 2020-10-10
2020-10-10 182
182Оперативной памяти может не хватать. Число размеров (точнее, хеш-функция) подбирается так, чтобы максимальный раздел таблицы R помещался в оперативной памяти.
При таком подходе после хеширования таблиц R и S все разделы сохраняются на диске.
Алгоритм:
- подбирается хеш-функция;
- хеширование таблицы;
- раздел R 0 целиком читается в оперативную память;
- в оперативную память поблочно читается раздел S 0;
- для каждой записи раздела S 0 значение атрибута a сравнивается со значением атрибута соединения в разделе R 0;
- считываются следующие разделы (R 1, R 2 и так далее).
Отличие от методов NLJ и SMJ
Метод хешированного соединения имеет важную особенность. В методах NLJ или SMJ соединяемые таблицы должны уже храниться на сервере перед выполнением соединения. А в этом методе соединение таблиц может выполняться асинхронно, по мере поступления записей с других серверов.
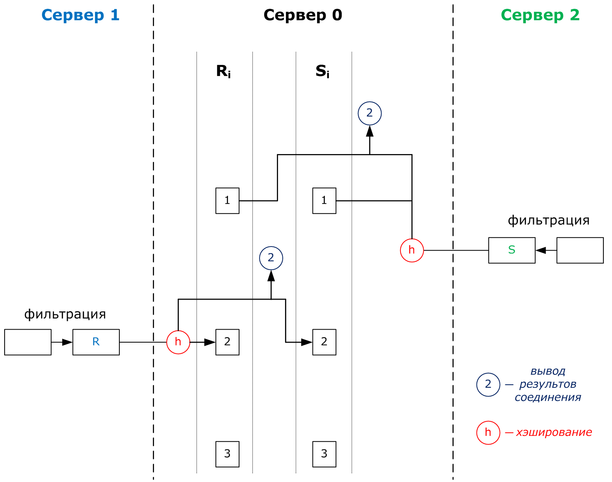
На серверах 1 и 2 выполняются подзапросы, а на сервере 0 выполняется соединение.
Предположим, с сервера 2 на сервер 0 поступила очередная запись из таблицы S. При этом СУБД на сервере 0 выполняет следующие действия:
- вычисляется хеш-функция для атрибута соединения;
- значение атрибута соединения сравнивается со значениями атрибутов соединения из раздела R 1. Если есть совпадения, то выводятся результаты соединения;
- запись сохраняется в разделе Si.
- и так далее.
Лекция №14 - Оценки (продолжение)
Оптимизация SQL-запросов
Физический план
Методы соединения таблиц
Число кортежей, блоков и мощности атрибутов в соединениях
Справедливы для NLJ, SMJ и HJ.
1) количество кортежей в соединении:
T (Q 1⋈ Q 2)= T (Q 1)⋅ T (Q 2) max (I (Q 1, a), I (Q 2, a))
2) числов блоков:
B (Q 1⋈ Q 2)=⌈ T (Q 1⋈ Q 2) JOIN ⌉ - верхние неполные квадратные скобки означают округление с избытком;
3) мощности атрибутов:
· атрибутов (a) в результирующей таблице:
I (Q 1⋈ Q 2, a)= min (I (Q 1, a), I (Q 2, a))
· остальных атрибутов (b):
два варианта:
· I (Q 1⋈ Q 2, b)= min (T (Q 1⋈ Q 2, I (Q 1, b)), если b - атрибут таблицы Q 1;
· I (Q 1⋈ Q 2, b)= min (T (Q 1⋈ Q 2, I (Q 2, b)), если b - атрибут таблицы Q 2.
Алгоритмы для поиска физического плана
Алгоритмы описываются на псевдоязыке с заимствованиями из C++:
- комментарии обозначаются косыми:
// камент
- обращение к полям структуры через точку:
структура.поле
Алгоритм поиска физического плана с минимальной стоимостью (для левостороннего дерева)
Вход: логический план выполнения запроса с таблицами R 1.. Rn (декартово соединение таблиц).
Выход: квазиоптимальный (потому что рассматриваем левосторонние деревья) план выполнения запроса.
@НАЧАЛО АЛГОРИТМА
ДЛЯ i =1, n
AccessPlan (Ri); // определение параметров подзапроса Qi =Π Ai (Σ fi (Ri)).
КОНЕЦ ДЛЯ
// поиск оптимального плана
ДЛЯ i =2, n
ДЛЯ всех подмножеств P ⊂ Q 1.. Qn,
// для i =2
// P =(Q 1, Q 2), P =(Q 2, Q 3), P =(Q 1, Q 3)
// для i =3
// P =(Q 1, Q 2, Q 3) и так же все варианты комбинаций
ДЛЯ всех таблиц Qj ∈ P
JoinPlan (P − Qj, Qj) // (P − Qj)⋈ Qj
КОНЕЦ ДЛЯ
КОНЕЦ ДЛЯ
КОНЕЦ ДЛЯ
// вывод оптимального плана
OptPlanReturn (Q 1.. Qn)
@КОНЕЦ АЛГОРИТМА
Массив структур
Процедуры из алгоритма выше:
- AccessPlan ();
- JoinPlan ();
- OptPlanReturn ().
Процедуры алгоритма работают с массивом структур. Формат экземпляра структуры:
| W | X | Y | Z | ZIO | V |
W:
если мощность W >1, то W ⊂ Qi, W = X ⋃ Y;
если мощность W =1, то W - это имя таблицы {Q_i}}}.
X:
X ⊂ Qi, которые были использованы в качестве левого аргумента соединения.
Y:
имя таблицы Qi, которая была использована в качестве правого аргумента соединения. Если мощность W =1, то X и Y пустые.
Z:
если W >1, Z - текущая стоимость выполнения плана, включающая стоимость выполнения подзапросов и промежуточных соединений;
если W =1, Z - оценка времени выполнения(?) Qi.
ZIO:
составляющая Z, касающаяся ввода/вывода.
V:
опции. Включает в себя:
1) число записей:
· если мощность W >1, то T (W) - число прогнозируемых записей;
· если мощность W =1, то T (Qi) - оценка числа записей в подзапросе;
2) B (W) - прогнозируемое число блоков;
3) I (W, Ai) - мощности атрибутов, по которым было выполнено или выполняется соединение;
4) идентификатор:
· если мощность W >1, то k - идентификатор метода соединения таблиц;
· если мощность W =1, то k - идентификатор метода выбора записей из исходных таблиц.
AccessPlan()
Вход: Ri - имя исходной таблицы.
Выход: str [ i ] - заполненный экземпляр структуры (описанной выше).
@НАЧАЛО АЛГОРИТМА
// оценка стоимости выбора записей из Ri для различных методов
// j =1 - TableScan
// j =2 - IndexScan
ДЛЯ i =1,2
Cj = CCPU + CI / O // для разных j разные формулы из прошлых лекций
КОНЕЦ ДЛЯ
// определение оптимального метода выбора записей из Ri
С= min (C 1, C 2) // здесь C = Ck
// заполнение экземпляра str [ i ]
str [ i ]=
{
Qi, ∅, ∅ // W, X, Y
C, CI / Ok // Z, ZIO
T (Qi), B (Qi), min (T (Qi), I (Ri, Ai)), k // V
}
@КОНЕЦ АЛГОРИТМА
JoinPlan()
Вход: R =(P − Qj), S = Q.
Выход: str [ n ].
@НАЧАЛО АЛГОРИТМА
1)
// поиск в массиве структур str [] номеров экземпляров m 1 и m 2, для которых str [ m 1]. W = R и str [ m 2]. W = S
// оценка стоимости соединения для различных методов
// если i =1, то NLJ
// если i =2, то SMJ
// если i =3, то HJ
// k - выбор оптимального из этих трёх
2)
ДЛЯ i =1,3
Ci = CCPUi + CI / Oi // для разных i разные формулы из предыдущих лекций
КОНЕЦ ДЛЯ
C = min (C 1, C 2) // стоимость соединения R и S
C = str [ m 1]. Z + str [ m 2]. Z + C
3)
// поиск str [ n ]. W = P
// а) если такого экземпляра не существует, то заполнить очередной пустой экземпляр n.
// б) если такой экземпляр найден, то сравнить стоимость выполнения плана. И если str [ n ]. Z > C, то перезаписать экземпляр n.
str [ n ]=
{
P, R, S // W, X, Y
C, CI / Ok // Z, ZIO
T (P), B (P), I (P, Ai) i, k // V
}
@КОНЕЦ АЛГОРИТМА
OptPlanReturn()
Вход: список таблиц Qi = Q 1.. Qn
Выход: вывод оптимального плана.
@НАЧАЛО АЛГОРИТМА
1)
// поиск в массиме структур str [] экземпляра, который str [ i ]. W = Q
печать(Q, " = ", str [ i ]. X, " ⋈ ", str [ y ]. Y, " метод ", str [ i ]. V. k)
2)
// если поле str [ i ]. X пусто, то выйти из алгоритма
// иначе рекурсивно вызываем сами себя, OptPlanReturn (str [ i ]. X) // вывод оптимального плана для левого аргумента соединения
3)
OptPlanReturn (str [ i ]. Y) // вывод метода выбора записей из правого аргумента соединения
@КОНЕЦ АЛГОРИТМА








