2020-04-12
2020-04-12 480
480Лекция. Справочная служба
Назначение справочной службы
Подобно большой организации, большая компьютерная сеть нуждается в хранении и удобном доступе и как можно более полной справочной информации о самой себе. Решение многих задач в сети опирается на информацию о пользователях сети — их именах, применяемых для логического входа в систему, паролях, правах доступа к ресурсам сети, а также на информацию о ресурсах и компонентах сети — серверах, клиентских компьютерах, маршрутизаторах, шлюзах, томах файловых систем, принтерах и т. п. К числу таких таких задач относятся аутентификация и авторизация.
Результатом развития систем хранения справочной информации стало появление в сетевых ОС специальной подсистемы — справочной службы.
Справочная служба (directory services), называемая также службой каталогов, имеет основной целью хранение информации, относящейся к сети, в которой эта служба установлена, с тем, чтобы предоставлять эту информацию по запросам всем пользователям и приложениям, имеющим права на доступ к этим данным.
В некоторых случаях справочная служба может быть использована и для хранения информации, не связанной с функционированием сети. Например, она может включать персональные данные служащих, такие как фамилия, имя отчество, должность, заработная плата, домашний адрес, телефон, дата рождения и т. п. Или содержать технические характеристики и данные о наличии оборудования (не обязательно сетевого) в разных подразделениях предприятия. Важно, чтобы характер этих данных совпадал с характером справочной информации, для хранения которой предназначена справочная служба, а именно данные должны быть потенциально полезными для потребителей в пределах всей сети, меняться относительно редко и в небольших масштабах.
Справочная служба хранит информацию обо всех пользователях и ресурсах сети в виде унифицированных объектов, снабженных определенными атрибутами, а также отражает связи хранимых объектов, такие как принадлежность пользователей к определенной группе, права доступа пользователей к компьютерам и разделяемым ресурсам, вхождение нескольких узлов в одну подсеть, коммуникационные связи между подсетями, производственная принадлежность серверов и т. д.
Сетевая служба регулирует взаимодействие между сетевыми объектами, предоставляя доступ к информации в соответствии с заданными в ее базе данных правами доступа для разных типов клиентов этой службы. Клиентами справочной службы являются администраторы, пользователи, приложения, сетевые службы и сетевые устройства.
ПРИМЕЧАНИЕ. Альтернативой единой справочной службе сети является применение нескольких автономных справочных служб узкого назначения: одной — для аутентификации, другой — для управления сетью, третей — для разрешения имен компьютеров и т. д. Однако в крупной сети такой подход оказывается неэффективным. Даже если каждая из таких служб хорошо организована и сочетает централизованный интерфейс с распределенной базой данных, большое число справочных служб приводит к дублированию информации, усложняет администрирование и управление сетью. Например, до 2000 года в операционной системе Windows NT компании Microsoft, имелось, по крайней мере, пять различных типов справочных баз данных. Главный справочник домена (NT Domain Directory Service) хранил информацию о пользователях, требуемую для их логического входа в сеть. Данные о тех же пользователях могли содержаться и в другом справочнике, используемом электронной почтой Microsoft Mail. Еще три базы данных поддерживали разрешение адресов: служба WINS устанавливала соответствие Netbios-имен IP-адресам, справочник DNS — соответствие доменных имен IP-адресам, справочник протокола DHCP служил для автоматического назначения IP-адресов компьютерам сети. Очевидно, что такое разнообразие справочных служб усложняло жизнь администратора и приводило к дополнительным ошибкам, например когда учетные данные одного и того же пользователя нужно было ввести в несколько баз данных. Поэтому в сменивших Windows NT операционных системах на смену всем этим разрозненным справочным службам пришла интегрированная с системой DNS распределенная справочная служба Active Directory, способная хранить и поддерживать всю справочную информацию о системе. Далее в главе хх мы подробно рассмотрим работу этой справочной службы.
Архитектура справочной службы
Для типичной справочной службы характерно использование модели клиент-сервер: выделенные серверы хранят базу справочной информации, которой пользуются клиенты справочной службы, передавая серверам по сети соответствующие запросы.
В соответствии с выбранной архитектурой различают следующие типы справочной службы:
· децентрализованная;
· централизованная;
· распределенная.
Децентрализованнаямодель была характерна для первых реализаций справочных служб (тогда для их обозначения еще не использовался данный термин). На рисунке 5.4 показаны 9 компьютеров сети, каждый из которых оснащен собственной справочной службой, работающей независимо от остальных компьютеров сети; информационные запросы, порожденные на каком-либо компьютере, касаются ресурсов и пользователей, связанных с этим компьютером и обрабатываются на нем же.
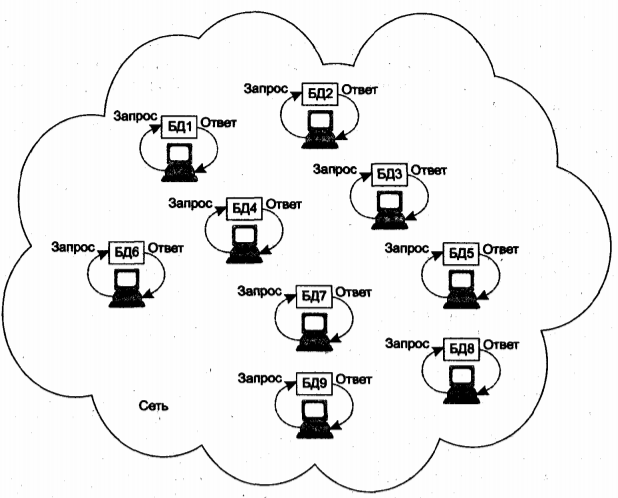
Рис. 5.4. Схема децентрализованной справочной службы
Децентрализованный подход в большой сети приводит к дублированию значительного объема справочных данных, а также к недопустимо большим затратам на администрирование. Последний недостаток отчасти смягчается тем обстоятельством, что децентрализованная справочная служба позволяет легко разделить работу по администрированию между несколькими специалистами.
Централизованная модель является естественной альтернативой децентрализованной модели. В соответствии с этой моделью вся справочная информация о сети и пользователях хранится и обрабатывается на одном компьютере.
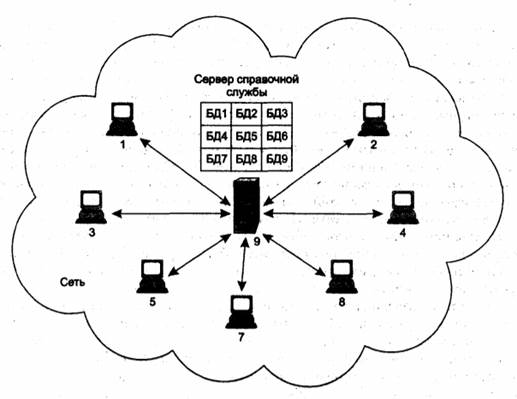
Рис. 5.5. Схема централизованной справочной службы
На рис. 5.5 показан сервер справочной службы, обслуживающий центральную базу данных, которая объединяет справочную информацию БД1 – БД9, относящуюся к каждому из компьютеров сети. Клиентские компоненты справочной службы установлены на всех остальных компьютерах. Используя клиентскую программу, каждый пользователь и приложение, работающие на некотором компьютере сети, могут сделать запрос и получить данные о ресурсах всех других компьютеров.
При этом нет необходимости в дублировании информации. Вместо того чтобы заводить для пользователей учетные записи на тех компьютерах, на которых каждый из них работает, администратор создает и поддерживает единую базу данных для всех пользователей сети, которые обращаются к этой БД для аутентификации. Такая централизованная процедура не «привязывает» пользователя к определенному компьютеру и резко снижает избыточность и сложность ведения учетной информации.
Однако эта модель хорошо работает только в небольшой сети. Реализация справочной службы на основе единой БД, хранящейся в виде одной копии на одном из серверов сети, не подходит для большой системы в первую очередь вследствие низкой производительности и низкой надежности такого решения.
Производительность оказывается низкой из-за того, что запросы к справочной службе от всех пользователей и приложений сети поступают на единственный сервер, который при превышении определенного количества запросов перестает справлятся с их обработкой. Процедура выполнения запроса к серверу может стать неприемлемо длительной из-за задержки передачи запроса (в том числе по глобальным связям), времени пребывания запроса в очереди к серверу и времени, затраченного на поиск информации в базе данных, которое может оказаться значительным, если центральная БД имеет большой объем. Другими словами, такое решение плохо масштабируется в отношении количества обслуживаемых пользователей и разделяемых ресурсов.
Надежность также не может быть высокой в системе с единственной копией данных. Отказ аппаратуры или программного обеспечения сервера, на котором поддерживается эта база данных, приведет к параличу справочной службы в масштабах всей сети.
Смягчить недостатки централизованной модели можно резервированием, то есть поддержанием нескольких копий базы данных на разных компьютерах.
На рис. 5.6 база данных справочной службы представлена двумя идентичными экземплярами, что дает возможность повысить как ее производительность, так и надежность.

Рис. 5.6. Схема централизованной справочной службы с резервированием
За повышение надежности и производительности централизованная система с резервированием расплачивается избыточностью и сложностью поддержания нескольких копий. Кроме того, она не решает проблему плохой масштабируемости, характерную для любой централизованной модели.
Исходя из того, что в небольшой сети централизованная схема работает эффективно, одним из возможных решений могло бы быть разделение большой сети на части - домены - и реализация во всех доменах отдельных, не связанных между собой централизованных справочных служб. На рис. 5.7 показана сеть, разделенная на три домена, в каждом из которых работает собственная централизованная справочная служба. Базы данных, размещенные на серверах справочной службы в каждом домене, содержат лишь часть справочных данных сети, а именно те данные, которые относятся к ресурсам и пользователям соответствующих доменов.

Рис. 5.7. Декомпозиция справочной службы на не связанные между собой справочные службы доменов
Справочные службы доменов обладают всеми преимуществами, свойственными централизованным системам, а главный недостаток централизованных систем — плохая масштабируемость — преодолевается разделением сети на домены. Действительно, хотя увеличение размера сети и ведет к росту общего объема справочных данных, размер каждой отдельной БД может поддерживаться в разумных границах за счет образования новых доменов и связанных с ними новых баз данных. При необходимости повышения производительности и надежности в каждом домене может быть применено резервирование.
Коренным недостатком декомпозиционного подхода является то, что из-за изолированности справочных служб доменов пользователи и приложения получают удобный доступ к справочной информации только в пределах своего домена. В отсутствие какого-либо механизма объединения доменов пользователю придется самому решать, где может находиться искомая информация и по какому адресу следует посылать запрос. Понятно, что такой способ организации справочной службы в виде нескольких не связанных между собой справочных служб отдельных доменов нельзя признать эффективным.
Распределенная модель предполагает наличие нескольких физически разделенных баз данных, виртуально представленных для клиентов в виде единой центральной базы данных (рис. 5.8). В данном случае виртуализация означает, что пользователь любого домена может получить информацию о любом объекте сети вне зависимости от того, с какой рабочей станции поступил запрос и где находится требуемая информация. Такая справочная служба должна скрывать от пользователей различные физические параметры сети: местонахождение серверов, применяемые коммуникационные протоколы, маршруты перемещения запросов, характеристики коммуникационного оборудования и др.
Существуют различные механизмы связывания доменных справочных служб в единую службу сети. Например, в справочной службе Active Directory компании Microsoft таким механизмом является глобальный каталог ( global catalog ), схему применения которого иллюстрирует рис. 5.8.
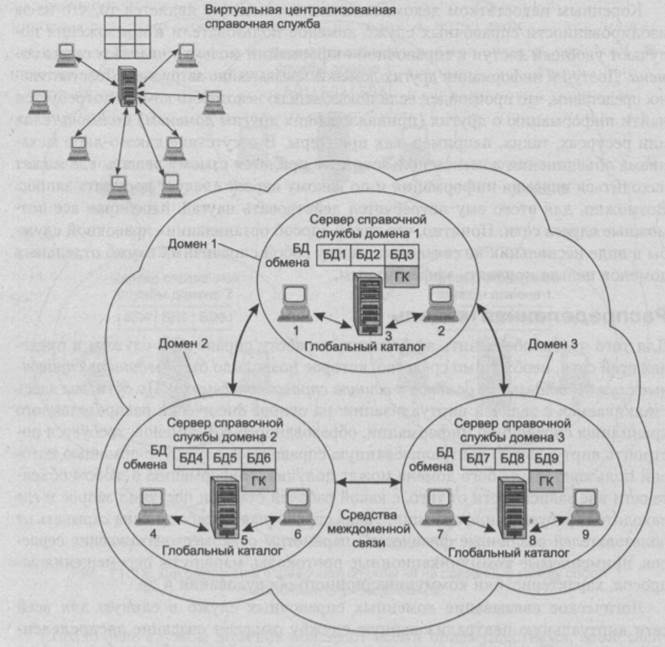
Рис. 5.8. Схема распределенной справочной службы
В то время как доменные базы данных содержат полную информацию об объектах одного домена, в глобальном каталоге представлена частичная информация об объектах всех доменов сети.
В качестве обязательной информации глобальный каталог хранит для каждого объекта атрибуты, которые указывают на местонахождение полной информации о данном объекте.
Копии глобального каталога размещают на сервере справочной службы в каждом домене. При поступлении запроса пользователя к ресурсам, находящимся вне его домена, справочная служба, пользуясь информацией из локальной копии глобального каталога, переадресует запрос к базе данных того домена, где находится интересующий пользователя объект. Все эти действия скрыты от пользователей справочной службы и выполняются автоматически.
Распределенная организация справочной службы является наиболее эффективной для крупных сетей. К числу ее достоинств можно отнести следующие:
Удобство доступа пользователей к справочной информации. В распределенной системе для пользователя поддерживается иллюзия единого централизованного хранилища всей информации, когда степень сложности доступа к любому объекту сети не зависит от того, с какого компьютера поступил запрос.
Удобство администрирования. Для каждой части распределенной базы данных, например домена, можно назначить отдельного администратора и наделить его правами доступа только к части информации обо всей системе.
Надежность. Распределенная система по определению имеет несколько хранилищ и центров обработки информации, а значит, при отказе одного из них система может продолжать функционирование, возможно, в ограниченном объеме. Кроме того, надежность может быть повышена за счет поддержания в каждом домене нескольких копий баз данных этого домена. Необходимые для этого процедуры согласования копий требуют значительно меньщих затрат, чем в централизованных системах, так как проводятся в пределах домена, а не всей сети.
Высокая производительность. Разделение данных между несколькими серверами снижает нагрузку на каждый сервер. Количество серверов не ограничивается числом доменов, так как в каждом домене могут быть установлены серверы, поддерживающие копии доменных БД. Повышению производительности может также способствовать приближение баз данных к источникам запросов за счет рационального разбиения сети на домены.
Хорошая масштабируемость. Распределенная служба продолжает эффективно функционировать даже в очень крупных сетях за счет возможности логической декомпозиции сети на домены. Это, в частности, позволяет ограничить объем БД, снизить вычислительные затраты на поддержание копий БД, приблизить серверы к клиентам, уменьшить сетевой трафик, ускорить время выполнения запросов.