 2020-06-29
2020-06-29 317
317
1. Сформулируйте понятие игры как модели конфликтной ситуации.
2. Сформулируйте основную задачу теории игр.
3. Дайте определение стратегической игры n лиц (сторон).
4. Приведите классификацию теоретико-игровых моделей.
5. Какие игры называются антагонистическими и неантагонистическими, с полной и неполной информацией?
6. Модели каких игр являются наиболее разработанными в теории игр?
2. АНТАГОНИСТИЧЕСКАЯ ИГРА.
ПОИСК РЕШЕНИЯ НА ДЕРЕВЕ ИГРЫ
Представление антагонистической игры
Рассмотрим антагонистическую игру G (m ´ n),где у первого игрока A имеется множество стратегий { Ai }, i =1, …, m, а у второго игрока B – множество стратегий { Bj }, j =1, …, n.
Игра G (m ´ n)может быть представлена в виде дерева игры и в виде матрицы (матрицы платежей).
Представление игры в виде дерева является универсальным, т.е. любая игра может быть представлена в виде дерева, матричное представление не является универсальным – не любая игра может быть приведена к матричной форме.
Рассмотрим представление антагонистической игры G (m ´ n) в виде дерева.
Корневая вершина дерева представляет начальную ситуацию (состояние), промежуточные вершины – промежуточные ситуации, возможные в игре, концевые вершины – все возможные исходы игры, взвешенные платежами – выигрышами игрока A (соответственно, проигрышами игрока B). Дуги – представляют возможные переходы, возникающие в результате личных или случайных ходов, причем личные ходы выполняются игроками согласно выбранных ими стратегий.
Проиллюстрируем процесс построения дерева игры на следующем примере.
Имеется два игрока – A, B.
· 1 ход (личный): игрок А выбирает одну из двух цифр – 1 или 2;
· 2 ход (случайный): бросается монета и если выпадает «герб» (Г), то игроку В сообщается о выборе игрока А, если выпадает «решетка» (Р), то не сообщается;
· 3 ход (личный): игрок В выбирает одну из двух цифр – 3 или 4.
Платеж определяется следующим образом. Суммируются выборы игроков А и В, и если сумма чётная, то она выплачивается игроком В игроку А, если сумма нечетная, то игрок А платит игроку В. Соответствующее дерево игры представлено на рис. 2.1.
Определение 2.1. Классом информации S называется множество вершин дерева, в которых игроку, делающему личный ход, доступна одна и та же информация.
Для рассматриваемого примера имеется четыре класса информации (см. рис. 2.1): S 1, S 2 и S 4, содержащие по одной вершине, и S 3, который содержит две вершины.
Нетрудно доказать следующую лемму.
Лемма 2.1. Для игрыс неполной информацией имеется хотя бы один класс информации, содержащий две или более вершин. Соответственно для игры с полной информацией все классы информации содержат по одной вершине.
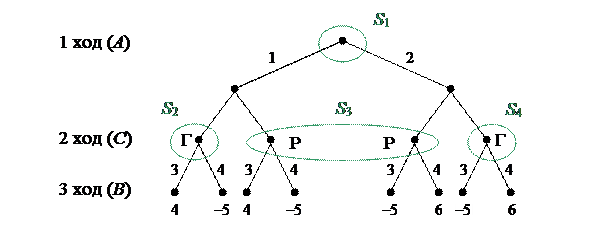
Рис. 2.1. Дерево игры
Так как класс S 3включает две вершины, то, следовательно, в общем случае имеем игру с неполной информацией. Отметим, что в частном случае, когда выпадает «герб» и игроку В сообщается о выборе игрока А, данная игра становится игрой с полной информацией.
Определим множества стратегий игроков.
Очевидно, что у игрока А имеется всего две стратегии (для класса информации S 1): A 1– выбор 1, A 2 – выбор 2.У игрока В стратегией Bi является правило (a, b,d), определяющее выбор игрока в классах информации S 2(a), S 3(b)и S 4(d).Следовательно, у игрока В имеется восемь стратегий: B 1=(3; 3; 3), B 2=(3; 3; 4), …, B 8=(4; 4; 4).
Поиск решения на дереве игры
Общие замечания
Дерево игры может быть построено, используя известные методы полного перебора («в глубину», «в ширину», комбинированный) или сокращенного перебора, выполняемого с использованием некоторой оценочной функции (точной или приближенной, эвристической) [7, 8].
Определение 2.2. Алгоритм поиска решения называется допустимым, если он оканчивает свою работу построением оптимального решения (оптимального пути к цели).
Определение 2.3. Допустимыйалгоритм поиска решения называется оптимальным, если он при поиске решения анализирует (раскрывает) минимальное число вершин.
Примером допустимого (но, конечно, не оптимального) алгоритма является алгоритм, построенный на основе полного перебора. Эвристические алгоритмы, использующие при поиске решения методы сокращенного перебора на основе эвристических функций, как правило, не являются допустимыми, т.е. эти алгоритмы не гарантируют в общем случае нахождение оптимального решения. Преимуществом эвристических алгоритмов являются существенно меньшие затраты вычислительных ресурсов (времени вычислений и памяти) по сравнению с алгоритмами, основанными на полном переборе.
Нильсон Н. (Nilsson N.) в своей классической работе по искусственному интеллекту [7] доказал теорему, определяющую требования к эвристической функции, чтобы алгоритм поиска решения, построенный на ее основе, был допустимым. К сожалению, проверка выполнимости этого требования, в свою очередь, является сложной и обычно практически нереализуемой задачей.
Рассмотрим два универсальных метода сокращенного перебора на дереве игры – метод максимина (максиминный метод) и метод a-b отсечений.
Метод максимина
Суть метода заключается в следующем. Имеется два игрока – A (MAX), задачей которого является максимизация платежа (своего выигрыша), и B (MIN), который, естественно, заинтересован в минимизации этого платежа (своего проигрыша).
Реализуется процедура, результатом выполнения которой является определение наилучшего относительно оценочной функции первого хода игрока A.
Процедура включает следующие шаги.
1. Строится полное поисковое дерево на максимально возможную с учетом вычислительных ресурсов (времени счета и памяти) глубину, при условии равенства числа ходов у обоих игроков.
2. Концевые вершины дерева взвешиваются значениями оценочной функции.
3. Совершается обратное движение по дереву от концевой к начальной вершине с пересчетом значений оценочной функции и итоговым выбором первого хода игрока A, максимизирующего это значение.
Далее осуществляется переход в вершину, соответствующую выбранному ходу, и вся процедура повторяется уже для игрока B, с тем только отличием, что игрок B заинтересован в минимизации значения оценочной функции.
Описанная процедура поочередно применяется для игроков A и B до завершения игры (партии).
Алгоритм поиска на основе метода максимина будет допустимым, если используется точная оценочная функция, и эвристическим, если оценочная функция является эвристической.
Рис. 2.2 иллюстрирует данный метод. Цифры у промежуточных вершин являются пересчитанными для этих вершин значениями оценочной функции. В результате выполнения процедуры будет рекомендовано игроку A в качестве первого хода выбрать переход к вершине S 1 с максимальным значением оценки.
Существенный недостаток метода максимина, следствием которого являются чрезмерно большие затраты вычислительных ресурсов, что, в свою очередь, сокращает глубину построения дерева, заключается в разделении этапов построения дерева и оценки вершин. Усовершенствованием данного метода является метод a-b отсечений, согласно которому отсечение неперспективных вершин производится непосредственно в процессе построения дерева игры.
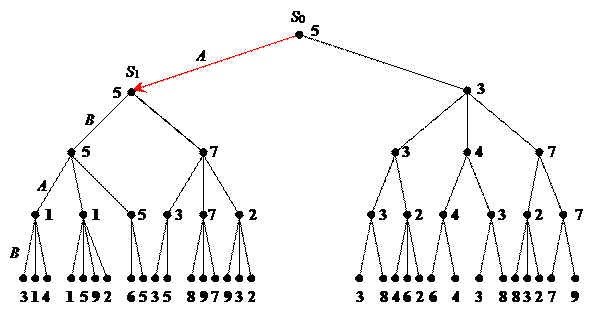
Рис. 2.2. Дерево игры для метода максимина
Метод a-b отсечений
Идея улучшения метода максимина за счет совмещения этапов построения дерева и отсечения неперспективных продолжений была предложено Дж. Маккарти (J. McCarthy) в 1961 г.
Существуют два вида a-b отсечения:
· неглубокое a-b отсечение;
· глубокое a-b отсечение.
Неглубокое a-b отсечение
Рассмотрим дерево игры на рис. 2.3.
 Рис. 2.3. Неглубокое a-b отсечение
Рис. 2.3. Неглубокое a-b отсечение
Пусть известны оценки f (X) = a и f (C) = z £a.. Справедлива следующая лемма.
Лемма 2.2. Если f (C) £ a, то ветви, исходящие из вершины Y и обозначенные штриховой линией, можно отсечь.
Доказательство. Так как игрок B стремится минимизировать оценочную функцию, то оценка вершины Y будет не больше z, т.е. f (Y) £ f (C) £ a. Следовательно, вершина Y не будетконкурировать с вершиной X при выборе игрока A, так как f (Y) £ f (X), что и означает неперспективность ветвей, исходящих из вершины Y.
Мы рассмотрели a отсечение, соответствующее выбору игрока A. Аналогичные рассуждения справедливы и для bотсечения в ситуации, когда выбор делает игрок B при справедливости следующих оценок: f (X)=b, f (C)= w ³ b.
Глубокое a-b отсечение
Рассмотрим дерево игры на рис. 2.4. Пусть известны оценки f (X) = a и f (E) = z £ a..
Докажем следующую лемму.
Лемма 2.3. Если f (E) £ a, то ветви, исходящие из вершины D и помеченные штриховой линией, можно отсечь.
Доказательство. Так как игрок B стремится минимизировать оценочную функцию, то для вершины D будет справедлива следующая оценка f (D) £ f (E) £ a, а для вершины C, ход из которой делает игрок A, стремящийся максимизировать оценочную функцию, соответственно f (C) ³ f (D).
Рассмотрим две возможности:
1. f (C) = f (D), что означает f (C)£ f (E)£a, т.е. имеем согласно лемме 2.2 неглубокое a отсечение, означающее неперспективность для игрока A вообще всех продолжений из вершины Y.
2. f (C) > f (D), что означает неучастие (неперспективность) вершины D для получения оценки f (C).
Лемма доказана.
Рис. 2.5 иллюстрирует применение метода a - bотсечений.
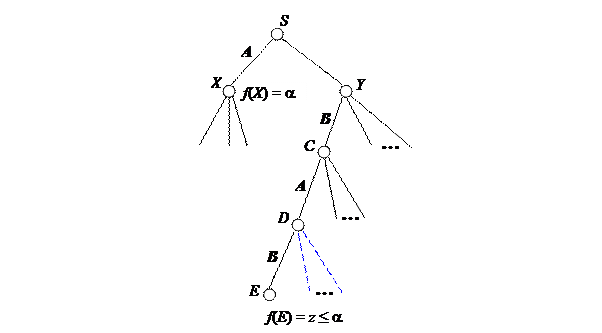
Рис. 2.4. Глубокое a-b отсечение
Из рис. 2.5 видно, что игроку A рекомендуется в качестве первого хода выбрать продолжение, ведущее к вершине X.
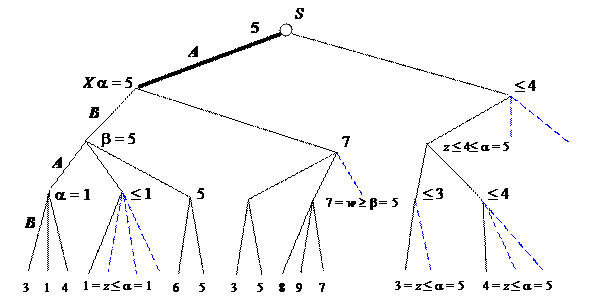
Рис. 2.5. Применение метода a-b отсечений
Табл. 2.1 иллюстрирует процедуру a - bотсечения.
Таблица 2.1
| Ход | Наилучшая оценка | Позиция на глубину | Оценка позиции | Условие отсечения | Действие |
| A (max) | a | Своя | z | z £ a | a отсечение |
| B (min) | b | Противника | w | w ³ b | b отсечение |
Заметим, что оценка a возрастает при движении по дереву снизу вверх, а оценка b,наоборот,убывает.
Приведем сравнительные оценки методов максимина и a - bотсечений. Пусть оценивается дерево на глубину ходов (уровней) n (для равенства ходов игроков n должно быть четным) и на каждом уровне имеется m вариантов выбора. Тогда сложность вычислений равна:
· mn для метода максимина;
·»2 mn /2 для метода a - b отсечения.
Таким образом, метод a - b отсечений позволяет при тех же затратах памяти, что и метод максимина, построить дерево в среднем на глубину, в два раза большую, а значит, найти более качественное решение. Эффективность метод a - b отсечений возрастает, если удается предварительно упорядочить оцениваемые вершины по убыванию оценки a и возрастанию оценки b.
К недостаткам рассмотренных методов относятся:
· по сути оба метода не являются стратегиями и базируются на классических переборных алгоритмах с использованием оценочной функции;
· наличие эффекта горизонта, т.е. методы «не видят» выигрыша, который находится за горизонтом (ниже по дереву) оцениваемых вершин.








