 2020-04-07
2020-04-07 139
139Тип структуры и объединения в языке C имеют почти одинаковый синтаксис, который задаёт перечисление полей, описание которых в свою очередь практически совпадает с описанием переменных:
| тип_cтруктура: | 
|
| описание: | 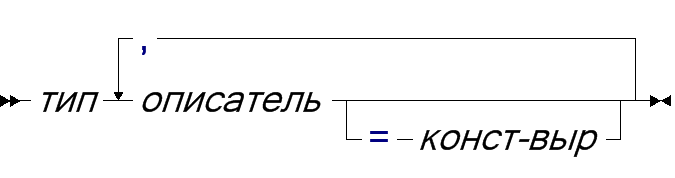
|
| тип: | 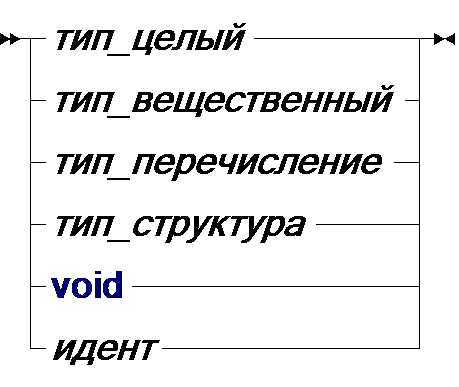
|
| описатель: | 
|
Последняя альтернатива в диаграмме тип соответствует имени определяемого типа, а в диаграмме описатель - типу функции, которые обсуждаются ниже.
Синтаксическая категория тип не покрывает все возможные типы языка C: указатели, массивы и функции появляются в категории описатель. Это иногда приводит к неудобствам: например, не всякий тип можно непосредственно указать как аргумент операции sizeof и для этого приходится дополнительно описывать либо переменные, либо именованные типы. С другой стороны, в таком определении есть свои достоинства: запись описателя схожа со структурой применения операций разыменования и выборки компоненты по индексу при использовании. Это даёт возможность совместить компактность записи и понимаемость даже для сложноустроенных типов:
| Описание | Использование | Комментарий |
| int (*p)[100]; | (*p)[i] | Указатель на массив целых |
| int * (a[100]); | * (a[i]) | Массив из указателей на целые |
| enum WeekDay ** ((*A)[][100]); | **((*A)[i][j]) | Указатель на массив из массивов из указателей на указатели на перечисление WeekDay |
| long *q, n, m = 5; | *q, n, m | Указатель на целое, целое и целое, равное 5 |
Синтаксис описания типа, который задаёт ему имя, отличается от описания переменной только служебным словом typedef в начале:
| описание_типа: | 
|
Как и в описании переменной, в одной конструкции описания типа может быть определено несколько разных типов. Например,
typedef float Matrix[N][N], Vector[N];
Matrix A;
Vector v;
Основной как для типа струкуры, так и для типа записи является постфиксная операция выборки поля, которая обозначается точкой, за которой следует имя поля. Для структур имеются литеральные значения, которые перечисляют значения полей в порядке их появления в описании структуры:
typedef struct { flaot re, im; } complex;
complex c1= {-1, 0}, c2 = {3.14,2.78}, c;
c.re = c1.re * c2.re - c1.im * c2.im;
c.im = c1.re * c2.im + c1.im * c2.re;
При этом в записи значения структур допускаются не только константы, что делает это особой формой выражения:
c =
{
c1.re * c2.re - c1.im * c2.im,
c1.re * c2.im + c1.im * c2.re
};
Различные струкутры могут иметь поля одним и тем же именем. В этом смысле операция выборки является перегуруженной - нужная операция однозначно определяется типом аргумента.
Очень часто используется комбинация из последовательности операций разыменования указателя на структуру с последующей выборкой поля, как, например, (*p).next. Для этого случая используется сокращённая форма: лексема ->, за которой следует имя поля. То есть последнее выражение полностью эквивалентно p->next.
Тип объединения реализует простое наложение альтернатив без какого-либо контроля того, какая именно альтернатива является актуальной. Как мы уже говорили, это является ещё одной "дырой" в контроле типов. То есть считается вполне законной последовательность действий
union
{
unsigned long l;
unsigned char c[4];
} b4;
b4.l = 0xAABBCCDD;
b4.c[1] = ‘A’;
в результате значение поля l станет равным 0xAA41CCDD.
Поэтому для "корректного" использования объедения используется его сочетание со структурой, в которой одно из полей определяет текущую альтернативу. Кроме того, в отличии от Паскаль, в языке C альтернатива не может содержать несколько полей, и поэтому полем объединения зачастую тоже является структура. Далее мы будем использовать следующий пример - структуру, описывающую вершину в дереве абстрактного синтаксиса в модельном языке выражений:
enum ExprCode
{
EC_VALUE,
EC_VAR,
EC_UNOP,
EC_BINOP
};
struct Expr {
int tag;
enum ExprCode code;
union {
float value;
char name[8];
struct {
char op;
struct Expr * arg;
} unop;
struct {
char op;
struct Expr *left, *right;
} binop;
} choice;
};
Здесь в каждой вершине имеется поле tag, хранящее вспомогательную информацию. Поле code определяет тип вершины, в зависимости от которого интерпретируются остальная информация:
| Значение tag | Тип вершины | Поле в объединении choice |
| EC_VALUE | Вещественное число | value - значение числа |
| EC_VAR | Переменная | name - имя переменной |
| EC_UNOP | Применение унарной операции | unop, где · op - код операции; · arg - ссылка на вершину-аргумент. |
| EC_BINOP | Применение бинарной операции | binop, где · op - код операции; · left и right - ссылка на левое и правое подвыражение, соответственно. |
Теперь, если переменная e описана как
struct Expr * e;
то доступ к левому подвыражению бинарной операции будет иметь вид
e->choice.binop.right
но при этом на программисте лежит ответственность, что перед этим проверено, что значение e->code равно EC_BINOP.
Присваивания
Целью присваивания является изменение значение некоторого объекта. В языке С присваивание обозначается символом равенства "=" и рассматривается как специальная операция, первый аргумент которой называется получателем и определяет изменяемую переменную, а второй - источником, вычисляющим присваиваемое значение. То есть, в отличие от обычных операций, присваивание вычисляет не значение, задаваемое получателем, а только его адрес.
Типы получателя и источника должны быть согласованы. Если оба являются арифметическими типами, то происходит преобразование результата вычисления источника к типу получателя. При этом может происходить потеря точности. Например, при
int x;
x = 1.6;
произойдёт округление вещественного значения за счёт отбрасывания дробной части и х получит значение 1. Как уже говорилось ранее, потеря точности может происходить и в других случаях, преобразовании беззнаковых в знаковые, длинных целых в вещественные и т.п. Транслятор по мере возможности в таких случаях выдаёт предупреждение.
Массивы, поскольку они являются константными указателями, присваивать нельзя, т.е.
int a[3], b[3];
a = b;
недопустимо.
С другой стороны, струкутры присваивать можно, даже если в них и имеются поля-массивы. Например,
struct
{
int x;
char y;
int m[3];
} a, b;
a = b;
скопирует содержимое структуры b, то есть отрезок памяти размера sizeof(b), включающий в том числе и все элементы поля m, в структуру a.
Результатом выполнения операции присваивания является присвоенное значение. Тот факт, что присваивание в языке C является выражением, имеет как плюсы, так и минусы. К достоинствам можно отнести то, что иногда это позволяет сократить запись. Например, если необходимо присвоить одно и то же значение нескольким переменным, то его можно указать только один раз:
x = y = z = 1.6;
Другой типичный случай возникает, когда результат присваивания нужно тут же использовать для других вычислений, как в
z = (x = 3) + (y = 4);
где x, y и z получат значения 3, 4 и 7 соответственно.
Существенным недостатком такого подхода является то, что наличие побочных эффектов в выражениях может приводить к неожиданным результатам. Рассмотрим, например, cледующий фрагмент:
float A[N];
int i=0, j=0;
A[i+j] = (i=1) + (j=i+1);
Естественно предположить, что аргументы сложения вычисляются слева направо, а источник присваивания вычисляется раньше получателя. В этом случае A[3] получит значение 3. Однако, сделанное предположение неверно и может оказаться, что в данном конкретном случае транслятор реализует это присваивание как
float *t = &(A[i+j]);
j = i+1;
i = 1;
*t = i+j;
в результате чего A[0] получит значение 2. Очевидно, что возможны и другие варианты.
В языке C есть несколько видов присваиваний, совмещённых с выполнением других операций. Так следующие два присваивания эквивалентны
x = x + 2;
x += 2;
Сокращённая форма записи несомненно повышает наглядность и лучше отражает смысл операции: увеличить x на 2. Помимо операции += допустимы также -=, *=, /=, %=, &=, |=, ^=, <<=, >>=, однако, за <= и >= уже зарезервирован другой смысл - сравнение, а &&= и ||= недопустимы ввиду специфичности семантики псевдо-операций && и ||.
Если получатель присваивания является сложным выражением, то в случае совмещенного присваивания он будет вычисляться только один раз, что делает выполнение более эффективным. Однако, это также может существенно изменить семантику по сравнению с несовмещённым присваиванием, как в случае
M[i+=1] += 2;
что, очевидно, не эквивалентно
M[i=i+1] = M[i=i+1] + 2;
хотя бы потому, что i увеличится два раза, а не один.
Среди совмещённых присваиваний особенно часто используются увеличение и уменьшение на 1, как
x += 1;
x -= 1;
Для этих случаев в языке С предусмотрены специальные унарные операции - инкремента ++ и декремента --. Таким образом предыдущий фрагмент эквиваленен
x++;
x--;
Поскольку точно также как простое или совмещенное присваивание применение инкремента или декремента является выражением, то надо определить, какое значение оно вычисляет. Если следовать аналогии с присваиванием, то следует вернуть новое (т.е. присвоенное) значение. Это оказывается не всегда удобно. Вспомим, например, функцию копирования строки, где основной цикл имел вид
while (*p++ = *q++);
Здесь замысел состоял в том, чтобы присвоить то, куда указывает q, туда, куда указывает p, а затем уже сдвинуть значения p и q к следующим символам. То есть цикл эквивалентен
while (*p = *q)
{
p++;
q++;
}
причём неважно в каком порядке изменяются p и q. Равенство в условии цикла означает не сравнение на равенство, а присваивание, значением которого будет текущее значение q, а само присваивание будет выполнено когда-то позже, но до того, как изменятся q и p. Это позволяет записать тот же цикл как
while (*q)
{
*p = *q;
p++;
q++;
}
Осталось заметить, что *q в условии истинно, когда оно не равно нулю, то есть нагляднее было бы записать его как *q!= '\0'. Конечно, можно считать, что выбор между разными формами записи этого цикла - дело вкуса. Аргументами в пользу короткой записи является тот факт, что в ходе преобразования мы внесли дополнительные ограничения на порядок выполнения p++ и q++, а также ввели лишнюю операцию!=. Однако, эти аргументы становятся неубедительными, учитывая, что современные трансляторы достаточно умные, чтобы разобраться с этими проблемами. Так что преимущество в данном случае должен иметь наиболее понятный с точки зрения программиста вариант, на что исходный код вряд ли может претендовать.
Вернёмся к операции инкремента. В языке C имеется как префиксная, так и постфиксная форма этой операции:
++x
x++
соответственно. Постфиксная форма выдаёт исходное значение переменной, а префиксная - новое, что семантически эквивалентно.
x += 1
(t = x, x += 1, t)
где t - вспомогательная переменая. В случае, если результат инкремента не используется, то две эти формы эквивалентны. То же справедливо и для операции декремента --.
Нотационная путаница
Вероятно, стремление к краткости записи является причиной того, что одни и те же символы используются в формировании разных лексем. Это приводит к тому, что "гибкость" синтаксиса оборачивается его неустойчивостью.
Использование символа равенства "=" для обозначения присваивания противоречит естественному, привычному всем со школьного курса смыслу. Те соображения, что присваивания в программах встречаются чаще, чем сравнение на равенство, и что так было принято в языке Фортран, вряд ли можно считать достаточным обоснованием. В языках, происходящих от языка Алгол для присваивания используется лексема :=, а в языках Кобол и Basic - вообще многословные операторы
MOVE X TO Y
LET Y = X
что уже не спутать с проверкой на равенство, но это уже явный перебор.
Возможность использовать присваивание в качестве выражения и отсутствие в языке явного типа логического и битовых шкал не позволяет своевременно диагностировать ошибки, связанные с некорректным применением операций &, &&, |, ||, <=, <<= и т.п. Рассмотрим, например, выражение
x=2 & y>0
которое естественно воспринимается как конъюнкция двух условий x=2 и y>0, что истинно при x=2 и y=1. Без каких-либо предупреждений данное выражение будет воспринятно как
x = ((2 & y) > 0)
что ложно, причём x получит новое значение 0. Желаемый результат задаётся внешне очень похожим выражением
x == 2 && y>0
Стремление к краткости иногда приводит к коду, похожему на криптограмму. В языке C допустимы, например, выражения
a++ + ++b
a++ + +b
a+ ++b
a+ + +b
причём все имеют разный смысл.
Управление
Для того, чтобы действия в программе выполнялись в нужном порядке, используется управление. В простейшем случае, как, например, в машине Тьюринга, для каждого команды указывается следующая, выбор которой может зависеть от обрабатываемых данных. Такой чисто императивный способ управления является во многих случаях избыточно жестким. Ниже мы рассмотрим несколько видов управления, характерных для императивных языков программирования:
• выражения, главной целью которых является вычисление значений, а порядок исполнения определяется зависимостью по данным. Например, для того, чтобы вычислить выражение (x+y)*(x-y) не важно в каком порядке будут вычислены аргументы умножения - главное, чтобы оба они были вычислены до собственно применения этой операции. В таких случаях язык задаёт частичный порядок на некотором подмножестве действий[23];
• операторы, целью которых является изменение состояние памяти. Последовательность выполнения операторов задаётся императивно, т.е. следующий за данным оператор задаётся либо однозначно, либо выбирается из двух или более альтернатив;
• процедуры и функции позволяют определить совокупность действий, изменяющих состояние памяти и/или вырабатывающих некоторое значение, и исполнять её многократно, возможно, меняя некоторые параметры;
• обработка исключительных ситуаций, перехватывающая управление в случае, если вдруг где-то произошло событие - деление на ноль, исчерпание памяти, выход за границы индексов и т.п.
Этот перечень не охватывает все возможные способы организации управления. За рамками рассмотрения остаются параллельные, потоковые, событийно-управляемые вычисления, вычисления, основанные на сопоставлении с образцом, логическом выводе и т.п., не говоря уже про нейронные сети и квантовые вычисления.
Выражения
Выражения в языке C строятся из
• имён переменных;
• литеральных значений и имён констант;
• применения операций;
• разыменования, взятия адреса, выборки компонент массивов и структур;
• явного приведения типа и вычисления размера типа;
• группирования вычислений скобками;
• вызова функций и процедур;
• условного и последовательного выражений.
Синтаксическая диаграмма, которая сводит воедино все эти конструкции, имеет следующий вид:
| выр: | 
|
Очевидно, что описанный синтаксис существенно сложнее, чем тот модельный язык выражений, который мы использовали в качестве примера, даже учитывая то, что в нём не учитывается приоритет операций, который также имеет гораздо больше уровней. В порядке возрастания приоритетов можно все операции можно разбить на 15 групп - чем выше приоритет, тем сильнее операция связывает аргументы и тем раньше она выполняется:
| 1 | () [] ->. ++ -- | Вызов функции, выбор поля или компоненты массива, постфиксные инкремент и декремент |
| 2 | ! ~ - ++ -- + * & (тип) sizeof | Унарные, префиксные инкремент и декремент, приведение типа, sizeof |
| 3 | * / % | Умножение |
| 4 | + - | Сложение |
| 5 | << >> | Битовый сдвиг |
| 6 | < <= > >= | Сравнения |
| 7 | ==!= | Равенство |
| 8 | & | Побитовое AND |
| 9 | ^ | Побитовое XOR |
| 10 | | | Побитовое OR |
| 11 | && | Логическое AND |
| 12 | || | Логическое OR |
| 13 | ?: | Условное выражение |
| 14 | = += -= *= /= %= &= |= ^= <<= >>= | Присваивания |
| 15 | , | Последовательное выполнение |
Приоритет операций в разных языках программирования может отличаться и не всегда соответствует интуиции. Например, следующие выражения
a = b && c
a & b == c
*a[i]++
a & 2 << 3
будут соответственно трактоваться как
a = (b && c)
a & (b == c)
*(a[i]++)
a & (2 << 3)
Простое правило, которому надо следовать, - если у пишущего программу возникают сомнения в том, приоритет какой операции выше, то очень вероятно, что ровно такие же сомнения возникнут и у читающего программу. Поэтому в таких случаях рекомендуется использоваться скобки, даже если их можно опустить.
По-существу, среди всех возможных допустимых выражений мы не рассмотрели только вызовы функций, условные и последовательные выражения. Функции мы рассмотрим отдельно ниже. Что же касается условных и последовательных выражений, то они дублируют те возможности, которые реализуются на уровне операторов.
Условное выражение имеет вид
условие? то-часть: иначе-часть
Хотя условное выражение иногда и рассматривается как применение тернарной операции, оно отличается тем, что не требует вычисления всех составных частей до примения операции: при истинности условия вычисляется значение то-части, в противном случае - иначе-части, и полученное значение является значением всего выражения,.
Естественно, для того, чтобы можно было определить тип условного выражения, необходимо, чтобы тип одной из альтернатив можно было привести к типу другой. Так, например,
n > 0? 1: &x
недопустимо, а значением
n > 0? 1: 1.0
будет вещественное значение 1.0 вне зависимости от истинности условия.
Логические связки && и || также по сути являются условными выражениями и реализуют так называемые конъюнкцию и дизъюнкцию по МакКарти (John McCarthy). Второй аргумент вычисляется только в случае, если первый оказался истинным и ложным, соответственно. Формально
A && B
A || B
эквивалентны соответственно
A? B: 0
A? 1: B
Это позволяет использовать && как охраняющие условия. Например,
(x!=0) && (1/x > 0)
(i >=0 && i < N) && (A[i]!= 0)
не будут приводить к делению на 0 и выходу за границы индексов, что произошло бы, если бы вычислялись все подвыражения.
Управление в последовательном выражении
e 1, e 2,..., e n
также отличается от обычного применения операций, поскольку оно требует, чтобы все "аргументы" вычислялись слева направо. Результатом всего выражения является значение последнего - e n, а результаты всех предыдущих игнорируются. Таким образом, использование последовательного выражения осмысленно только, если все e 1, e 2,..., e n-1 имеют побочные эффекты, как например,
c = (a=3, b=2+a, a+b);
что эквивалентно
a = 3;
b = 2 + a;
c = a+b;
но не эквивалентно
с = (a = 3) + (b = 2+a);
Формально язык не требует наличия побочных эффектов, что может приводить к неожиданным ошибкам[24]. Например,
A[i,j] = i+j
воспринимается как присваивание элементу двумерного массива, хотя на самом деле эквивалентно
A[j] = i+j
Операторы
Управление на уровне операторов будем описывать методом раскрутки, то есть от простого к сложному. Набор управляющих конструкций в языке C весьма небольшой, как показывает следующая синтаксическая диаграмма:
| оператор: | 
|
Начнём с первых двух альтернатив, которых, вообще говоря, вполне достаточно для реализации любой последовательности действий.








