 2020-10-10
2020-10-10 1624
1624Регрессионный анализ в машинном обучении относится к классу задач обучения с учителем.
Нужно построить модель на обучающих данных, а затем получить точные прогнозы для новых, еще не встречавшихся нам данных, которые имеют те же самые характеристики, что и использованный нами обучающий набор. Если модель может выдавать точные прогнозы на ранее не встречавшихся данных, мы говорим, что модель обладает способностью обобщать (generalize) результат на тестовые данные. Нам необходимо построить модель, которая будет обладать максимальной обобщающей способностью. Обычно мы строим модель таким образом, чтобы она давала точные прогнозы на обучающем наборе. Если обучающий и тестовый наборы имеют много общего между собой, можно ожидать, что модель будет точной и на тестовом наборе. Однако в некоторых случаях этого не происходит. Поэтому нам нужно правило, которое будет хорошо работать для новых объектов, и достижение 100%-ной правильности на обучающей выборке не поможет нам в этом. Единственный показатель качества работы алгоритма на новых данных – это использование тестового набора.
Выбор слишком простой модели называется недообучением (underfitting). Чем сложнее модель, тем лучше она будет работать на обучающих данных. Однако, если наша модель становится слишком сложной, мы начинаем уделять слишком много внимания каждой отдельной точке данных в нашем обучающем наборе, и эта модель не будет хорошо обобщать результат на новые данные.
Переобучение происходит, когда ваша модель слишком точно подстраивается под особенности обучающего набора и вы получаете модель, которая хорошо работает на обучающем наборе, но не умеет обобщать результат на новые данные. С другой стороны, если ваша модель слишком проста, вы, возможно, не смогли охватить все многообразие и изменчивость данных, и ваша модель будет плохо работать даже на обучающем наборе.
Существует оптимальная точка, которая позволяет получить наилучшую обобщающую способность. Собственно, это и есть модель, которую нам нужно найти. Компромисс между переобучением и недообучением показан на рис. 1.
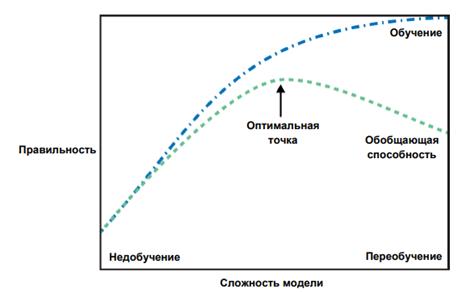
Рисунок 1 – Компромисс между сложностью модели и правильностью на обучающей и тестовой выборках
Взаимосвязь между точностью модели и размером объема данных
Важно отметить, что сложность модели тесно связана с изменчивостью входных данных, содержащихся в вашем обучающем наборе: чем больше разнообразие точек данных в вашем наборе, тем более сложную модель можно использовать, не беспокоясь о переобучении. Обычно больший объем данных дает большее разнообразие, таким образом, большие наборы данных позволяют строить более сложные модели. Увеличение объема данных (только не простым дублированием) и построение более сложных моделей часто могут значительно улучшить результат при решении задач машинного обучения с учителем. При выполнении учебных заданий мы сосредоточимся на работе с данными фиксированного размера. В действительности же, как правило, исследователь сам можете определять объем собираемых данных, и это может оказаться более результативным и полезным, чем корректировка и настройка модели. Никогда не стоит недооценивать преимущества увеличения объема данных.








