 2014-02-02
2014-02-02 2485
2485Темы: нормализация баз данных, средства ускоренного доступа к данным.
1. Нормализация баз данных
Одни и те же данные могут группироваться в таблицы (отношения) различными способами. Группировка атрибутов в отношениях должна быть рациональной, т. е. минимизирующей дублирование данных и упрощающей процедуры их обработки и обновления. Устранение избыточности данных является одной из важнейших задач проектирования баз данных и обеспечивается нормализацией.
Нормализация таблиц (отношений) — это формальный аппарат ограничений на формирование таблиц (отношений), который позволяет устранить дублирование, обеспечивает непротиворечивость хранимых в базе данных, уменьшает трудозатраты на ведение (ввод, корректировку) базы данных. Процесс нормализации заключается в разложении (декомпозиции) исходных отношений БД на более простые отношения. Каждая ступень этого процесса приводит схему отношений в последовательные нормальные формы. Для каждой ступени нормализации имеются наборы ограничений, которым должны удовлетворять отношения БД. Нормализация позволяет удалить из таблиц базы избыточную неключевую информацию.
Процесс нормализации основан на понятии функциональной зависимости атрибутов: атрибут 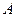 зависит от атрибута
зависит от атрибута 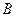 (
(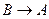 ), если в любой момент времени каждому значению атрибута соответствует не более одного значения атрибута .
), если в любой момент времени каждому значению атрибута соответствует не более одного значения атрибута .
Зависимость, при которой каждый неключевой атрибут зависит от всего составного ключа и не зависит от его частей, называется полной функциональной зависимостью. Если атрибут зависит от атрибута , а атрибут зависит от атрибута  (
(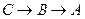 ), но обратная зависимость отсутствует, то зависимость от называется транзитивной.
), но обратная зависимость отсутствует, то зависимость от называется транзитивной.
Общее понятие нормализации подразделяется на несколько «нормальных форм».
Информационный объект (или сущность) находится в первой нормальной форме (1НФ), когда все его атрибуты имеют единственное значение. Если в каком-либо атрибуте есть повторяющиеся значения, объект (сущность) не находится в 1НФ, и упущен еще по крайней мере один информационный объект (еще одна сущность).
Например, отношение
ПРЕДМЕТ (Код предмета, Название, Цикл, Объем часов, Преподаватели)
не находится в 1НФ, так как атрибут Преподаватели подразумевает возможность присутствия нескольких фамилий преподавателей в записи, относящейся к какому-то конкретному предмету, что соответствует участию нескольких преподавателей в ведении одной дисциплины Переведем атрибут с повторяющимися значениями в новую сущность, назначим ей первичный ключ (Код преподавателя) и свяжем с исходной сущностью ссылкой на первичный ключ последней (Код предмета). В результате получим две сущности, причем во вторую сущность ПРЕПОДАВАТЕЛЬ добавлены характеризующие ее атрибуты:
ПРЕДМЕТ (Код предмета, Название, Цикл, Объем часов),
ПРЕПОДАВАТЕЛЬ (Код преподавателя, Фамилия И О, Должность, Оклад, Адрес, Код предмета)
Полученные выражения соответствуют случаю, когда несколько преподавателей могут вести один предмет, но каждый преподаватель не может вести более одной дисциплины. А если учесть, что на самом деле один лектор может читать более одной дисциплины, так же как одну и ту же дисциплину могут читать несколько лекторов, необходимо отказаться от жесткой привязки преподавателя к предмету в сущности ПРЕПОДАВАТЕЛЬ, создав дополнительную сущность ИЗУЧЕНИЕ, которая будет показывать, как связаны между собой пре подаватели и предметы:
ПРЕДМЕТ (Код предмета, Название, Цикл, Объем часов),
ПРЕПОДАВАТЕЛЬ (Код преподавателя, Фамилия И О, Должность, Оклад, Адрес),
ИЗУЧЕНИЕ (Код предмета, Код преподавателя)
Информационный объект находится во второй нормальной форме (2НФ), если он уже находится в первой нормальной форме, и каждый неидентифицирующий (описательный) атрибут зависит от всего уникального идентификатора информационного объекта. Если некий атрибут не зависит полностью от уникального идентификатора сущности, значит, он внесен ошибочно и должен быть удален. Нормализация в этом случае производится путем нахождения существующего информационного объекта, к которому данный атрибут относится, или созданием нового информационного объекта, в который атрибут должен быть помещен.
Возвращаясь к предыдущему примеру, замечаем что атрибут Цикл в сущности ПРЕДМЕТ, характеризующий принадлежность предмета к циклу гуманитарных, естественно-научных, общепрофессиональных или специальных дисциплин, не полностью зависит от уникального идентификатора Код предмета, так как разные предметы могут иметь одно и то же значение атрибута Цикл. Перенесем атрибут в новую сущность ЦИКЛ и получим четыре взаимосвязанные сущности
ПРЕДМЕТ (Код предмета, Название, Объем часов, Код цикла),
ЦИКЛ (Код цикла, Название цикла),
ПРЕПОДАВАТЕЛЬ (Код преподавателя, Фамилия И О, Должность, Оклад, Адрес),
ИЗУЧЕНИЕ (Код предмета, Код преподавателя)
Информационный объект (или сущность) находится в третьей нормальной форме (ЗНФ), если он уже находится во второй нормальной форме и ни один описательный атрибут не зависит от каких-либо других описательных атрибутов. Атрибуты, зависящие от других неидентифицирующих атрибутов, нормализуются путем перемещения зависимого атрибута и атрибута, от которого он зависит, в новый информационный объект.
В данном примере неключевые атрибуты Должность и Оклад находятся в транзитивной зависимости. В чем опасность такой зависимости? Во-первых, несколько человек могут работать в одной и той же должности. При изменении должностного оклада в этом случае нужно будет менять данные в каждой записи, содержащей эту должность. В рассмотренной ситуации нужно создать новую сущность ДОЛЖНОСТЬ с находящимися в транзитивной зависимости атрибутами — Название должности и Оклад и сделать ссылку от сущности ПРЕПОДАВАТЕЛЬ на сущность ДОЛЖНОСТЬ:
ПРЕДМЕТ (Код предмета, Название, Объем часов, Код цикла),
ЦИКЛ (Код цикла, Название цикла),
ПРЕПОДАВАТЕЛЬ (Код преподавателя, Фамилия И О., Код должности, Адрес),
ДОЛЖНОСТЬ (Код должности, Название должности, Оклад),
ИЗУЧЕНИЕ (Код предмета, Код преподавателя)
2. Средства ускоренного доступа к данным
Чтобы пользователь чувствовал себя комфортно, время ожидания ответа на запрос к БД не должно превышать нескольких секунд. В связи с этим требованием специально разрабатываются методы ускорения выборки, позволяющие обойтись без полного перебора строк при выполнении реляционных операций модификации отношений и отбора данных.
Наибольший эффект дают метод индексирования и метод хеширования значений ключей отношения.
Индексирование — логическая сортировка строк таблицы. Оно заключается в создании вспомогательных файлов, содержащих упорядоченные списки значений ключей отношения со ссылками на строку отношения, в которой они находятся. Индексные файлы занимают дополнительную память, но резко ускоряют поиск, благодаря применению метода половинного деления. Для одного отношения может быть создано несколько индексов. Кроме того, можно создавать индекс для нескольких отношений, если они содержат одинаковые атрибуты, что позволяет ускорить выполнение операций соединения отношений.
Индексы позволяют находить строки, в которых значения ключевых полей совпадают с заданным значением или принадлежат заданному интервалу.
Хеширование (hashing) — использование хэш-функций, которые вычисляют вес строки таблицы по значению ее ключевых атрибутов. Результат вычисления хэш-функции — целое число в диапазоне физических номеров строк таблицы.
Идеальная хэш-функция должна давать разные значения весов для разных ключевых атрибутов. Но это не всегда возможно. На практике обычно используют простые хэш-функции, например, 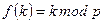 , где
, где 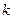 — целое число, первичный ключ отношения;
— целое число, первичный ключ отношения; 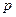 — простое целое число;
— простое целое число; 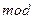 — операция, вычисляющая остаток при целочисленном делении. Если ключевой атрибут — строка символов, то для вычисления
— операция, вычисляющая остаток при целочисленном делении. Если ключевой атрибут — строка символов, то для вычисления 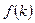 выбирается один из методов преобразования строки в число, например вычисление контрольной суммы.
выбирается один из методов преобразования строки в число, например вычисление контрольной суммы.
Для организации доступа к данным при хешировании создается таблица с пустыми строками, которая заполняется следующим образом:
• по первичному ключу новой строки вычисляется значение хэш-функции и результат трактуется, как номер строки в созданной таблице;
• если строка уже занята, производится проверка следующих строк по специальному алгоритму до тех пор, пока не будет обнаружено свободное место.
Аналогично производится поиск нужной строки:
• если после вычисления на месте в таблице, которое соответствует вычисленному значению, оказывается пустая строка, значит, искомой строки просто нет;
• иначе (строка занята);
• если значение ключа совпало с искомым, поиск заканчивается;
• • иначе (значение не совпало) — проверяются следующие строки до строки с нужным ключом — строка найдена или до пустой строки — строка отсутствует.
Хеширование используют для поиска строк по точному совпадению значения ключевого атрибута кортежа с нужным значением ключа.
Лекция 9 (Базы данных)

