2020-04-07
2020-04-07 174
174Целые и символы
В языке С имеется несколько целочисленных типов, отличающихся размером и тем, допускают ли они отрицательные значения. Синтаксис целочисленного типа задаётся следующей диаграммой:
| тип_ целый: | 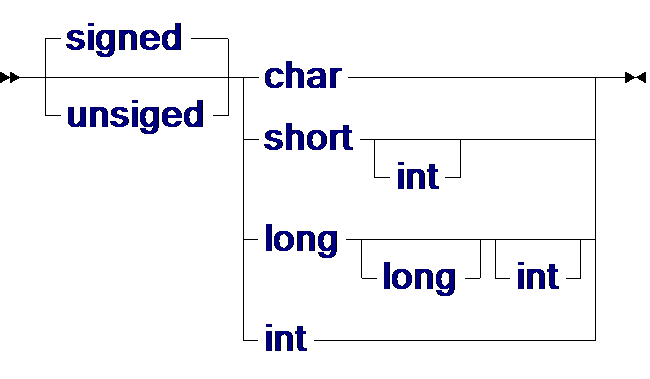
|
Какие имеено размеры соответствуют типам, в значительной степени зависит от конкретной реализации, что потенциально может сказаться на переносимости программ. Следующая таблица определяет минимальные размеры для разных типов в предположении, что размер байта равен 8 бит:
| Тип | Размер (байт) | Со знаком (signed) | Без знака (unsigned) |
| char | 1 | [−127, +127] | [0, 255] |
| short | 2 | [−32767, +32767] | [0, +65535] |
| long int | 4 | [−2 147 483 648, +2 147 483 647] | [0, +4 294 967 295] |
| long long int | 8 | [−9 223 372 036 854 775 808, +9 223 372 036 854 775 807] | [0, 18 446 744 073 709 551 615] |
Тип int без спецификатора short или long опять же в зависимости от реализации может обозначать либо короткое, либо длинное целое число.
Изображение литеральных констант задаётся следующей синтаксической диаграммой:
| целое: | 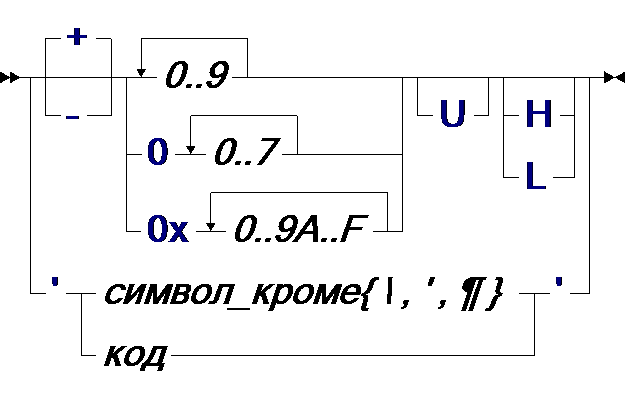
|
| код: | 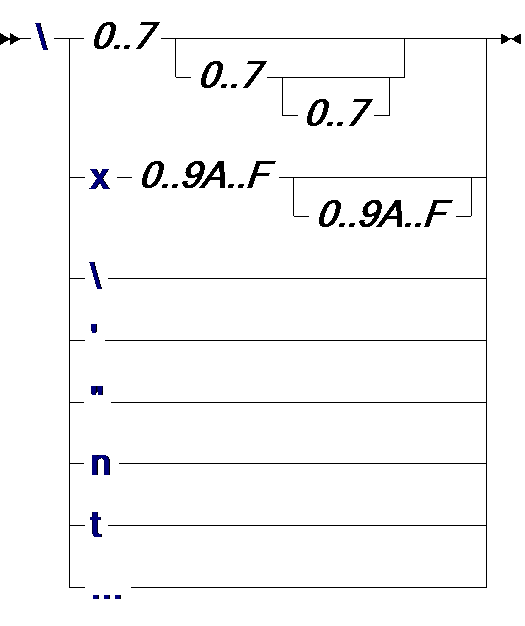
|
Согласно этой диаграмме запись целого числа может быть основана на десятичной, восьмеричной или шестнадцатеричной системе счисления. В конце числа можно указать является ли оно беззнаковым U, коротким H или длинным L.
Кроме того, поскольку символьный тип char тоже рассматривается как целый, и язык не делает разницы между символом и его кодом, то изображение символа в апострофах (одинарных кавычках) тоже является целым числом. Обратная косая черта \ в изображении символа используется для задания символа по его восьмеричному или шестнадцатеричному коду, либо для представления апострофа, кавычки и распространённых спецсимволов - перевода строки, табуляции и т.п.
Такой подход делает возможной символьную арифметику. Например, i-ая буква латинского алфавита может быть найдена как
'A' + i - 1
что, конечно, компактнее, чем аналогичное выражение в Паскаль
chr(ord('A') + i – 1)
Однако, это же делает легальными и слабо осмысленные выражения типа
('A' + 'B'*'2') / '3'
Логические
В языке С нет логического типа в явном виде. Вместо этого язык считает, что все значения, в представлении которых есть ненулевых биты, являются истинными. То же правило распространяется и на вещественные числа и указатели. Таким образом, среди целых чисел, в предположении использования дополнительного кода, единственным ложным значением является ноль.
В языке имеется несколько операций, которые работают над значениями как над логическими и выдают либо 0, либо 1
· && - конъюнкция
· || - дизъюнкция
·! - отрицание
На самом деле, конъюнкция и дизъюнкция - не совсем обычные операции, поскольку конъюнкция (дизъюнкция) в случае ложности (истинности) первого аргумента не пытается вычислять второй. В этом смысле эти операции скорее являются разновидностью условного выполнения, о чём мы ещё поговорим далее.
Примеры логических выражений:
!1 || 'A' && 0x12L
истинно, поскольку истино!1 и && имеет больший приоритет, чем ||, а
‘\0’ || (‘A’ == ‘B’)
– ложно, поскольку и '\0', и 'A'=='B' - ложны.
Битовые шкалы
Вместо теоретико-множественных операций язык C предлагает использовать побитовые операции над целыми числами, а точнее - над их представлениями:
• & - побитовая конъюнкция;
• | - побитовая дизъюнкция;
• ^ - побитовый xor;
• ~ - побитовое отрицание;
• <<, >> - бинарные операции, сдвигающие битовую шкалу, представляющую первый аргумент, влево и вправо соответственно на количество разрядов, задаваемых вторым аргументом.
Например, тип set of 0..31 языка Паскаль может быть реализован с помощью одного длинного целого числа unsigned long int так, что если S1 и S2 - множества, а x и y - числа в пределах от 0 до 31, причём y>=x, то
| Паскаль | C |
| S1 + S2 | S1 | S2 |
| S1 * S2 | S1 & S2 |
| S1 - S2 | S1 & ~S2 |
| x in S | (1<<x) & S |
| S1 <= S2 | S1 & S2 == S1 |
| [x..y] | ((1<<(y–x+1))-1) << x |
Очевидно, что запись на Паскаль значительно нагляднее, хотя, возможно, язык C и обладает большей гибкостью.
Типичное использование множеств состоит в упаковке нескольких разнородных логических значений. Например, можно определить несколько характеристик человека - мужчина, вегетарианец, лысый, студент и т.п., закрепив за каждой из них некоторый бит[19]:
#define FLAG_MALE 1
#define FLAG_VEGETERIAN 2
#define FLAG_BALD 4
#define FLAG_STUDENT 8
Тогда если x - битовая шкала, представляющая набор таких характеристик для некоторого человека, то условия
x & (FLAG_MALE|FLAG_BALD)
x & FLAG_VEGETERIAN & FLAG_STUDENT
будут истинны для "мужчин или лысых" и "студентов-вегетарианцев", соответственно.
Операция сдвига зачастую используются для более эффективной реализации умножения, деления нацело и остатка от деления на степень числа 2. Пусть например при m = 2n и целом x
x * m = x << n
x / m = x >> n
x % m = x & (m-1)
В случае деления нужно отдельно рассмотреть случай отрицательного x. Для того, чтобы равенство имело место, необходимо обеспечить распространение знакового бита. Например, при восьмиразрядном знаковом целом
1 0000100 = -128+4 = -124
1 0000100 >> 2 = 1 11 00001 = -128 + 64 + 32 + 1 = -31 = -124/4
Перечисления
Тип перечисления в языке С служит для содержательной группировки целочисленных констант и имеет следующий синтаксис:
| тип_перечисление: | 
|
Как видно, в описании элемента типа перечисления можно указать, а можно и не указывать, конкретное целочисленное значение, например,
enum StreetColor
{
Red,
Green,
Blue
};
enum WeekDay
{
Mon=1,
Tue,
Wed,
Thu,
Fri,
Sat,
Sun
};
enum PersonFlag
{
Flag_Male = 01,
Flag_Vegeterian = 02,
Flag_Bald = 04,
Flag_Student = 010
};
Таким образом, значения разумно задавать либо всем элементам, либо только первому, что означает начальное значение (по умолчанию равное нулю), а все последующие увеличиваются на 1.
Как уже говорилось, все элементы перечисления в языке C - просто целые числа, и поэтому будет легальным и равным 3 выражение
(Flag_Bald - Tue) | Green
хотя смысла в нём нет, и скорее всего такое выражение ошибочно.
Вещественные числа
Язык C предоставляет три вещественных типа: 32-разрядный float, 64-разрядный double и long double, определяемых стандартом IEEE 754, о котором говорилось выше:
| тип_вещественный: | 
|
Синтаксис вещественных констант задаётся следующей диаграммой:
| вещественное: | 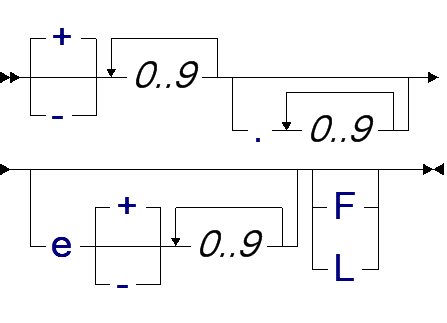
|
где, подобно записи целых чисел, в конце можно указать тип константы: F - float, L - double.
Тип long double используется для вычислений повышенной точности и в зависимости от реализации быть 80-разрядным, либо четырёхбайтным (128 разрядов), либо просто совпадать с double.
Заметим, что имеется лексическая неоднозначность между целыми и вещественными константами. Формально, число +99 подходит под определение вещественной константы, но будет трактоваться как целое. Кроме того, квалификатор L может появляться как при записи целых, так и при записи вещественных:
· 12000L – long int
· 12e+3L – double
· 12000.0L – double
Приведение типов
Разнообразие арифметических типов приводит к необходимости преобразовывать значения одного типа в другой. Отметим, что это может быть достаточно нетривиальным действием, поскольку, скажем, представление вещественных существенно отличается от целых. Например, если арифметическая операция применяется к аргументам разных типов, то аргумент "меньшего" типа неявно преобразуется к большему. Для этого типы упорядочиваются по рангу, согласно следующему списку в порядке убывания:
• long double
• double
• float
• long
• int
• char
Заметим, что преобразование из целых в вещественные (например, long в doublе), может приводить к потере точности, поскольку, как мы уже отмечали, вещественные числа являются "разреженными" при больших абсолютных величинах.
Кроме этого, в зависимости от ситуации, происходит преобразование из беззнаковых целых в знаковые или наоборот. В большинстве случаев, оно определяется естественным образом, хотя в некоторых случаях, может приводить к неожиданным результатам. Так, при
unisgned short s1 = 5;
unsigned short s2 = 10;
unsigned int i1 = 5;
unsigned int i2 = 10;
значение s1-s2 будет равно -5, а значение i1-i2 - положительным числом[20]. Подробности можно узнать в описании стандарта языка C.
Для явного преобразования типов результирующий тип указывается в скобках перед выражением, вычисляющим исходное значение. Например, при вычислении
(int) (3 + 0.5)
сначала 3 приведётся к типу float для того, чтобы выполнить сложении с 0.5, а затем дробная часть отбросится при явном приведении и мы снова получим целое число 3. Аналогичное (но неявное) преобразование выполняется при присваивании, инициализации и т.п., если тип источника "больше", чем тип получателя, как в
unsigned char x = 256;
где начальным значением x будет 0.
Указатели
В языке C нет отдельной синтаксической конструкции для типа указателя, который может появляться лишь в описании переменных, параметров или типов. Так, например, конструкция
int * p, **q, i, j;
описывает переменную p типа указатель на целый, переменную q типа указатель на указатель на целый и две переменные i и j целого типа. Пример переменной q показывает, что сами указатели являются равноправными объектами, на которые можно устанавливать ссылки. Зачем это может быть нужно, мы покажем позже.
Машинное представление указателя зависит от устройства памяти. Грубо говоря, если мы занумеруем все адресуемые ячейки памяти, то реализацией указателя может быть просто целое число - номер ячейки, на которую он ссылается. Тогда, если для представления указателя отводится 32 бита (4 байта), то он может указывать на 4,294,967,296 различные ячейки. Если в качестве адресуемой ячейки выступает байт, то размер адресуемой памяти будет 4 Гб.
В любом типе указателя имеется выделенное значение – пустой указатель NULL. Про него известно, что он не совпадается с адресом ни одного описанного в програме или созданного в процессе исполненния объекта. На самом деле константа NULL определена как макрос:
#define NULL (void*) 0
и поэтому указатели можно, хотя и не рекомендуется использовать как логические значения.
Помимо присваивания, сравнения на равенство и неравенство, двумя основными операциями, связанными с указателями, являются взятие адреса (*) и разыменование (&). Рассмотрим их на cледующем примере:
int i,j;
int *p;
p = &i;
*p = 2;
j = *p+1;
p = &j;
*p = *p+1;
Первые две строки описывают три переменные: две целого типа и одну типа указатель на целое. Оператор
p = &i;
берёт адрес переменной i и присваивает его в указатель p. Следующий оператор
*p = 2;
использует операцию разыменования для того, чтобы по указателю p «добраться» до переменной i. Таким образом, в этой точке программы *p и i означают одну и ту же ячейку памяти, которой присваивается значение 2. В результате получается следующее состояние памяти:
| p |
| i |
| j |
| 2 |
где стрелка, ведущая изнутри ячейки, означает, что в ней хранится адрес той ячейки, к которой ведёт стрелка.
Следующий оператор
j = *p + 1;
извлекает из ячейки i через указатель p значение 2, прибавляет к ней 1 и помещает результат 3 в ячейку j. Далее,
p = &j;
«перекидывает» стрелку из p на ячейку j: с этого места *p будет означать уже не i, а j. Наконец, оператор
*p = *p +1;
увеличивает значение переменной j на единицу, приводя к следующему состоянию пямяти:
| p |
| i |
| j |
| 4 |
| 2 |
В предположении, что адреса являются целыми числами, означающими номера ячеек памяти, на указателях можно установить линейный порядок и допустить выполнение над ними арифметических операций - сложения, вычитания и сравнения. Такого рода вычисления называются в языке C адресной арифметикой. При этом предполагается, что указатель ссылается на один из элементов в последовательности однотипных объектов, и, например, увеличение (уменьшение) указателя на единицу даёт ссылку на следующий (предыдущий) объект. Таким образом, измерения производятся не в байтах, а в объектах: если p является указателем на объект типа T, расположенного по адресу a, и k – целое (возможно отрицательное) число, то p+k будет указывать на объект типа T, расположенного по адресу a+s*k, где s – размер типа T в байтах:

Число k можно трактовать как расстояние между адресами, измеренное в объектах типа T. Аналогично, к указателю можно не только прибавлять, но и вычитать такое расстояние, то есть допустимо и p-k. Если два указателя q1 и q2 были получены из одного и того же указателя p некоторыми последовательностями операций прибавления и вычитания целых чисел, то осмысленно говорить и о сравнении этих указателей и расстоянии между ними. Так, если q1=p+5 и q2= p-5, то
· q1-q2 = 10
· q2-q1 = -10
· q1 > q2 – истинно
На самом деле сравнивать можно любые два указателя, но предсказуемый результат получится только в описанной выше ситуации. Недопустимо складывать или перемножать два указателя и прибавлять к целому числу указатель.
Массивы
Описание массива в языке C выглядит следующим образом: если Т – некоторый тип, а N – константа, то конструкция
T A[N];
отводит память под массив из N элементов типа T. Первый элемент массива имеет индекс 0, а последний – N-1. Сама переменная A имеет тип указателя на T, которой описание присваивает ссылку на первый (т.е. с индексом 0) элемент массива. Отличие этого описания от описания указателя
T * B;
состоит в том, что, во-первых, описание массива определяет также действия по отведению памяти и, во-вторых, переменной A нельзя присваивать новые значения. То есть, по существу, она является константным указателем. Во всём остальном любые указатели можно использовать и как массивы: совершенно законным будет написать B[5] вместо *(B+5).
Сведение семантики массивов к указателям и адресной арифметике практически исключает возможность контроля индексов. Поскольку в адресной арифметике мы можем к указателю не только прибавлять, но и вычитать целые числа, то вполне корректной будет запись A[-2]. С другой стороны, ни во время трансляции, ни во время исполнения не будет обнаружена ошибочность обращения A[N][21].
Язык C допускает литеральные значения для массивов, но только в их инициализации: элементы массива перечисляются в фигурных скобках через запятую. При этом размер массива может определяться количеством элементов в инициализации, как например,
int A[] = { 5, 4, 3, 2, 1};
float A[2][2] = { {5, 4.0}, {3, 2+2} };
Строки
Строки в языке С представляются указателем на первый символ строки. Более того, любой указатель на символ является в языке C строкой. Содержимым строки являются все символы, начиная с указываемого, вплоть до символа с кодом 0, не включая его. Длина строки нигде не хранится, и для её определения необходимо "пробежаться" по строке, что делает эту операцию весьма неэффективной. Достоинство такого подхода состоит в том, что нет явных ограничений на длину строки, в отличии, скажем, от Паскаль.
Не следует путать строки в языке C с массивами символов, хотя мы ранее и говорили, что по существу строки являются подвижными массивами. Так, определение
char s[] = {'H', 'e', 'l', 'l', 'o'};
действительно является массивом длины 5, но не обязательно строкой длины 5, поскольку неизвестно, что следует за символом 'o'.
Литеральные строковые значения представляются последовательностью символов (с тем же синтаксисом, что и одиночных символов), заключённой в двойные кавычки, как, например,
"Hello \"string"!\n"
Здесь за символом перевода строки '\n' неявно присутствует символ '\0'. Поэтому использование литеральной строки в описании массива
char s[] = "Hello";
определит длину массива равной 6. Строки, в отличии от литеральных значений массивов, могут использоваться не только в инициализации.
char * s;
...
if (friendly)
s = "Hi";
else
s = "Hello";
В этом случае транслятор разместит значения констант в специальной области памяти, а присваивание просто установит значение указателя на начало одной из строк.
Сам язык C не предоставляет никаких специальных операций над строками помимо адресной арифметики. Из этого следует, в частности, что для выборки элементов строки может быть использована нотация, характерная для массивов. Например, если s равно "Hello", то s[0] будет равно 'H', s[4] - 'o', а s[5] - '\0'.
Большое количество содержательных операций над строками предоставляется функциями стандартной библиотеки, которые описаны во включаемом файле string.h:
• strlen(s) – длина s
• strcpy(s1,s2) – копирование строки
• strcat(s1,s2) – конкатенация строк
• strchr(s,c) – указатель на первое вхождение с в s
• и т.п.
Все эти операции не выполняют никаких действий по размещению строк-результатов: предполагается, что память для этого выделена отдельно. Например, strcpy предполагает, что s1 уже указывает на участок памяти, длина которого по крайней мере на 1 больше, чем длина длина строки s2, чтобы скопировать содержимое последней и дописать в конце '\0'. Аналогично, strcat предполагает, что непосредственно за s1 достаточно места для дописывания содержимого s2. Укоротить строку можно, присвоив в её середину символ '\0', как в случае
s = "Hello";
s[2] = '\0';
где значением s станет строка "He".
Такая открытость и гибкость позволяет при необходимости определить и другие функции. Например, аналог функции Copy языка Паскаль, "вырезающий" из строки подстроку, можно реализовать следующим образом[22]:
char * PasCopy(char *source, int i, int l)
{
char *dest = (unsigned char *)malloc(l+1);
char *d = dest;
char *s = &(source[i]);
while ((*d++ = *s++) && l--)
;
d[-1] = '\0';
return dest;
}
Также как и для массивов, язык C не обеспечивает контроля индексов для строк. Ситуация усугубляется тем, что символ '\0' имеет выделенное значение. Формально символ с кодом 0 разрешается и внутри литерального значения. Поэтому легально присваивание
s = "Hell\0o"
в результате которого значением s станет строка "Hell".