 2020-10-10
2020-10-10 1233
1233В качестве недостатка архитектуры фон Неймана можно назвать возможность непреднамеренного нарушения работоспособности системы (программные ошибки) и преднамеренное уничтожение ее работы (вирусные атаки). В Гарвардской архитектуре принципиально различаются два вида памяти микропроцессора:
- память программ (для хранения инструкций микропроцессора);
- память данных (для временного хранения и обработки переменных).
В гарвардской архитектуре принципиально невозможно осуществить операцию записи в память программ, что исключает возможность случайного разрушения управляющей программы в случае ошибки программы при работе с данными или атаки третьих лиц. Кроме того, для работы с памятью программ и с памятью данных организуются отдельные шины обмена данными (системные шины), как это показано на структурной схеме, приведенной на рисунке.
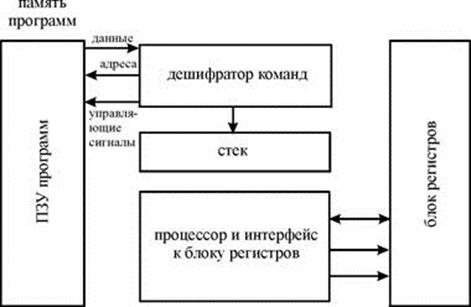
Рисунок. Структурная схема гарвардской архитектуры
Эти особенности определили области применения гарвардской архитектуры. Гарвардская архитектура применяется в микроконтролерах и в сигнальных процессорах, где требуется обеспечить высокую надёжность работы аппаратуры. В сигнальных процессорах Гарвардская архитектура дополняется применением трехшинного операционного блока микропроцессора. Трехшинная архитектура операционного блока позволяет совместить операции считывания двух операндов с записью результата выполнения команды в оперативную память микропроцессора. Это значительно увеличивает производительность сигнального микропроцессора без увеличения его тактовой частоты.
В Гарвардской архитектуре характеристики устройств памяти программ и памяти данных не всегда выполняются одинаковыми. В памяти данных и команд могут различаться разрядность шины данных и распределение адресов памяти. Часто адресные пространства памяти программ и памяти данных выполняют различными. Это приводит к различию разрядности шины адреса для этих видов памяти. В микроконтроллерах память программ обычно реализуется в виде постоянного запоминающего устройства, а память данных – в виде ОЗУ. В сигнальных процессорах память программ вынуждены выполнять в виде ОЗУ. Это связано с более высоким быстродействием оперативного запоминающего устройства, однако при этом в процессе работы осуществляется защита от записи в эту область памяти.
Применение двух системных шин для обращения к памяти программ и памяти данных в гарвадской архитектуре имеет два недостатка – высокую стоимость и большое количество внешних выводов микропроцессора. При использовании двух шин для передачи команд и данных, микропроцессор должен иметь почти вдвое больше выводов, так как шина адреса и шина данных составляют основную часть выводов микропроцессора. Для уменьшения количества выводов кристалла микропроцессора фирмы-производители микросхем объединили шины данных и шины адреса для внешней памяти данных и программ, оставив только различные сигналы управления (WR, RD, IRQ) а внутри микропроцессора сохранили классическую гарвардскую архитектуру. Такое решение получило название модифицированная гарвардская архитектура.
Модифицированная гарвардская структура применяется в современных микросхемах сигнальных процессоров. Ещё дальше по пути уменьшения стоимости кристалла за счет уменьшения площади, занимаемой системными шинами пошли производители однокристалльных ЭВМ – микроконтроллеров. В этих микросхемах применяется одна системная шина для передачи команд и данных (модифицированная гарвардская архитектура) и внутри кристалла.
В сигнальных процессорах для реализации таких алгоритмах как быстрое преобразование Фурье и цифровая фильтрация часто требуется еще большее количество внутренних шин. Обычно применяются две шины для чтения данных, одна шина для записи данных и одна шина для чтения инструкций. Подобная структура микропроцессора получила название расширенной гарвардской архитектуры. Этот подход практикуют производители сигнальных процессоров – фирмы Analog Devices (семейства сигнальных процессоров BlackFin и Tiger Shark), Texas Instrunents (семейства сигнальных процессоров C5000™ DSPs и C6000™ DSPs), Freescale (семейства сигнальных процессоров MSC8251 и DSP56K).
2. Понятие и классификация архитектур вычислительных систем
С развитием вычислительной техники появились многопроцессорные системы и сети, объединяющие большое количество отдельных процессоров и вычислительных машин, программные системы, реализующие параллельную обработку данных на многих вычислительных узлах. Появился термин «вычислительные системы».
Вычислительную систему (ВС) стандарт ISO/IEC2382/1-93 определяет, как одну или несколько вычислительных машин, периферийное оборудование и программное обеспечение, которые выполняют обработку данных.
Вычислительная система состоит из связанных между собой средств вычислительной техники, содержащих не менее двух основных процессоров, имеющих общую память и устройство ввода-вывода.
Если не вдаваться в подробности, ВС прежде всего можно разделить на:
ü многомашинные:
ü многопроцессорные.
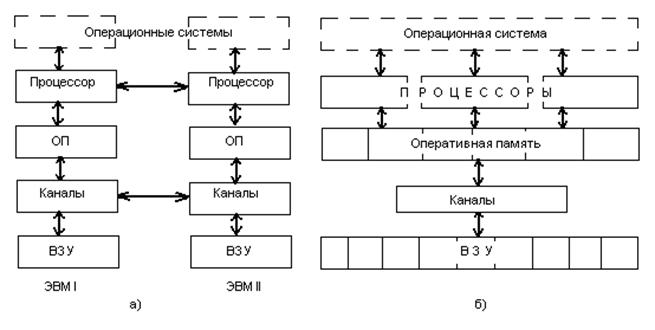
Многомашинная вычислительная система
Здесь несколько процессоров, входящих в вычислительную систему, не имеют обшей оперативной памяти, а имеют каждый свою (локальную). Каждый компьютер в многомашинной системе имеет классическую архитектуру, однако эффект от применения такой вычислительной системы может быть получен только при решении задач, имеющих очень специальную структуру: она должна разбиваться на столько слабо связанных подзадач, сколько компьютеров в системе.
Многопроцессорная архитектура. Наличие в компьютере нескольких процессоров означает, что параллельно может быть организовано много потоков данных и много потоков команд. Таким образом, параллельно могут выполняться несколько фрагментов одной задачи. Преимущество в быстродействии многопроцессорных и многомашинных вычислительных систем перед однопроцессорными очевидно.

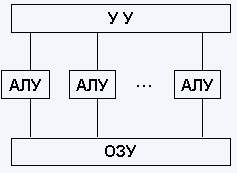
Архитектура с параллельными процессорами. Здесь несколько АЛУ работают под управлением одного УУ. Это означает, что множество данных может обрабатываться по одной программе, т. е. по одному потоку команд. Высокое быстродействие такой архитектуры можно получить только на задачах, в которых одинаковые вычислительные операции выполняются одновременно на различных однотипных наборах данных.
Формально отличие ВС от вычислительной машины, совокупности технических средств, создающих возможность проведения обработки информации и получения результата в необходимой форме, выражается в количестве вычислительных средств. Множественность этих средств позволяет реализовать в ВС параллельную обработку.
Таким образом, вычислительная система является результатом интеграции аппаратных средств и программного обеспечения, функционирующих в единой системе и предназначенных для совместного выполнения информационно-вычислительных процессов.
Основной отличительной чертой вычислительных систем по отношению к ЭВМ, функциональные устройства которой выполнены на электронных компонентах, является наличие в них нескольких вычислителей, реализующих параллельную обработку. Точного различия между вычислительными машинами и вычислительными системами определить невозможно, так как вычислительные машины даже с одним процессором обладают разными средствами распараллеливания, а вычислительные системы могут состоять из традиционных вычислительных машин или процессоров.
Основой цифровых вычислительных систем являются логические цифровые схемы, основанные на элементах, принимающих два возможных фиксированных значения – «0» и «1».
Потребность в более быстрых, дешевых и универсальных процессорах вынуждает производителей постоянно наращивать число транзисторов в них. Однако этот процесс не бесконечен. Поддерживать экспоненциальный рост этого числа, предсказанный Гордоном Муром в 1973 году, становится все труднее. Специалисты утверждают, что этот закон перестанет действовать, как только затворы транзисторов, регулирующие потоки информации в чипе, станут соизмеримыми с длиной волны электрона (в кремнии, на котором сейчас строится производство, это порядка 10 нанометров). Произойдет это до 2020 годами. По мере приближения к физическому пределу архитектура компьютеров становится все более изощренной, возрастает стоимость проектирования, изготовления и тестирования чипов. Таким образом, этап эволюционного развития рано или поздно сменится революционными изменениями.
В результате гонки наращивания производительности возникает множество проблем:
– перегрев в сверхплотной упаковке, вызванный существенно меньшей площадью теплоотдачи;
– снижение надежности транзисторов из-за уменьшения их размеров и утоньшения изолирующего слоя;
– снижение размеров транзисторов уменьшает скорость их срабатывания, она перестает соответствовать скорости распространения сигнала по внутрисхемным соединениям;
– более тонкие проводники, соединяющие транзисторы, имеют и более высокое сопротивление, и неприемлемо высокую задержку распространения сигнала. Эта проблема была отчасти решена путем использования многослойных соединений.
Возможности по совершенствованию элементной базы уже практически исчерпаны, дальнейшее повышение производительности вычислительных машин лежит в плоскости архитектурных решений.
На сегодняшний день основное условие повышения производительности процессоров – методы параллелизма. Как известно, микропроцессор обрабатывает последовательность инструкций (команд), составляющих ту или иную программу. Если организовать параллельное (то есть одновременное) выполнение инструкций, общая производительность существенно вырастет.
Параллелизм выполнения операций существенно повышает быстродействие системы; он может также значительно повысить и надежность (при отказе одного компонента системы его функции может взять на себя другой), и достоверность функционирования системы, если операции будут дублироваться, а результаты их выполнения сравниваться.
Решается проблема параллелизма методами
- конвейеризации вычислений,
- применением суперскалярной архитектуры
- предсказанием ветвлений.
Под конвейерным режимом понимают такой вид обработки, при котором интервал времени, требуемый для выполнения процесса в функциональном узле (например, в АЛУ) микропроцессора, продолжительнее, чем интервалы, через которые данные могут вводиться в этот узел. Предполагается, что функциональный узел выполняет процесс в несколько этапов, т. е. когда первый этап завершается, результаты передаются на второй этап, на котором используются другие аппаратные средства. Разумеется, что устройство, используемое на первом этапе, оказывается свободным для начала новой обработки данных.
Суперскалярная архитектура – параллелизм на уровне инструкций (то есть, процессор, способный выполнять несколько инструкций одновременно) за счёт включения в состав его вычислительного ядра нескольких одинаковых функциональных узлов (таких как АЛУ[1], FPU[2], умножитель (integer multiplier), сдвигающее устройство (integer shifter) и другие устройства).
Однако помимо явных преимуществ применение конвейера и дублирование его блоков в микропроцессорах порождают ряд проблем, наиболее значимая из которых обусловлена наличием команд перехода, нарушающих естественный порядок вычислений.
Модуль предсказания переходов (прогнозирования ветвлений) – устройство, входящее в состав процессора, имеющего конвейерную архитектуру, предсказывающее, будет ли выполнен условный переход в исполняемой программе.
Предсказание ветвлений позволяет сократить время простоя конвейера за счёт предварительной загрузки и исполнения инструкций, которые должны выполниться после выполнения инструкции условного перехода. Прогнозирование ветвлений играет критическую роль, так как в большинстве случаев (точность предсказания переходов в современных процессорах превышает 90 %) позволяет оптимально использовать вычислительные ресурсы процессора.








