 2020-10-10
2020-10-10 245
245Тема 4
ИЗМЕРИТЕЛЬНЫЕ ШКАЛЫ
Различают четыре типа измерений переменных:
1. Измерения в дихотомической шкале наименований. Фиксируется просто наличие или отсутствие чего-либо. Данные представляют собой нули и единицы. Порядок оценивания является, как правило, произвольным. Примеры: республиканец (1) – демократ (0); учащийся школы (1) – не учащийся школы (0); мужчина (1) – женщина (0); женат (1) – холост (0).
2. Измерения в дихотомической шкале наименований в предположении нормального распределения. Предполагается, что более утонченные, более полные и более совершенные методы измерения могли бы обеспечить приблизительно нормальное распределение результатов, но рассматриваемые данные говорят лишь о том, будет ли объект занимать положение выше (1) или ниже (0) некоторой точки в этом нормальном распределении. Если в отношении большой группы учащихся было известно только, превышает ли коэффициент интеллекта отметку 120 (обозначим этот факт единицей) или нет (обозначим это 0), то единицы и нули представляли бы собой дихотомические данные, основанные на нормальном распределении. Конечно, было бы неэффективным пренебрегать исходными данными и записывать вместо них единицы и нули, и это, как правило, не делается (несмотря на то, что в ранней истории факторного анализа это было удобным с точки зрения вычисления).
3. Измерения в шкале порядка. Данные представляют собой последовательные несвязанные ранги 1, 2,..., п. Эти ранги можно присвоить измерениям другой шкалы (например, когда исходные данные 136, 124, 97 ранжируются номерами 1, 2, 3), или они могут быть прямым переводом восприятий в числа (например, когда судья ранжирует 10 конкурентов от наиболее опытного – 1 до наименее опытного – 10). Пример: 94 ученика выпускного класса ранжируются от 1 до 94 по средним баллам.
4. Измерения в шкалах интервалов или отношений. Существует единица измерения, например дюйм, день и т. д., а (в случае шкалы отношений) нулевая точка на шкале соответствует отсутствию (то есть нулю) измеряемой переменной. Результатом может быть любое действительное число, а разности между отметками отражают разности значений характеристики. В этой лекции мы, как правило, будем считать, что интервальные и относительные измерения приблизительно нормально распределены, хотя, конечно, в некоторых случаях этого может и не быть.
Таблица 9.1
Преобразование 10 оценок шкалы интервалов в ранги (шкалу порядка) и
в 0,1 (шкалу дихотомии)
| Номер | Отметки вербального мышления | Ранговые оценки | Дихотомическое оценивание в предположении нормального распределения |
| 1 | 17 | 3 | 1 |
| 2 | 10 | 7 | 0 |
| 3 | 29 | 1 | 1 |
| 4 | 16 | 4 | 1 |
| 5 | 3 | 10 | 0 |
| 6 | 14 | 5 | 1 |
| 7 | 9 | 8 | 0 |
| 8 | 26 | 2 | 1 |
| 9 | 6 | 9 | 0 |
| 10 | 11 | 6 | 0 |
Если измерение можно произвести на уровне шкал интервалов или отношений, то результаты можно преобразовать в любую из трех других названных шкал. Например, предположим, что 10 студентов получили отметки в ходе испытания вербального мышления, которые, как принято считать, характеризуются, хотя и грубо, приближенным нормальным распределением по шкале интервалов: см. табл. 9.1.
Первый столбец задает порядковый номер студента. Исходные отметки, которые, по предположению, основаны на распределении, близком к нормальному, приведены во втором столбце. Эти 10 оценок проранжированы в третьем столбце. В четвертом столбце 5 наибольших исходных значений были заменены 1, а 5 наименьших – 0.
ТАБУЛИРОВАНИЕ И ПРЕДСТАВЛЕНИЕ ДАННЫХ
Табулирование данных
До анализа количественных данных необходимо их обобщить. В табл. 3.1 приводятся (во втором столбце) результаты контрольной по чтению. Оценки проставлялись так, как записаны ученики в журнале.
Первый этап представления данных – это упорядочивание оценок по величине от максимальной до минимальной. В третьем столбце табл. 3.1 представлены те же 38 оценок, что и во втором, но упорядоченные по убыванию от 112 до 44. В четвертом столбце таблицы указан ранговый порядок учеников. Если ученики получили одинаковые оценки (например, в рассматриваемом случае два ученика имеют оценку 97, три ученика – 75), то их ранги (7, 8 и 22, 23, 24) усреднены (7,5 и 23).
Для большого числа оценок на следующем этапе имеет смысл обобщение данных. Оценки могут быть сгруппированы. Каждая такая группа называется разрядом оценок. Желательно образовывать не менее 12 и не более 15 разрядов. Иметь менее 12 разрядов рискованно из-за возможного искажения результатов, а наличие более 15 разрядов затрудняет работу с данными.
Процесс построения распределения сгруппированных частот складывается из четырех этапов.
1. Определение общего размаха внутри всей выборки, который равен разности между максимальной и минимальной оценками плюс единица (112 –
– 44 + 1 = 69).
2. Выбор интервала группирования разрядов, представляющего собой ширину разрядов, по которым должны быть классифицированы оценки, должен производиться таким образом, чтобы разрядов было не менее 12, но и не более 15. Для этого разделим диапазон на 12 и найдем наибольший возможный класс или интервал разряда оценок (69:12 = 5,75). Разделим диапазон на 15 и найдем наименьший возможный интервал разряда (69:15 = 4,60). Так как использовать любой нецелый интервал неудобно, то наибольший интервал 5,75 округляется с уменьшением до 5, а наименьший 4,60 – с увеличением до 5.
3. Определение границ разрядов. Начинать всегда необходимо с величины, кратной разрядному интервалу так, чтобы были включены самая низкая и самая высокая оценки. В рассматриваемом примере самый низкий разряд надо начать с 40, кратного 5, он включит самую низкую оценку 44. Следующий разряд будет начинаться с 45, затем с 50 и т.д. до тех пор, пока самая высокая оценка 112 не попадет в разряд 110-114. Эти разряды записаны в пятом столбце табл. 3.1.
4. Табулирование. Подсчет ведется для каждой оценки против разряда, в который она попадает. Для табулирования нет необходимости в упорядочении оценок. В первоначальном алфавитном списке (второй столбец) первая оценка 90. В столбце таблицы против разряда, начинающегося с 90, для регистрации оценки ставится крестик. Следующая оценка – 66. Она попадает в разряд, который начинается с 65, так что крестик ставится там. Аналогично поступают для всех прочих оценок.
В итоговой таблице не приводятся этапы, в результате которых она была получена. В простейшей форме распределения частот есть только два столбца. В первом приводятся разряды, обычно расположенные в убывающем порядке сверху вниз, а второй содержит частоты – число оценок в каждом разряде.
Таблица 3.1 – Оценки контрольной по чтению, упорядоченные по величине, проранжированные и протабулированные
| № п/п | Оценка | Убывающая последователь-ность | Ранг | Границы разрядов | Подсчет | Час-тота (f) | Накопленная частота (cum.f) |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 1 | 90 | 112 | 1 | 110-114 | x | 1 | 38 |
| 2 | 66 | 109 | 2 | 105-109 | x x x | 3 | 37 |
| 3 | 106 | 106 | 3 | 100-104 | x x | 2 | 34 |
| 4 | 84 | 105 | 4 | 95-99 | x x x x | 4 | 32 |
| 5 | 105 | 104 | 5 | 90-94 | x x x | 3 | 28 |
| 6 | 83 | 100 | 6 | 85-89 | x | 1 | 25 |
| 7 | 104 |
|
| 80-84 | x x x x x x | 6 | 24 |
| 8 | 82 | 75-79 | x x x x | 4 | 18 | ||
| 9 | 97 |
|
| 70-74 | x x x x | 4 | 14 |
| 10 | 97 | 65-69 | x x x | 3 | 10 | ||
| 11 | 59 | 93 | 11 | 60-64 | x | 1 | 7 |
| 12 | 95 | 91 | 12 | 55-59 | x x x | 3 | 6 |
| 13 | 78 | 90 | 13 | 50-54 | x | 1 | 3 |
| 14 | 70 | 89 | 14 | 45-49 | x | 1 | 2 |
| 15 | 47 |
|
| 40-44 | x | 1 | 1 |
| 16 | 95 | ||||||
| 17 | 100 | 83 | 17 | ||||
| 18 | 69 | 82 | 18 | ||||
| 19 | 44 | 81 | 19 | ||||
| 20 | 80 | 80 | 20 | ||||
| 21 | 75 | 78 | 21 | ||||
| 22 | 75 |
|
| ||||
| 23 | 51 | ||||||
| 24 | 109 |
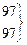
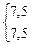
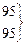
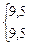
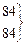
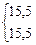
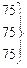
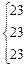
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 25 | 89 | 74 | 25 | ||||
| 26 | 58 | 72 | 26 | ||||
| 27 | 59 | 71 | 27 | ||||
| 28 | 72 | 70 | 28 | ||||
| 29 | 74 | 69 | 29 | ||||
| 30 | 75 | 68 | 30 | ||||
| 31 | 81 | 66 | 31 | ||||
| 32 | 71 | 62 | 32 | ||||
| 33 | 68 |
|
| ||||
| 34 | 112 | ||||||
| 35 | 62 | 58 | 35 | ||||
| 36 | 91 | 51 | 36 | ||||
| 37 | 93 | 47 | 37 | ||||
| 38 | 84 | 44 | 38 |

Квантили
Квантиль – это точка на числовой шкале, по предположению, основанная на группе наблюдений; квантиль делит совокупность наблюдений на две группы с известными пропорциями в каждой из них. Квантиль – общее понятие, а процентили, децили, квинтили и квартили – четыре его примера.
Существуют три квартиля (Q 1, Q 2, Q 3). Они делят группу наблюдений на четыре равные части (кварты). Четвертая часть наблюдений лежит ниже Q1, половина наблюдений лежит ниже Q2, а три четверти наблюдений – ниже Q3. Таким образом, три квартиля делят совокупность наблюдений на четыре части, которые равны в смысле пропорциональности наблюдений.
Четыре квинтиля (K 1, K 2, K 3, K 4) делят группу наблюдений на пять равных частей (квинты). Девять децилей (D 1, …, D 9) делят множество наблюдений на десять равных частей. 99 процентилей (P 1, …, P 99) делят множество наблюдений на сто частей с равным числом наблюдений в каждой.
Квантили очень удобны для обобщения данных. Простое сообщение, что P 5 есть 10,75, а P 15 – 16,80, сразу же говорит нам о том, что 15 % наблюдений меньше 16,80, причем 10 % наблюдений лежит между 10,75 и 16,80.
Т.к. 25 % всех наблюдений находится ниже P 25 (25-го процентиля), и то же справедливо для Q 1 (первого квартиля), то P 25 = Q 1. Аналогично P 40 = D 4 = K 2; P 70 = D 7. Следовательно, достаточно только знать как найти процентили, чтобы определить любые требующиеся квантили.








