Есть ли ограничение на длину идентификатора? Не слишком ли длинен идентификатор TheBestApproximationReachedSoFar? А если такое ограничение есть, то оно обеспечивается тем, что слишком длинные идентификаторы приводят к ошибке на стадии лексического анализа, или тем, что лишние символы просто игнорируются?
· Допускается ли использование подчерка в идентификаторе, как в student_count, а если допускается, то в каком месте? Может ли идентификатор начинаться c подчерка или заканчиваться им, как в __FILE__ и _1? А состоять из одних подчерков, как в _ или ___?
· Не забыли ли мы про другие символы? Некоторые языки позволяют использовать вопросительный знак в конце идентификатора, как в IsLegal?, а также символы #, @ и т.п,
· Можно ли в идентификаторе использовать пробелы? Если да, то они входят в имя идентификатора или игнорируются?
Таким образом, опредение лексики требует более строгого, формального описания. Наиболее часто для этой цели используются регулярные выражения. Так, например, описание идентификатора может быть записано следующим образом:
(_|[a..z])(_|[a..z]|[0..9])*
Регулярные выражения сами образуют язык в том смысле, что они имеют свою лексику, а каждое регулярное выражение структуру и определённый смысл. Приведённое выше выражение разбивается на два: (_|[a..z]) и (_|[a..z]|[0..9])*. Первое из них в свою очередь тоже имеет две «альтернативные» части: _ и [a..z], а второе – «применяет» операцию повторения * к подвыражению (_|[a..z]|[0..9]) и т.д. Следуя структуре регулярного выражения, можно определить его смысл – множество допускаемым им цепочек. В данном случае, выражение «читается» следующим образом:
· цепочки начинаются либо с _, либо с символа в диапазоне от a до z.
· после чего повторяются ноль или более раз группы символов, где каждая группа:
o либо _,
o либо символ в диапазоне от a до z,
o либо символ в диапазоне от 0 до 9.
Регулярные выражения удобно использовать для описания множества лексем. Обратная задача – определение принадлежности данной последовательности символов множеству лексем эффективно решается с помощью конечных автоматов. Известно, что по любому регулярному выражению можно построить разрешающий конечный автомат. В нашем примере, такой автомат может иметь следующий вид:
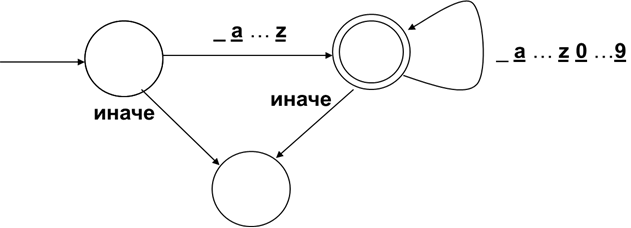
Вершины диаграммы автомата обозначают его состояния. В процессе распознавания последовательности символов надо «пройти» от начального состояния, к которому ведёт дуга «извне», к заключительному состоянию, отображаемому двойным кружком, переходя на каждом шаге в новое состояние по дуге согласно очередному символу.
Следует отметить, что не все аспекты обработки входного текста охватываются лексическим анализом, а в некоторых случаях не могут быть формально описаны регулярными выражениями. Например,
· пробелы, переводы строк, табуляции в большинстве случаев рассматриваются не как лексемы, а как разделители лексем;
· в «старых» языках программирования может сохраняться привязка текста к перфокартам, и некоторые позиции, к примеру с 1 по 7 и с 72 до конца строки игнорируются.
· Различного вида комментарии также рассматриваются как разделители. При этом язык может допускать, а может и не допускать вложенные комментарии: к примеру, в языке C:
/*начало комментария
/*вложенный комментарий*/
конец комментария*/
текст «конец комментария */» на самом деле не будет частью комментария, как можно было бы предположить.
Таким образом, лексический анализ включает некоторую предобработку входного текста, после которой он может быть разобран конечным автоматом.
Отметим, что описание допустимых лексем не всегда позволяет однозначно выполнить лексический анализ, который, напомним, состоит в разбиении входного текста на последовательность лексем. Конфликт возникает, когда одна лексема является префиксом другой. Так, в языке C текст << рассматривается как одна лексема «сдвиг влево», а не как две лексемы «меньше». Утрированно можно задать вопрос, представляет ли AB один идентификатор или два - A и B? Обычно такой конфликт разрешается путём выделения максимальной возможной лексемы.
После того как мы выделили из входного потока текст очередной лексемы, необходимо вычислить её атрибуты. Этот процесс тоже требует формального описания, поскольку не каждая текстуально правильная лексема имеет смысл. Например, запись вещественного числа 1e+100000000000 правильна с точки зрения регулярного выражения, но может оказаться, что такие большие числа не представимы данной реализацией языка. Поскольку разные представления лексемы могут давать одни и те же значения атрибутов, то мы можем рассматривать этот процесс как нормализацию лексем, то есть приведение их к некоему нормальному виду, например:
· Числа 1.23 и 123e-2 приводится к форме 0.123e+1
· В языке C восьмеричное число 073 и десятичное число 59 приводятся к одинаковому двоичному представлению.
· Идентификаторы Count, COUNT и coUnt в языке Паскаль приводятся к count, поскольку регистр букв этом языке не различается.
· В языке Кобол число ноль может быть записано и как ZERO, и как ZEROS, и даже как ZEROES, но все эти записи приводится к форме 0.
Некоторые идентификаторы преобразуется в специальные лексемы, называемые ключевыми словами, которые играют особую роль в определении синтакиса. Например, в языке C около 30 ключевых слов: while, if, const, extern, enum и т.д. Обычно языки программирования, по крайней мере изначально, запрещают использовать ключевые слова в качестве идентификаторов. Проблемы возникают по мере "взросления" языка и появления в нём новых синтаксических конструкций, которые требуют новых ключевых слов. В некоторых языках количество ключевых слов исчисляется сотнями и даже тысячами. Более того, может оказаться, что новые ключевые слова могут уже использоваться в программах, написанных на предыдущей версии языка. Чтобы смягчить остроту этой проблемы, из множества ключевых слов выделяют относительно небольшое множество зарезервированных, которые нельзя использовать для иных целей, а остальные становятся ключевыми только в определённом контексте. Следствием такого подхода является то, что лексический анализ нельзя выполнить независимо от синтаксического.
Некоторые языки программирования предоставляют возможность использовать произвольное слово в качестве идентификатора, если оно декорировано специальными символами. Например, некототорые диалекты SQL используют для этой цели квадратные скобки: SELECT - зарезервированное ключевое слово, [SELECT] - идентификатор с именем SELECT.
Поскольку мы уже затронули вопрос о кириллице, то рассмотрим подробнее проблемы, связанные с национальными версиями языков программирования. Ниже приведены три версии процедуры на языке Алгол-60 вычисления наибольшего общего делителя, использующей вспомогательную функцию вычисления остатка от деления двух целых чисел. Первая версия – чисто английская, где мы должны привлечь некоторое знание английского языка и перевести содержательные используемые понятия: «НОД» - greatest common devisor (GCD) и остаток – remainder (Rem). Во второй версии мы используем английские ключевые слова, но русские идентификаторы. Наконец, третья версия – чисто русская.
| procedure GCD(x,y,z); value x,y; integerx,y,z; begin integer procedureRem(A,B); value A,B; integer A,B; Rem:= A – (A % B) * B; begin integeru; foru:=Rem(x,y) whileu ≠ 0 do begin y:= x; x:= u end; end; z:= x end | procedure НОД(x,y,z); value х,y; integerx,y,z; begin integer procedureОСТ(A,B); value A,B; integer A,B; ОСТ:= A – (A % B) * B; begin integeru; for u:=ОСТ(x,y) whileu ≠ 0 do begin y:= x; x:= u end; end; z:= x end | проц НОД(x,y,z); знач x,y; целx,y,z; начало цел процОСТ(A,B); знач A,B; цел A,B; ОСТ:= A – (A%B)*B; начало целu; дляu:=ОСТ(x,y) покаu≠0 цикл начало y:= x; x:= u конец; конец; z:= x конец |
Можно было бы рассмотреть и вариант, в котором используется транслитерация с кириллицы на латинский алфавит: NOD вместо НОД и OST вместо ОСТ.
Если предположить, что программист совсем не владеет английским языком, то ему, конечно, третья версия покажется наиболее предпочтительной. Если программист владеет английским в объёме словаря ключевых слов языка программирования, то ему подойдёт и вторая версия. Однако, он должен отдавать себе отчёт в том, что в этом случае его код будет нечитаем для другого программиста, который не знает русского, если оба они работают в транснациональной компании.
Проблемы национальных версий этим не ограничиваются:
· Для «правильного» перевода бывает нужно менять не только лексику, но и синтаксис, структуру фраз.
· Программа разрабатывается и исполняется в окружающей обстановке, которая может и не поддерживать русские имена. Кроме того, если программа использует «иноязычные» библиотеки, большой набор которых обычно поставляется с системой программирования, то в тексте программы образуется смесь идентификаторов на разных языках.
· Если возникнет задача переноса программы на другую платформу, то имеющийся там транслятор может не поддерживать нужную национальную версию.
· Изображение данных в разных обстановках может также различаться:
o Числа - десятичная точка или десятичная запятая?
o Даты - 09/01/04 или 04/01/09?
· Если используются английские ключевые слова и русские идентификаторы, то становится очень неудобно набирать текст из-за необходимости частого переключения раскладки клавиатуры. Это на первый взгляд мелкая, но очень раздражающая проблема.
· Возрастает опасность совпадения разных букв по начертанию: например, если в идентификаторе OCT вторая буква окажется не кириллической «С», а латинской «C», то причина выдаваемой ошибки будет совсем неочевидна.
Таким образом, можно сделать вывод, что национальные версии языков имеют смысл только в том случае, если заранее ограничена область их применения. Примерами таких языков могут служить, автокод Эль-76 [??], разработанный специально для советского суперкомпьютера Эльбрус, язык и система программирования Альфа [??], для которых были сделаны даже специальные устройства ввода, внутренний язык системы 1С [??], ориентированный на специфику делопроизводства на российских предприятиях.
Синтаксис
Имея на входе поток лексем, синтаксический анализ разбирает структуру предложения языка программирования. В этом разделе мы будем рассматривать контекстно-свободный синтаксис, то есть такой, при котором структура фразы определяется вне зависимости от того, в каком месте эта фраза написана. Для задания контекстно-свободного синтаксиса мы будем использовать РБНФ и синтаксические диаграммы.