2020-08-05
2020-08-05 144
144Априорное допущение: существует небольшое число (в сравнении с числом р исходных анализируемых признаков 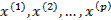 ) p’ признаков – детерминант (главные компоненты, общие факторы, наиболее информативные объясняющие переменные), с помощью которых могут быть достаточно точно описаны анализируемые переменные наблюдаемых объектов. При этом главные факторы могут находиться среди исходных признаков, а могут быть латентными, т.е. непосредственно статистически не наблюдаемыми, но восстанавливаемыми по исходным данным.
) p’ признаков – детерминант (главные компоненты, общие факторы, наиболее информативные объясняющие переменные), с помощью которых могут быть достаточно точно описаны анализируемые переменные наблюдаемых объектов. При этом главные факторы могут находиться среди исходных признаков, а могут быть латентными, т.е. непосредственно статистически не наблюдаемыми, но восстанавливаемыми по исходным данным.
1. Отбор наиболее информативных показателей (включая выявление латентных факторов). Имеется в виду решение задачи от отборе из исходного (априорного) множества признаков 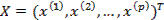 или о построении в качестве некоторых комбинаций исходных признаков относительно небольшого числа p’ переменных
или о построении в качестве некоторых комбинаций исходных признаков относительно небольшого числа p’ переменных 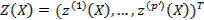 , которые обладали бы свойствами наибольшей информативности в смысле, определённом, как правило, некоторым специально подобранным для задач критерием информативности
, которые обладали бы свойствами наибольшей информативности в смысле, определённом, как правило, некоторым специально подобранным для задач критерием информативности 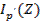 .
.
Пример 1. Если критерий 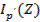 «настроен» на достижение максимальной точности регрессионного прогноза некоторого результирующего показателя Y по известным значениям предикторных переменных, т.е. речь идёт о наилучшем подборе наиболее существенных предиктов в модели регрессии.
«настроен» на достижение максимальной точности регрессионного прогноза некоторого результирующего показателя Y по известным значениям предикторных переменных, т.е. речь идёт о наилучшем подборе наиболее существенных предиктов в модели регрессии.
Пример 2. Если критерий устроен таким образом, что его оптимизация обеспечивает наивысшую точность решения задачи отнесения объекта к одному из классов по значениям Х его описательных признаков, то речь идёт о построении системы типообразующих признаков в задачах классификации или о выявлении и интерпретации некоторой сводной (латентной) характеристики изучаемого свойства.
Пример 3. Критерий может быть нацелен на максимальную автоинформированность новой системы показателей, т.е максимально точное воспроизведение всех исходных признаков по небольшому числу вспомогательных переменных 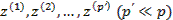 . В этом случае можно говорить о наилучшем автопрогнозе и целесообразно обратиться к методам и моделям факторного анализа и его разновидностей.
. В этом случае можно говорить о наилучшем автопрогнозе и целесообразно обратиться к методам и моделям факторного анализа и его разновидностей.
2. Сжатие массивов обрабатываемой и хранимой информации. Этот тип задач тесно связан с предыдущими, в частности, требует в качестве одного из основных приемов решения построения экономной системы вспомогательных признаков, обладающей автоинформированностью, т.е. свойством автопрогноза. Классификации зачастую позволяют перейти от массива, содержащего информацию по всем n статистически обследованным объектом, к соответствующей информации только по k эталонным образцам 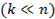 . Методы снижения размерности позволяют заменить исходную систему показателей
. Методы снижения размерности позволяют заменить исходную систему показателей 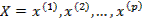 набором вспомогательных переменных . Таким образом, размерность информационного массива понижается от
набором вспомогательных переменных . Таким образом, размерность информационного массива понижается от 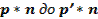 .
.
Визуализация данных. При формировании рабочих гипотез, исходных допущений о геометрической и вероятностной природе совокупности анализируемых данных 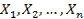 важно было бы суметь «подсмотреть», как эти данные точки располагаются в анализируемом пространстве. Здесь попутно может возникнуть задача снижения анализируемой совокупности в соответствии с некоторым специально сформулированным критерием..
важно было бы суметь «подсмотреть», как эти данные точки располагаются в анализируемом пространстве. Здесь попутно может возникнуть задача снижения анализируемой совокупности в соответствии с некоторым специально сформулированным критерием..
3. Построение условных координатных осей (многомерное шкалирование. Латентно-структурный анализ). В данной постановке задачи исходной координатной системы не существует вовсе, а подлежащие статистическому анализу и моделированию данные представлены в статистическом варианте, т.е матрица из элементов 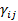 – парные сравнения объектов.
– парные сравнения объектов.
Ставится задача: для заданной, сравнительно невысокой размерности 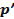 определить вспомогательные условные координатные оси
определить вспомогательные условные координатные оси 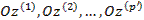 и способ сопоставления каждому объекту
и способ сопоставления каждому объекту 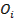 его координат в этой системе таким образом, чтобы попарные отношения
его координат в этой системе таким образом, чтобы попарные отношения  (например попарные взаимные расстояния между объектами, вычисленные на базе этих условных координат) в определённом смысле минимально бы отличались от заданных величин
(например попарные взаимные расстояния между объектами, вычисленные на базе этих условных координат) в определённом смысле минимально бы отличались от заданных величин 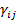 (построение различных рейтингов).
(построение различных рейтингов).
Метод главных компонент – переход к новым объясняющим переменным, линейным комбинациям старых.
1) Центрирование переменных 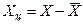 ,
, 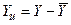
2) Решение характеристического уравнения 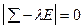 :
:
a) Нахождение собственных чисел 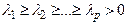
b) Нахождение для каждого собственного числа 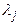 собственного вектора
собственного вектора 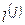
3) Переход к новым переменным 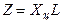 ,
, 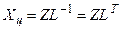
4) Построение линейной регрессии 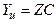 , вычисление оценок с помощью МНК
, вычисление оценок с помощью МНК
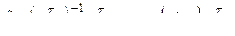
5) Проверка гипотез  , исключение несущественных переменных
, исключение несущественных переменных
6) При необходимости переход к исходной модели 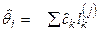 ,
,