2020-04-07
2020-04-07 166
166В языках могут использоваться разного рода умолчания. Придуманные когда-то с целью «облегчить» жизнь программиста, сейчас они широко признаются как потенциальный источник проблем и всячески не рекомендуются к использованию. Рассмотрим, например, следующий фрагмент программы, подсчитывающий количество строк в файле:
int cnt;
char line[128]
FILE * file;
…
while (fgets(line, 127, file)!= NULL)
cnt ++;
Предположим, что переменная cnt объявлена глобальной и программист знает, что реализация языка гарантирует инициализацию нулём всех глобальных целочисленных переменных. Поэтому, чтобы избежать излишних действий по инициализации переменной, он положился на умолчание. Всё это будет работать до тех пор, пока из каких-то соображений программист не решит оформить этот фрагмент в виде функции. Тогда совершенно неожиданно будет выдан непредсказуемый результат, и для того, чтобы исправить ошибку, придётся вспомнить про сделанное предположение и про то, что для локальных переменных функций в языке C инициализация не обеспечивается.
В смысле эффективности лучше положиться на то, что транслятор сам обнаружит излишние действия, а если даже не обнаружит, то безопасность кода в любом случае перевешивает соображения эффективности такого уровня.
Мнемоничные идентификаторы
Критичной для понимания текста является мнемоничность используемых идентификаторов. Рассмотрим для примера следующий фрагмент, состоящий из двух вложенных циклов:
int n1, n2;
...
for (int index_of_outer_loop = 0;
index_of_outer_loop < n1;
index_of_outer_loop ++)
for (int intIndexJ = 0; intIndexJ < n2; intIndexJ ++)
...
Здесь программист решил дать длинные названия переменным циклов, чтобы явно их отличать друг от друга. Однако очевидно, что это не улучшило понимаемость программы. Прежде всего раздражает разный стиль в выборе названий. Для первой переменной было подчёркнуто, что это именно параметр цикла, тогда как во втором - что эта переменная целого типа. В любом случае, если предположить, что тело цикла занимает несколько десятков строк, то не требуется просматривать всю программу, чтобы понять какая переменная к какому циклу относится. С другой стороны, для переменных n1 и n2 програмист выбрал скромные, ничего не говорящие названия, подсказывающие только то, что они обе целого типа, поскольку начинаются с буквы "n", и что они как-то связаны между собой.
Правильнее в смысле читаемости программы было бы назвать переменные следующим образом:
int PersonCount;
int ExamCount;
...
for (int p = 0; p < PersonCount; p++)
for (int e = 0; e < ExamCount; e ++)
…
Из названия первых двух переменных сразу понятно, что они обозначают количество человек и количество экзаменов. Переменные циклов названы коротко, но согласовано с именами тех объектов, которые они индексируют. Общее неформальное правило можно сформулировать так: "длина идентификатора пропорциональна размеру области его действия".
Отметим ещё одно мелкое замечание к указанному фрагменту: не следует располагать несколько описаний переменных на одной строчке, даже если это допускается языком.
Комментарии
Хорошо структурированная программа с мнемоничными именами во многом самодокументирована. Однако, далеко не всегда всё, что хочется и нужно сказать про программу, удаётся выразить средствами самого языка. В этом случае используются комментарии. Рассмотрим, например, следующий фрагмент программы:
int max = 0;
for (int i = 0; i < n; i++)
if (M[i] > max)
max = M[i];
Несмотря на его простоту, требуется некоторое время, чтобы понять, что именно он делает, а потом соотнести с тем, как он это делает. Программисты зачастую не любят писать комментарии, в частности, потому, что в момент составления программы знание «что» для них очевидно, а «как» - ещё не вполне. Обратная ситуация у того, кто читает программу. И положение читателя в определённом смысле сложнее, поскольку почти любая программа делает больше, чем от неё требуется: например, устанавливает значения вспомогательных переменных. Поэтому комментирование текста программы зачастую насаждается административными методами. Скажем, требуется, чтобы любая подпрограмма имела содержательное описание своих аргументов и результатов, а также их допустимых значений. Более того, поскольку наличие комментариев можно достаточно легко проверить автоматически, то программисту просто не дадут "сдать" программу, если комментариев не хватает.
Однако, бездумная вставка комментариев может иметь обратный эффект:
/* начальник приказал написать
комментарии к каждой строчке
– ему же хуже будет:-[ */
int max = 0; // присвоить 0
// перебираем i=0..n-1
for (int i = 0; i < n; i++)
if (M[i] > max) // сравниваем с max
max = M[i]; // обновляем, если надо
В этом примере комментарии, несмотря на их обилие, абсолютно ничего не добавляют содержательно собственно к коду. Более разумно комментарии к тому же фрагменту могли бы выглядеть следующим образом:
/*
* Нахождение максимума max в массиве M
*/
int max = 0; // предполагается, что все M[i] > 0
for (int i = 0; i < n; i++)
if (M[i] > max)
max = M[i];
Здесь второй комментарий задаёт условие корректности, которое можно было упустить при беглом прочтении.
Прагматика
Прагматика языка – его соотвествие поставленным целям. Под этим в зависимости от контекста понимаются довольно разные вещи. Так, некоторые языки создавались для решения определённого класса задач. Например, язык Кобол разрабатывался для создания обработки экономической информации, Фортран – для реализации научных расчётов, Modula-2 – для математического моделирования и т.д. При этом учитывается не только и не столько набор языковых конструкций, сколько возможность эффективной реализации в конкретной обстановке использования. Так, например, для преимущественно вычислительных задач вряд ли подойдут интерпретируемые языки или языки со сложным, неконтролируемым программистом распределением памяти. Но во многих случаях оказывается, что язык, если и ориентирован, то не на класс задач, а на пристрастия и квалификацию программистов. Например, в языке Кобол нет никаких особых конструкций для управления прохождением финансовых транзакций, а в языке Фортран – ничего специального для обращения матриц.
Можно говорить и о прагматике отдельных языковых конструкций. Одно и то же содержательное действие может быть запрограммировано разными способами, подчёркивающими или, наоборот, скрывающими суть этого действия. Рассмотрим следующие четыре фрагмента, которые делают одно и то же – меняют значение n на его абсолютную величину.
| while(n<0){ n = -n; break; } | if (n<0) n = -n; | n = (n<0?–n:n); | n>=0||n=-n; |
Первый способ следует признать самым неудачным, хотя он и делает всё правильно, но циклы не предназначены для реализации выбора альтернатив. Выбор между вторым и третьим вариантом можно обосновать тем, что именно мы хотим подчеркнуть: то, что что-то выполняется лишь при отрицательном n, или то, что целью всей этой конструкции является получение нового значения n. Четвёртый способ, хотя он и самый краткий, использует связку ||, которая предназначена для вычисления логической дизъюнкции и не вычисляет второй аргумент, если первый истинен. Кроме того, он использует побочный эффект в выражении, что также нежелательно без весомых на то причин.
Преемственность
Языки программирования, как и программы, имеют свой жизненный цикл. Появление и развитие языков программирования может обосновываться множеством разнообразных причин: от необходимости решения практических задач до языкового оформления математических концепций. Причём практически всегда новые языки что-то заимствуют из уже существующих. Далеко не всегда, а точнее, лишь в редких случаях новые языки прорабатываются на предмет непротиворечивости, ортогональности, возможности к расширению и т.п.
Если язык живёт достаточно долго, то в него включаются дополнительные возможности, отражающие новые области применения, либо популярные в текущий момент концепции. Причём причины, повлёкшие расширение, могут со временем становится неактуальными, а конструкции или их следы в языке остаются. Например, исходное описание языка Алгол-60 - достаточно полное, хотя и неформальное - занимало лишь несколько десятков страниц, а описание его прямого наследника Unisys Algol - уже несколько тысяч. В частности, в нём имеются три независимых макропроцессора, специальные конструкции для работы с базами данных, коммуникационными протоколами и пр. Аналогичные истории случились с языками Фортран, Кобол, Лисп и многими другими "ветеранами".
Обратная совместимость, т.е. необходимость сохранения всего накопленного, является главным тормозом развития. Для того, чтобы исключить или изменить какую-то языковую конструкцию, требуется сначала предупредить об этом всё сообщество пользователей языка и подождать несколько лет, чтобы они могли переделать все существующие программы. Если за это время не нашлось весомых аргументов против, то внести изменения в язык. Понятно, что в такой обстановке проще оставить всё как есть.
Язык C много заимствовал, в частности, от языков Фортран и Алгол-60. В свою очередь, он лёг в основу целого семейства языков: C++, Java, C#, Javascript и др. Язык C++ опять же для обеспечения обратной совместимости просто целиком включил в себя язык С. Это дало возможность сохранить весь накопленный багаж и плавно подвести программистов к использованию объектно-ориентированного программирования, но навсегда сделало язык внутренне противоречивым. Язык Java, напротив, унаследовал от языка C лишь стиль большинства синтаксических конструкций, в расчёте на то, что это облегчит освоение языка. Конечно, возможность использования накопленных библиотек должна быть обеспечена, но всё новое программное обеспечение должно разрабатываться на новом языке.
Критикуя решения, принятые при разработке языка программирования, следует помнить, что они создавались в определённой обстановке, включающей уровень развития вычислительных средств и методов реализации языков программирования.
Препроцессор
Далее мы будем рассматривать основные конструкции языка С. Хотя он и будет нашей основной целью, рассмотрение мы будем сопровождать сравнительным анализом с другими языками, что должно позволить нам судить о положительных и отрицательных последствиях решениий, принятых разработчиками языка, и о том, как это можно было бы сделать иначе.
То, что мы обычно понимаем под программой на языке C, на самом деле является программой на языке препроцессора языка С, из которой уже получается программа на C. Препроцессор является макропроцессором, осуществляющим текстовую обработку на основе директив, вставленных непосредственно в текст. Некоторые директивы, могут определять так называемы макросы, то есть шаблоны правил для преобразования текста. Если такой шаблон встречается в тексте, то он называется вызовом макроса и заменяется согласно соответствующему правилу.
Рассмотрим, например, следующую программу:
#define SMALL
#ifdef SMALL
#define N 10
#define number short int
#else
#define N 10000
#define number long int
#end if
#define reverse(k) N – k
number A[ N ];
void main()
{
for (int i = 0; i< N; i++)
A[i] = reverse(i) * reverse(i);
}
Всё, что здесь выделено жирным, относится к командам препроцессора. На самом деле и остальную, невыделенную часть можно рассматривать как команды препроцессора, суть которых состоит в том, чтобы перенести себя в результирующий текст. В результате работы препроцессора получается следующий текст на языке C[11].
short int A[10];
void main()
{
for (int i = 0; i<10; i++)
A[i] = 10 - i * 10 - i;
}
Синтаксис
Поскольку мы говорим, что у препроцессора есть свой язык, то мы можем говорить и о всех свойственных ему понятиях - лексике, синтаксисе, семантике. Лексика препроцессора является расширением лексики языка C, то есть помимо понятий идентификатора, строки, числа и т.п. в нём имеется ещё несколько лексем, позволяющих задавать директивы. Кроме этого, поскольку препроцессор учитывает разбиение текста на строки, символ перевода строки также следует рассматривать как лексему. Мы будем обозначать её ¶.
Весь текст состоит директив, вызовов и отдельных лексем. Все директивы располагаются на отдельных строках и начинаются с символа #. Если директива очень длинная, то её можно разбить на несколько строк, каждая из которых, кроме последней, завершается символом \.
| текст: | 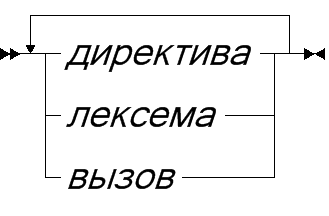
|
| директива: | 
|
8.2 Макросы и вызовы
Директива-определение задаёт макрос. Макрос может иметь параметры, которые заключаются в скобки. Тело макроса - последовательности лексем, вызовов и использования параметров:
| определение: | 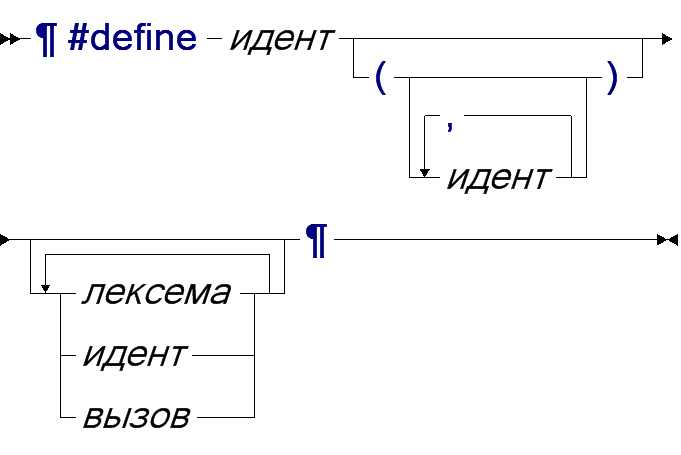
|
Макросы без параметров называются макро-переменными. Вызов начинается с идентификатора определённого макроса, за которым могут идти параметры через запятую.
| вызов | 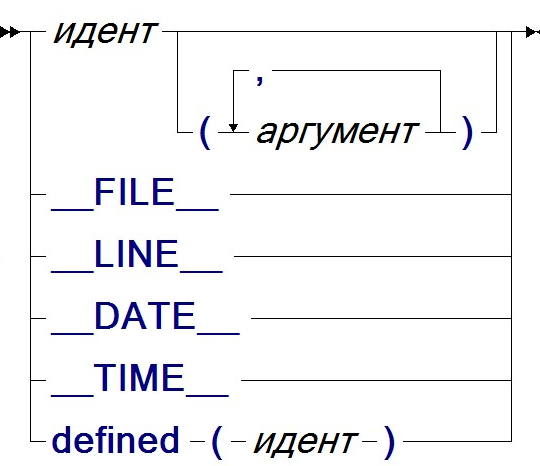
|
| аргумент | 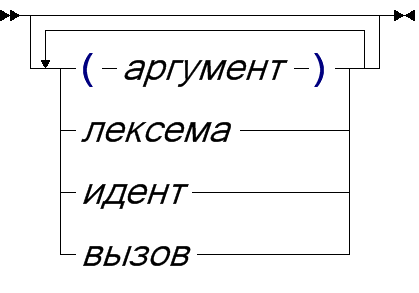
|
Заметим, что слово "определённого" в предыдущем предложении делает разбор существенно контекстно-зависимым. Например, результатом обработки
F(1)
#define F 2+
F(x)
#define F(x) (x+3)
F(3)
будет текст
F(1)
2+(x)
(x+3)
Первое вхождение F(1) вообще не является вызовом макроса, поскольку макрос F к этому моменту ещё не определён, второе - вызов макроса без параметров, третье - вызов макроса с параметром.
Понятие аргумента макроса было введено из тех соображений, что значением параметра макроса может быть произвольная последовательность лексем, включая запятые и скобки, что может привести к неожиданным последствиям. Если бы аргумент был определён просто как последовательность лексем, то препроцессор при определённом макросе F, встречая текст
F(x, (y))
мог бы истолковать его разными способами:
1. вызов макроса с параметром "x,(y)";
2. вызов макроса с двумя параметрами "x" и "(y";
3. вызов макроса с двумя параметрами "x" и "(y)";
4. и т.д.
Как же передать отдельную скобку или запятую в качестве параметра? Для этого можно использовать следующий приём:
#define comma,
#define F(x,y,z) x y z
F(a comma b)
даст в результате
a, b
поскольку обработка параметров осуществляется после подстановки тела макроса в место вызова.
Есть несколько предопределённых псевдо-макросов со специальным поведением - их раскрытие может зависеть от контекста:
· __FILE__ - строка, равная имени текущего файла;
· __LINE__ - число, равное номеру текущей строки в обрабатываемом файле;
· __DATE__, __TIME__ - строки, задающие дату и время обработки данного вызова,
· defined(имя) - логическое значение, истинное тогда, когда определён макрос с данным именем. Полезность этого псевдо-макроса станет понятна ниже, когда мы будем обсуждать условную компиляцию.
Следущий пример демонстрирует эти возможности:
#define COOL
#define N 25
#define begin {
#define end }
#define forever for (;;)
#define printnum(n) fprintf(stderr,”%d”,n)
#define printat() fprintf(stderr, \
”at:%s[%d]\n”,__FILE__,__LINE__)
COOL forever
begin
printat();
printnum(N);
end
преобразуется в следующий фрагмент на языке C
for (;;)
{
fprintf(stderr,
”at:%s[%d]\n”, “d:\\temp\\prog.c”,11);
fprintf(stderr,”%d”,25);
}
Макрос N является по сути определением константы. Это, по-видимому, самое распространённое использование препроцессора. Можно было бы завести вместо этого обычную переменную и присвоить ей в начале программы нужное значение. Однако, во-первых, доступ к переменной существенно более дорогая операция, чем доступ к константе. Во-вторых, транслятор может проводить констаные вычисления, заменяя, скажем, выражение N*N + 1 на число 626. Если бы N была переменной, то выражение вычислялось бы каждый раз, когда до него доходило исполнение. Наконец, сам препроцессор и язык С в некотрых случаях требует, чтобы выражение можно было вычислить в процессе трансляции, например, при задании размеров массивов.
Отметим, что при определении макроса никаких подстановок не происходит. Это не даёт возможности использовать макросы как переменные, значения которых можно перевычислять. Так, например,
#define A 1
#define A (A+1)
не даст ожидаемого связывания A равным 2, а приведёт к бесполезному рекурсивному макроопределению. Связывание происходит только в момент вызова макроса. Поэтому, в следующем примере
#define B 1
#define A B
A +
#define B 2
A
мы получим на выходе текст
1 + 2
Довольно сложной проблемой, связанной с семантикой препроцессора, является привязка к исходному тексту. Рассмотрим следующий фрагмент программы
int y;
#define sqr(x) (x,xx)
#define dist(x) sqrt(sqr(x))
dist(y)
для которой транслятор должен выдать сообщение о том, что переменная xx не определена. Если при этом транслятор укажет в качестве места ошибки вызов dist(y), то это вызовет недоумение, поскольку в этом месте нет никакого xx. Если же в качестве места ошибки указать вхождение xx в первой директиве #define, то будет непонятно, каким образом этот макрос был вызван. Для того, чтобы программист смог разобраться в причине ошибки, транслятор должен выдать всю цепочку вызовов и подстановок параметров, которая привела к появлению xx в месте вызова dist(y), что становится весьма затруднительно.
То, что язык препроцессора согласован с синтаксисом языка С только на лексическом уровне и то, что он, в отличии от языка С, учитывает разбиение текста на строки, может приводить к весьма неприятным последствиям. Рассмотрим, например, следующий фрагмент:
#define max (X, Y) (X > Y
? X
: Y)
max(A,B)
результатом которого естественно ожидать
(A > B? A: B)
Однако, оказывается, что результатом его станет
? X
: Y)
(X, Y) (X > Y (A,B)
Во-первых, мы забыли, что при разбиении определения макроса на несколько строк надо в конце ставить символ \. Во-вторых, между именем макроса и открывающей скобкой не должно быть пробелов, поскольку, иначе всё, начиная с этой скобки, попадёт в тело макроса[12]. Поэтому определение должно быть исправлено следующим образом:
#define max(X, Y) (X > Y \
? X \
: Y)
К счастью, в большинстве случаев такие неточности вызывают ошибки в результирующей C-программе, но понять и найти их бывает очень нелегко, поскольку с точки зрения препроцессора всё прошло нормально.
Ещё один типичный пример неправильного использования препроцессора, но уже не вызывающий и синтаксических ошибок. Пусть определён макрос
#define reverse(x) 100-x
Тогда, если в программе встретилось выражение
reverse(20) * reverse(80)
то мы ожидаем получить значение 80*20 = 1600, хотя на самом деле результатом будет 100-20 * 100-80 = 2020. Для этого рекомендуется в определении макроса заключать в скобки все выражения:
#define reverse(x) (100-(x))
Ещё большие неприятности может вызвать то, что препроцессор не согласован с языком C на семантическом уровне. Как уже было сказано, в препроцессоре сначала подставляется тело макроса вместо вызова, а уж затем обрабатываются параметры, в отличие от функций языка C, где сначала вычисляются значения параметров, а потом вычисляется тело функции. Например, если в программе встретилось "выражение"
max(f(A,B), sqrt(A*A+B*B))
то, поскольку max определён как макрос, реально будет выполняться следующий текст:
(f(A,B) > sqrt(A*A+B*B)? f(A,B): sqrt(A*A+B*B))
Во-первых, очевидно, что этот текст почти вдвое больше исходного. То, что здесь вычисление квадратного корня при ложности условия будет выполняться дважды, приводит к неэффективным вычислениям. Ещё хуже, что функция f при истинности условия будет вызываться дважды, и, если она будет иметь побочный эффект (изменять глобальную переменную, печатать что-то в выходной файл и т.п.), то он проявится дважды, хотя в исходной программе явно написан один вызов.
Стандартным оправданием для использования макросов вместо функций является то, что вызов функции имеет существенные накладные расходы. Это действительно так. Однако, во-первых, как мы только что заметили, макросы могут приводить к существенно большей неэффективности, а, во-вторых, современные трансляторы имеют весьма развитые средства анализа, которые позволяют в том случае, когда это обоснованно с точки зрения эффективности, аккуратно подставить тело функции в место вызова.
Те же причины делают бессмысленным определение рекурсивных макросов, хотя сам препроцессор это и не запрещает. Расмотрим, например, макрос, рассчитанный на вычисление факториала:
#define fact(n) (n==0? 1: (n)*fact(n-1))
fact(10)
Вызов этого макроса приводит к бесконечной рекурсивной подстановке
(10==0? 1: (10)*(10-1==0? 1: (10-1) * (10-1-1==0? (10-1-1) * …)))
поскольку всё, что происходит при вызове макросов - это операции с последовательностями лексем. Формально это приводит к зацикливанию препроцессора и чтобы транслятор не "зависал", обычно препроцессоры ограничивают глубину вызовов макросов. Некоторые языки программирования - PL/I, Unysis Алгол и др. - имеют существенно более мощные, по сравнению С, средства препроцессора, которые в том числе могут делать и вычисления, что позволяет выполнять циклы, условные операторы, рекурсивные процедуры, по сути генерирующие результирующий текст программы. Однако, поскольку мы вообще очень негативно относимся к препроцессорам, то мы не будем углубляться в их изучение.
Дублирование кода препроцессором может привести к тому, что программист потеряет контроль над размером получаемого кода. Определим, например, функцию Фибонначи с помощью макросов. Уже зная, что макрос в языке C не может быть рекурсивным, определим несколько специализированных функций - по одной для каждого значения аргумента:
#define f1 1
#define f2 1
#define f3 ((f2) + (f1))
#define f4 ((f3) + (f2))
...
#define f12 ((f11) + (f10))
Тогда вызов макроса
printf("%d", f11);
приведёт к коду длиной 897 символов:
printf("%d", ((((((((((((((((((1) + (1))) + (1))) + (((1) + (1))))) + (((((1) + (1))) + (1))))) + (((((((1) + (1))) + (1))) + (((1) + (1))))))) + (((((((((1) + (1))) + (1))) + (((1) + (1))))) + (((((1) + (1))) + (1))))))) + (((((((((((1) + (1))) + (1))) + (((1) + (1))))) + (((((1) + (1))) + (1))))) + (((((((1) + (1))) + (1))) + (((1) + (1))))))))) + (((((((((((((1) + (1))) + (1))) + (((1) + (1))))) + (((((1) + (1))) + (1))))) + (((((((1) + (1))) + (1))) + (((1) + (1))))))) + (((((((((1) + (1))) + (1))) + (((1) + (1))))) + (((((1) + (1))) + (1))))))))) + (((((((((((((((1) + (1))) + (1))) + (((1) + (1))))) + (((((1) + (1))) + (1))))) + (((((((1) + (1))) + (1))) + (((1) + (1))))))) + (((((((((1) + (1))) + (1))) + (((1) + (1))))) + (((((1) + (1))) + (1))))))) + (((((((((((1) + (1))) + (1))) + (((1) + (1))))) + (((((1) + (1))) + (1))))) + (((((((1) + (1))) + (1))) + (((1) + (1)))))))))));
С одной стороны, в данном случае это даёт возможность транслятору обнаружить, что всё это выражение является константным и вычислить его на этапе трансляции. Даже если бы оно не было константным, скажем, если бы мы заменили определения,
#define f1 x
#define f2 y
то транслятор мог бы обнаружить общие подвыражения, и с помощью вспомогательных переменных обеспечить, что каждое из них будет вычисляться один раз:
int r3 = y+x;
int r4 = r3+y;
int r5 = r4+r3;
...
int r11 = r10+r9;
printf("%d", r11+r10);
Это позволило бы почти на порядок сократить количество выполняемых операций сложения[13]. Однако, может проявиться и обратный эффект: транслятор может отказаться делать сложные оптимизации для слишком больших функций, в результате чего эффективность окажется только хуже как с точки зрения времени исполнения, так и с точки зрения памяти, поскольку объектный код так или иначе занимает какое-то место в памяти.
Директива-разопределение имеет следующий синтаксис
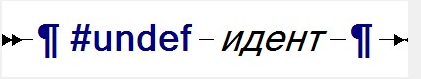
|
и позволяет препроцессору "забыть" определение указанного макроса. Назначение этой директивы связано в основном с условной компиляции, которая обсуждается ниже.
Включение файлов
Директива-включение задаётся следующим синтаксисом
| включение: | 
|
и предназначена для того, чтобы подставить в текущее место содержимое указанного файла, которое затем обрабатывается препроцессором. В этом смысле семантика директивы-включения практически совпадает с вызовом макроса без параметров, если считать, что в качестве тела макроса используется файл.
Синтаксис понятия имя-файла определяется операционной системой и её файловой системой, в которой работает препроцессор; для MSDOS, Unix и OS2200 они могут быть устроены по-разному. Это может сделать программу не переносимой из одной обстановки в другую. Если имя файла указано в угловых скобках "<" и ">", то файл ищется в системных директориях, которые указываются либо в конфигурации системы программирования, либо параметрами при запуске препроцессора. В противном случае, если имя файла заключено в кавычки, то поиск осуществляется относительно расположения текущего обрабатываемого файла. Если файл найти не удаётся, то его пробуют найти в системных директориях.
Примеры:
#include "main.h"
#include "..\\include\\person.h"
#include "../include/person.h"
#include "d:\\projects\\dialogs\\form.h"
#include <stdio.h>
#include "stdio.h"
Условная трансляция
Директива если-опред предназначена для реализации условной трансляции - включения фрагментов программы в результирующий текст только при выполнении (или невыполнении) некоторого условия. Изначально, с целью простоты обработки, язык С допускал лишь очень простые условия, заключающиеся в определённости макросов. Обычно для этой цели используются специальные макро-переменные, трактуемые как логические, причём директива
#define X
присваивает такой переменной истинное значение, а директива
#undef X
- ложное. Директива если-опред имеет следующий синтаксис:
| альтернатива |
|
| если-опред | 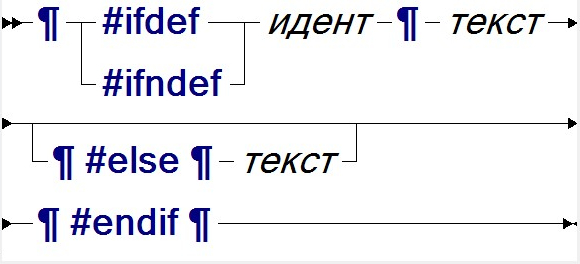
|
Для директивы #ifdef (#ifndef) первая альтернатива обрабатывается (не обрабатывается) только в случае, если на момент обработки директивы был определён (не определён) макрос идент, а в противном случае - следующая за #else вторая альтернатива, если она присутствует.
Наиболее часто условная трансляция используется для создания различных версий программы. Пусть, например, мы хотим иметь три версии программы для работы в разных операционных системах. Та непереносимость директивы #include, о которой мы говорили ранее, может быть решена следующим образом:
#ifdef MSDOS
#include "..\\dmsii\\cm.h"
#endif
#ifdef OSUNIX
#include "../dmsii/cm.h"
#endif
#if OS2200
#include "(WEBB0055)ALG/WEB/I/DMSII/CM."
#endif
Другой пример касается внутренней конфигурации программы, например, объёма памяти, которую предполагается использовать:
#define SMALL
#ifdef SMALL
#define N 100
#define number short int
#else
#define N 10000
#define number long int
#end if
Условная трансляция часто используется для отладки. Дело в том, что для получения отладочной информации могут потребоваться дополнительные переменные и вычисления, которые не имеют смысла в "боевой" версии программы и должны быть удалены из соображений эффективности. Обычно для таких целей определяют макро-переменную, называемую DEBUG:
#define DEBUG // включить отладочный режим:
#ifdef DEBUG
#define iterStop 1000
int cnt = 0;
#endif
while (...)
{
#ifdef DEBUG
if (++cnt == iterStop)
{
fprintf(stderr,
"Достигли очередной %d-й итерации", cnt);
cnt = 0;
}
#ednif
...
}
Теперь для выключения отладочного режима достаточно поменять первую строку в файле на
#undef DEBUG
Этот метод легко может быть расширен на случай отладки разных видов путём заведения нескольких макро-переменных.
Условная трансляция позволяет реализовать логические операции над макро-переменными, используемыми в директиве #ifdef. Например, мы можем (хотя и очень некрасиво и неочевидно) определить макро-переменную A = B && C следующей последовательностью директив:
#undef A
#ifdef B
#ifdef C
#define A
#endif
#endif
Макро-переменную можно задать и специальным параметром, передаваемым препроцессору при запуске. Тогда отпадает необходимость менять исходные тексты и обеспечивать согласованность определения макро-переменных в разных файлах.
Ещё одним типичным использованием условной трансляции является решение проблемы повторного включения одного и того же файла. Рассмотрим следующую ситуацию. Пусть мы определили два модуля, каждый из которых определяет некоторый набор функций и расположен в своём файле, скажем, parse.c и person.c. Для того, чтобы эти функции можно было использовать в других модулях, их спецификации следует поместить в отдельные включаемые файлы, называемые, естественно, parse.h и person.h. Пусть теперь есть другой модуль, скажем main.c, в котором надо использовать и те и другие функции, что легко сделать, вставив в его начало директивы
#include “person.h”
#include “parse.h”
Пусть теперь оказалось, что и parse.h, и person.h используют описания структур данных, собранных в файле struct.h, т.е. в каждом из них есть директива
#include “struct.h”
В итоге получилась зависимость по включению файлов, отражаемая следующей диаграммой:
| person.h |
| struct.h |
| parse.h |
| person.c |
| main.c |
| parse.c |
Тогда при обработке файла main.c препроцессор сначала встретит директиву
#include "person.h"
выполнив которую, обнаружит директиву
#include "struct.h"
в файле person.h и тем самым "поместит" содержимое struct.h в файл main.c. Закончив с person.h, препроцессор найдёт в том же main.c директиву
#include "parse.h"
а в parse.h - снова директиву
#include "struct.h"
Таким образом, struct.h будет обработано дважды, что может в дальнейшем привести к синтаксическим ошибкам, поскольку транслятор не допускает повторного определения одной и той же структуры. Для того, чтобы избежать этого, используется следующий приём. В начало любого включаемого файла, для которого следует избежать повторного включения, вставляется директива #ifndef c уникальным, предусмотренным специально для этого файла именем, традиционно имеющий суффикс _DEFINED. Тут же за ней вставляется директива #define с тем же именем:
#ifndef STRUCT_DEFINED
#define STRUCT_DEFINED
// содержимое файла struct.h
...
#endif
В итоге, при первой обработке файла будет "установлена переменная" STRUCT_DEFINED и обработано остальное содержимое файла, а при любой последующей - только проверяться условие и обнаруживаться его ложность.
Со временем, по мере увеличения доступных препроцессору вычислительных мощностей, в язык были добавлены более сложные условия, представляемые выражениями языка C с некоторыми ограничениями[14], главное из которых заключается в том, что после раскрытия всех макросов в выражении должны остаться только константы и операции. В выражении не может быть вызовов функций, поскольку это открывало бы возможность непредсказуемо долгого их вычисления или вообще зацикливания. Кроме того, функции могут иметь доступ к глобальным переменным, которые не существуют во время исполнения препроцессора. В некоторых языках программирования это ограничение более слабое - допускается вызов стандартных функций, таких как аналоги sin, strlen и т.п.
Так или иначе препроцессор языка С позволяет статически выполнять достаточно сложные вычисления, как например,
#define N 18
#define B(k) ((N & ~(k-1)) == 0)
#if (B(8))
#define scale unsigned char
#elseif (B(16))
#define scale unsigned short
#else
#define scale unsigned long
#end if
Наличие псевдо-макроса defined делает избыточными условные вида #ifdef и #ifndef. Определённость макросов можно комбинировать как между собой, так и с другими условиями:
#if (defined(A) &&!defined(B) || N>3)
…
#endif
Генерация лексем
Все рассмотренные выше команды препроцессора оперируют лишь с теми лексемами, которые так или иначе присутствовали в исходном тексте программы. Однако, есть в препроцессоре языка С две операции, которые порождают новые лексемы. Эти операции могут использоваться лишь в теле макросов.
Унарная операция # преобразует лексему в строку, содержащую преставление этой лексемы. Например,
#define A(x) #x
A(X1)
будет развёрнуто как
"X1"
В примере типичного использования этой операции
#define print(x) fprintf(stderr,"%s=%d\n",#x,x)
print(A);
будет преобразовано в
fprintf(stderr, "%s = %d\n","A", A);
что принципиально невозможно реализовать в языке С с помощью функции, поскольку в объектном коде имена переменных исчезают.
Бинарная инфиксная операция ## применяется к двум лексемам, сначала преобразуя их в строки, подобно операции #, а затем эти строки конкатенируются (склеиваются) и снова преобразуются в лексему. Например,
#define C(x,y) x##y
C(a,5)
преобразуется в
a5
Чаще всего операция ## используется для порождения новых имен. Следующий пример показывает как с помощью препроцессора можно реализовать суррогатные родовые (generic) типы. Пусть, например, мы хотим определить тип односвязного списка, но так, чтобы у этого типа был параметр - тип элементов. Следующие макро-определения
#define List(type) _##type##List
#define DeclareList(type) \
typedef struct __##type##List {\
type value;\
struct __##type##List * next;\
} * List(type)
позволяют нам далее объявлять тип списка с целыми компонентами, не повторяя описание структуры:
DeclareList(int);
что разворачивается препроцессором в
typedef struct __intList
{
int value;
struct __intList * next;
} * _typeList;
а новые переменные этого типа описывать как
List(int) a;
Отметим, что это весьма ограниченное и небезопасное решение. Например,
List(long int) x;
раскроется в синтаксически неправильную конструкцию
_long intList a;
Таким образом, эти возможности можно использовать с большой осторожностью либо от безысходности, либо при автоматической генерации С-программ. Современные языки программирования, включая С++, имеют более развитые средства метапрограммирования.
Объекты и типы
Изучение конструкций языка программирования начнём с понятия именования. Возможность дать имя некоторой конструкции, определённой в программе - функции, типу данных, переменной и т.п., - можно рассматривать как средство повышения уровня языка методом абстракции: использование имени объекта вместо него самого позволяет отвлечься от деталей его реализации. Здесь под объектами мы будем понимать именно синтаксические конструкции, а не те объекты, с которыми программа манипулирует в процессе исполнения.
Области видимости
Поскольку количество используемых программой имён может быть очень большим, то для избежания путаницы требуются средства ограничения видимости. Проводя жизненную аналогию, при упоминании имени Николай мы хотим, чтобы оно означало знакомого нам человека, а не одного из тысяч других Николаев. Но при этом иногда у нас может быть несколько знакомых Николаев и в этом случае требуются какие-то уточнения, а в определённом контексте хотелось бы упомянуть царя Николая I или Святого Николая. В языках программирования для ограничения области видимости используются следующие механизмы.
Блочная структура – иерархия областей, называемых блоками, содержащих определения объектов. Блоки обычно связаны с синтаксическими конструкциями, такими как определения функций или типов данных, модулями, структурными операторами и т.п., но не обязательно в точности с ними совпадают. Блочная структура задаёт правило видимости: имя, определённое в некотором блоке, может быть использовано в нём самом и всех вложенных блоках за исключением тех, внутри которых имеется другое определение того же самого имени. Про такие блоки говорят, что они создают "дыру" в области видимости данного имени. Для того, чтобы это правило работало, необходима однозначность, т.е. требование того, что в блоке не было нескольких определений одного и того же имени. Правило видимости определяет метод поиска определения имени: если имя не определено в том же блоке, где оно использовано, то оно ищется в охватывающем блоке и т.д. Пример, блочной структуры показан ниже:
float power
(float x, int n)
float s = 0;
for (int k = 0; k <n; k++)
{
int ss = s;
s *= x;
printf(“%f * %f = %f\n”, ss, x, s);
}
return s;
}
Заметим, что имя функции power относится не к тому же блоку, что её параметры.
Хотя правило видимости и позволяют переопределять во вложенном блоке имя, определённое в охватывающем, такая практика считается вредной, поскольку она зачастую приводит к трудно обнаруживаемым ошибкам. Например, в языке C вполне допустимо следующее определение:
int x (int x)
{
for (int x =0;x<10;x++)
{
int x =15;
...
}
}
Поэтому переопределение имён во вложенных блоках запрещается в некоторых языках программирования, например в C#.
Имя, определённое в некотором блоке, может быть использовано и вне этого блока, если оно квалифицировано, т.е. в месте использования указано, в каком блоке его надо искать. Наиболее типичными примерами являются использование полей структурных объектов:
struct { int x, y; } R, S;
....
R.x = S.y;
В некоторых языках программирования, таких как Паскаль и VisualBasic, имеются присоединяющие операторы, которые являются блоками, делающими доступными в данной точке программы множество имён из блока, определяющего некоторую структуру, что позволяет избежать многократную квалификацию имен полей. Например,
R.x = R.x > R.y? R.x - R.y: R.y - R.x;
в C-подобном синтаксисе может быглядеть так
with (R) { x = x>y? x-y: y-x; }
Отметим, что вложенные присоединяющие операторы не помогают в случае однотипных структур. Например, в операторе
R.x = R.x > S.y? R.x - S.y: R.y - S.x;
с помощью присоединяющих операторов можно избавиться от квалификации либо R, либо S, но не обеих вместе.
Отдельно следует рассмотреть вопрос об использование имен, определённых во внешних библиотеках. Язык C использует для этой цели препроцессор и включаемые файлы. Например, если для инициализации библиотеки library1 используется функция Initialize, то в соответствующем включаемом файле library1.h должна быть строка
extern void Initialize();
и мы можем использовать это имя в своей программе
#include "library1.h"
...
Initialize();
Функция Initialize из библиотеки library1.lib затем подключится к программе во время работы редактора связей.
Пусть теперь нам потребовалось использовать две библиотеки - library1 и library2, и в каждой их них есть своя функция Initialize.
#include "library1.h"
#include "library2.h"
...
Initialize();
Поскольку обе Initialize имеют одинаковую спецификацию, то на уровне трансляции ошибок не произойдёт, но у редактора связей возникнет конфликт. Если спецификации функций Initialize будут различаться, то ошибку выдаст транслятор. Если же библиотеки определяют один и тот же макрос, то о конфликте предупредит препроцессор.
Конечно, хорошо, что конфликт так или иначе будет обнаружен до исполнения программы, пусть даже без очевидного объяснения причины. Однако у нас не остаётся никакой возможности использовать эти библиотеки одновременно. Поэтому создателям библиотек на языке C рекомендуется выдумывать уникальные имена для всех объектов, которые можно использовать извне. Например, в нашем случае создатели первой библиотеки должны были назвать функцию library1Initialize, а второй - library2Initialize. Очевидно, что это, во-первых, отрицательно отражается на читаемости программ и, во-вторых, этот совет бесполезен, если мы не можем повлиять на разработчиков библиотек.
Соглашения об именовании зачастую носят характер обязательной рекомендации: "можно, но категорически нежелательно". Например, "обычным" программистам не рекомендуется начинать идентификатор с двойного подчёркивания, поскольку так именуются системные объекты или макросы: __FILE__, __TIME__ и т.п.
В некоторых языках программирования понятие библиотеки и ее использования выносится на уровень языка. Специальные конструкции реализуют импорт библиотеки. В случае возникновения конфликта при использовании имени, определённого в разных библиотеках, об этом может внятно сообщить транслятор, а программист - воспользоваться явной квалификацией, подобной той, которая используется для структур.
System.Drawing.Color.Aquamarine
Некоторые языки допускают исключения из правила однозначности, позволяя в одном блоке объектам разного сорта иметь одинаковые имена, если они синтаксически не могут появляться в одном и том же контексте. Например, в некоторых диалектах языка SQL можно написать следующий запрос
select select.select
from select, where
where where.select=select.where;
который однозначно трактуется, поскольку
1. запрос должен начинаться с ключевого слова - select, update, delete и т.д. - и поэтому здесь не ожидается имя таблицы или столбца таблицы;
2. после ключевого слова select должно идти выражение, частным случаем которого является select.select, причём здесь перед точкой может быть только имя таблицы, а после - только имя столбца select, который должен быть определён в таблице select;
3. после ключевого слова from должно идти имя таблицы и не может появляться имя колонки и т.д.
Типы данных
Перейдём теперь к объектам, которые используются во время исполнения программы, то есть обрабатываемым данным. Доступ к ним осуществляется через имена, определённые в программе - константы, переменные, параметры функций и т.п. Связь между подобной синтаксической конструкцией и объектом может быть неоднозначной: например, в различные моменты исполнения одной и той же переменной могут соответствовать разные объекты, а может не соответствовать ничего. И наоборот, двум разным именам может соответствовать один и тот же объект. Более того, количество объектов времени исполнения может быть существенно больше, нежели количество определённых в программе имён. Таким образом, существуют анонимные объекты, не имеющие собственного имени и доступ к которым осуществляется только через имена других объектов. Типичным примером являются элементы массивов или указуемые переменные.
Язык программирования предоставляет систему типов данных, которая может зависеть от уровня языка и его ориентации на конкретную область приложения. Для универсального языка программирования, такого как C, типы тоже носят универсальный характер, что приводит к нобходимости решения двух задач: во-первых, отобразить типы данных предметной области в те типы и операции, которые предоставляет язык программирования, и, во-вторых, реализовать типы данных в терминах команд и данных машины - битов, байтов и т.п. Таким образом, при рассмотрении любого типа данных мы должны осветить следующие аспекты:
• моделируемая категория - то, для представления чего этот тип предназначен (например, неотрицательные целые числа);
• синтаксис - способ записи типа данных в программе (например, unsigned int);
• литеральные значения – способ записи констант этого типа в тексте программы (например, 0x123);
• набор операций, которые получают в качестве аргументов или выдают в качестве результатов значения данного типа (например, +, -, *);
• реализация - как отобразить значения данного типа в машинные данные.
Заметим, что в зависимости от уровня рассмотрения не все из перечисленных аспектов представляют интерес. Так, теория абстрактных типов данных отождествляет тип с набором операций, работающих со значениями этого типа, и аксиомами, которые задают свойства операций. При этом даже представление констант может быть сведено к нульместным операциям. С другой стороны, при описании системы типов данных в языках высокого уровня могут оставаться открытыми вопросы реализации.
Нетривиальным является вопрос об эквивалентности типов данных. Достаточно ли, например, чтобы два типа данных реализовывали одинаковый набор операций или следует потребовать, чтобы реализация была одинакова. В некоторых языках на эквивалентность типов влияет то, какие им даны имена. Это представляется разумным, например, в следующем случае
typedef int Apples; /* количество */
typedef int Distance; /* в километрах */
typedef int LocalDistance; /* в метрах */
чтобы не позволять складывать километры с яблоками или перемножать метры на километры. Развивая далее эти соображения, хотелось бы сделать систему типов достаточно выразительной, чтобы сформулировать, например, что скорость, помноженная на время, даёт расстояние.
Но даже если рассматривать только структурную сторону вопроса, т.е. считать, что типы эквивалентны, если они одинаковым образом составлены из одинаковых базовых типов, то проверка этого свойства является сложной алгоритмической проблемой при наличии рекурсивных типов. Например, требуется выяснить, являются ли эквивалентными типы T1, T2 и T3 в следующем примере:
typedef struct S1{int x; struct S2 * next; } *T1;
typedef struct S2{int x; struct S1 * next; } *T2;
typedef struct S3{int x; struct S3 * next; } *T3;
Эта проблема решена всего лишь полтора десятка лет назад сведением к проблеме распознавания эквивалентности детерминированных магазинных автоматов.
Анализ типов
Естественно, что операции должны применяться только к аргументам соответствующего типа. Например, не имеют смысла следующие применения операций/функций:
"При" / "вет"
M[1.2]
sin("Привет")
1.2 % 3.4
и, значит, необходим анализ (или контроль) типов, который бы гарантировал правильность применения операций в смысле соответствия типов.
Ситуация осложняется тем, что выполнение некоторых операций может существенно отличаться в зависимости от типов аргументов. Правильнее будет сказать, что разные операции из разных типов данных могут обозначаться одинаково. Такая зависимость называется перегрузкой операций. Пожалуй, наиболее распространённой перегруженной операцией является присваивание. Если семантика присваивания сводится к пересылке (копировании) данных из одного места в другое, то необходимо знать размер копируемой области, определяемой типами источника и получателя присваивания. Возможно также, что при присваивании происходит нетривиальные преобразования значений из одного типа в другой. Другим распространённым примером перегруженной операции является сложение (+), которая бывает определена для разных видов чисел (например, целых и действительных), строк, указателей и др.:
1 + 2
1.2 + 3.4
"При" + "вет"
p + 7
где p - указатель на объект некоторого типа.
Если речь идёт об определённых в программе функциях и операциях, то перегрузка называется полиморфизмом. Это позволяет использовать одно и то же имя для разных функций, выполняющих по-существу одно и то же действие[15], но для разных способов задания аргументов. Например, в языке C# можно определить три функции рисования прямоугольника
void DrawRectangle(int x, int y, int w, int h);
void DrawRectangle(Location p, Size s);
void DrawRectangle(Rectangle r);
Полиморфизм возникает также, если в языке есть понятие подтипа, который может переопределять некоторые операции родительского типа. Обычно такая возможность появляется в объектно-ориентированных языках программирования, где понятие подтипа реализуется как наследуемый класс. Однако и в языке С можно заметить эти свойства, если рассмотреть множество различных целых (или вещественных) типов данных: char, int, long и т.д.
Перегрузка и полиморфизм существенно повышают понимаемость программ. Той же цели служит неявное приведение типов. Например, в случае, когда первым аргументом сложения является целое, а вторым - вещественнное число, как в случае
1 + 2.0
то исполнитель решает, что нужно выбрать операцию сложения вещественных чисел, предварительно преобразовав первый аргумент из целого в вещественное.
Важной характеристикой языка программирования является то, когда именно выполняется анализ типов - во время трансляции или во время исполнения. В первом случае говорят о статическом, а во втором - о динамическом контроле типов. Существуют и языки, в которых часть контроля типов осуществляется статически, а часть - динамически. Следует отметить, что не существует реальных языков программирования вообще без контроля типов, хотя иногда (неправильно) так говорят, если в языке контроль типов полностью динамический. Даже машинный язык является типизированным. Например, если адрес представляется машинным словом, то перед выполнением команды, извлекающей данные по этому адресу, необходимо проверить, что адрес правильный, поскольку не каждое машинное слово является адресом.
При динамической типизации одна и та же переменная может в разные моменты исполнения хранить значения разных типов. К "достоинствам" динамической типизации можно отнести следующие:
· становится необязательными описание переменных, что особенно "нравится" непрофессиональным программистам;
· если в программе требуются вспомогательные переменные, то можно "сэкономить" их количество, не заводя свои переменные для каждого типа и т.п.
Рассмотрим, следующий пример на языке Visual Basic:
If t > 0
x = 1
y = 2
ElseIf t < 0
x = "1"
y = 2
Else
x = "1"
y = "2"
End If
Print x + "+" + y + "=" + (x + y)
Будем считать, что в языке Basic есть соглашение, что если одним из аргументов операции + является строка, то второй аргумент тоже необходимо преобразовать в строку. Это представляется естественным, если обратить внимание на использование + в операторе Print. Тогда программа при t>0 будет печатать текст
1+2=3
а в остальных случаях (если, конечно, t будет числом, а иначе до печати вообще дело не дойдёт)
1+2=12
Таким образом, динамическая типизация относит обнаружение ошибок несоответствия типов на время исполнения, что во многих случаях противоречит принципу раннего обнаружения ошибок и ведёт к написанию ненадёжных программ. Удобство и экономия усилий, которые даёт динамическая типизация, сводятся на нет усилиями, которые позже потребуются при отладке.
Справедливости ради надо сказать, что бывают ситуации, когда динамическая типизация отражает суть задачи:
· при создании универсальных программ, например, интерпретатора, необходимы переменные, которые хранят значения переменных интерпретируемой программы. А поскольку типы этих значений заранее неизвестны, то переменная в интерпретаторе должна быть некоего универсального типа, и все проверки соответствия будут проводиться во время исполнения;
· если в программе имеется переменная, которая может принимать значения одного из подтипов типа этой переменной, то в процессе выполнения придётся выяснять не переопределена ли некоторая операция для подтипа;
· новые типы могут появляться в процессе выполнения программы, например, при динамической загрузке объектных модулей или динамической генерации кода программы и т.п.
Статическая типизация, напротив, нацелена на то, чтобы выявить ошибки несоответстивия типов как можно раньше. В определённой степени можно считать, что статический анализ типов сродни верификации, если явные указания типов объектов рассматривать как дополнительные условия, которые необходимо доказать или опровергнуть. Помимо этого, статическая типизация обеспечивает лучшее понимание программ. Одним из способов обеспечения этого является строгая типизация, при которой
· для каждой переменной или поля структуры указан тип;
· для операций, функций и процедур указаны типы аргументов и результатов;
· все приведения типов должны быть явными и т.д.
Некоторые языки программирования смягчают эти требования, при условии, что они не противоречат статичности типизации: если типы объектов так или иначе могут быть выведены из контектста их использования. Это обеспечивает возможность проверки корректности применения всех операций.
Классификация типов
Перейдём к рассмотрению наиболее распространённых типов данных. Для того, чтобы сделать рассуждения о типах более лаконичными, введём их классификацию: мы сможем определять множество свойств типа просто отнесением его к некоторому классу.
Прежде всего все типы можно разбить на предопределённые, т.е. предоставляемые самим языком программирования, и определяемые, т.е. описанные в программе.
С другой стороны, все типы можно разбить на простые, т.е. неделимые с точки зрения языка, и структурированные – предназначенные для агрегации компонентов.
Все типы (по крайней мере в тех языках, которые мы будем рассматривать) имеют операции присваивания, сравнение на равенство и неравенство.
Если кроме этого, тип предоставляет операции, связанные с линейным порядком (<, <=, >, >=), то тип называется упорядоченным.
Перечеслимым (или интегральным) называются тип, множество значений которого отображается в диапазон целых чисел. Любой перечеслимый тип, естественно, является упорядоченным.
Арифметическим называется упорядоченный тип, предназначенный для работы с числами, т.е предоставляющий арифметические операции сложения, умножения, деления и т.п.
Поскольку язык C в силу своей машинной ориентации не делает различия между некоторыми существенно разными предопределёнными типами, считая наиболее важным то, сколько места в памяти они занимают, мы начнём с рассмотрения базовых типов на примере языка Паскаль и обсуждения вариаций на тему того, какими эти типы могли бы быть или бывают в других языках программирования.
Логические
Логический тип предназначен для представления булевых значений. Традиционно тип обозначается в языке Паскаль зарезервированным словом boolean. Литеральными константами являются true и false. Над логическим определены обычные операции: and - конъюнкция, or - дизъюнкция, not - отрицание, xor - взаимное исключение, которое по-существу совпадается с равенством. Поскольку тип является перечислимым (true=1, false=0), то для него определены отношения порядка (true>false), которые можно трактовать как импликацию, например,
a >= b
означает, что из a следует b.
Вариации.
Для представления значения логического типа достаточно одного бита, поскольку в этом типе всего два значения. Потенциально, с помощью одного байта можно было бы представить 8 логических значений. Однако, здесь возникает противоречие между компактностью представления и временем доступа - выборка одного бита из байта или слова может потребовать несколько дополнительных команд. Поэтому обычно на представление логического типа отводится по крайней мере один байт, а вопросы упаковки решаются отдельно.
Символы
Символьный тип предназначен для представления букв, цифр и других символов, появляющихся в текстах на компьютерных и естественных языках. Тип обозначается в языке Паскаль словом char. Литеральные символьные константы представляются заключёнными в апострофы (одинарные кавычки) - 'A', '1', '*', '''. Тип является интегральным (а значит и упорядоченным) - взаимно-однозначное соответствие с диапазоном 0..255 реализуется стандартными операциями chr и ord.
Вариации.
Множество представимых символов и их коды описаны стандартом ASCII - американским стандартным кодом для обмена информацией. Изначально кодировка была семибитной (128 символов), достаточной для представления букв, цифр, специальных и управляющих символов. К последним относятся такие символы как перевод строки, табуляция, возврат на один символ назад, перевод страницы и др. Структура кода позволяет эффективно с помощью битовых операций проверять, является ли символ буквой или цифрой и т.п. Проблемы начились с созданием национальных версий, когда потребовалось добавить новые символы, скажем, из французского или шведского алфавита. Для этого предлагалось поставить их на место редко используемых символов, таких как @, {, }. Однако, для алфавитов, которые вводят большое количество новых символов - кириллицы, греческого, иврита и др. - приходится расширить диапазон до 256.
Если же добавляемый алфавит совсем большой, как, например, японская катакана, то по крайней мере некоторые символы символы будут представляться двумя байтами. Чтобы при этом "обычные" английские тексты представлялись как и раньше, предлагалось использовать управляющие символы SI (shift-in) и SO (shift-out) для временного перехода к двухбайтой кодировке и обратно.
Но и это не является полным решением проблемы, если в тексте содержатся символы из нескольких алфавитов. Необходима кодировка, которая включает символы из всех алфавитов одновременно. Принципы организации такой кодировки заложены в Unicode, которая в настоящий момент перечисляет более 100 тысяч символов[16]. Собственно представление этих символов может быть различным и определяться форматом записи. Например, UTF-32 отводит на каждый символ ровно по 4 байта, а UTF-8 - от одного до четырё байтов, но при этом первые 128 кодов совпадают с ASCII, что делает UTF-8 предпочтительнее с точки зрения обратной совместимости.
Некоторые современные языки программирования предоставляют специальные символьные типы для различных кодировок, другие - изначально полагают, что символьный тип моделирует Unicode.
Целые числа
Целый тип моделирует целые числа и обозначается в языке Паскаль словом integer. Запись целых чисел состоит из десятичных цифр и, возможно, минуса в начале: 1, -2, 123. Паскаль предоставляет обычный набор арифметических операций над целыми: +, *, -, div, mod и др. Слово div обозначает деление, поскольку привычная косая черта "/" задействована для вещественных чисел.
Вариации.
Основная проблема при моделировании целых чисел состоит в том, что их бесконечно много. В независмости о того, сколько памяти мы выделим для хранения целого числа, она так или иначе будет конечна, поскольку конечна память всего компьютера. Поэтому обычно реализуются не все целые числа, а некоторый диапазон, зависящий от размера памяти, отводимого для одного числа. Например, если целые числа представлюятся машинным словом в 16 бит, то реализуется диапазон -32768..32767, чтобы положительных и отрицательных чисел было примерно одинаково. Однако, во многих случаях наверняка известно, что число будет неотрицательным и поэтому требуется беззнаковый целый тип, в котором мы смогли бы с помощью тех же 16 бит представить числа в диапазоне 0..65535.
Рассмотрим более детально представление целых чисел и начнём с беззнаковых, как более простых в этом смысле. Пусть на представление числа отведено n разрядов и bn -1 bn -2
|
|