 2014-02-02
2014-02-02 37371
37371Автор: преподаватель, Е.Б. Иванова, Доцент, Московский государственный университет. Тип материала: Конспект
Этапы проектирования баз данных.
Темы: этапы проектирования баз данных, проектирование базы данных на основе модели типа объект — отношение.
Перед созданием базы данных разработчик должен определить, изкаких таблиц должна состоять база данных, какие данные нужно поместить в каждую таблицу, как связать таблицы. Эти вопросы решаются на этапе проектирования базы данных.
В результате проектирования должна быть определена логическая структура базы данных, то есть состав реляционных таблиц, их структура и межтабличные связи.
Перед созданием базы данных необходимо располагать описанием выбранной предметной области, которое должно охватывать реальные объекты и процессы, определить все необходимые источники информации для удовлетворения предполагаемых запросов пользователей и определить потребности в обработке данных.
На основе такого описания на этапе проектирования базы данных определяются состав и структура данных предметной области, которые должны находиться в БД и обеспечивать выполнение необходимых запросов и задач пользователей. Структура данных предметной области может отображаться информационно-логической моделью. На основе этой модели легко создается реляционная база данных.
Этапы проектирования и создания базы данных определяются следующей последовательностью:
- построение информационно-логической модели данных предметной области;
- определение логической структуры реляционной базы данных;
- конструирование таблиц базы данных;
- создание схемы данных;
- ввод данных в таблицы (создание записей);
- разработка необходимых форм, запросов, макросов, модулей, отчетов;
- разработка пользовательского интерфейса.
В процессе разработки модели данных необходимо выделить информационные объекты, соответствующие требованиям нормализации данных, и определить связи между ними. Эта модель позволяет создать реляционную базу данных без дублирования, в которой обеспечивается однократный ввод данных при первоначальной загрузке и корректировках, а также целостность данных при внесении изменений.
При разработке модели данных могут использоваться два подхода. В первом подходе сначала определяются основные задачи, для решения которых строится база, выявляются потребности задач в данных и соответственно определяются состав и структура информационных объектов. При втором подходе сразу устанавливаются типовые объекты предметной области. Наиболее рационально сочетание обоих подходов. Это связано с тем, что на начальном этапе, как правило, нет исчерпывающих сведений обо всех задачах. Использование такой технологии тем более оправдано, что гибкие средства создания реляционных баз данных позволяют на любом этапе разработки внести изменения в базу данных и модифицировать ее структуру без ущерба для введенных ранее данных.
Процесс выделения информационных объектов предметной области, отвечающих требованиям нормализации, может производиться на основе интуитивного или формального подхода. Теоретические основы формального подхода были разработаны и полно изложены в монографиях по организации баз данных известного американского ученого Дж. Мартина.
При интуитивном подходе легко могут быть выявлены информационные объекты, соответствующие реальным объектам. Однако получаемая при этом информационно-логическая модель, как правило, требует дальнейших преобразований, в частности преобразования много-многозначных связей между объектами. При таком подходе возможны существенные ошибки, если отсутствует достаточный опыт. Последующая проверка выполнения требований нормализации обычно показывает необходимость уточнения информационных объектов.
Рассмотрим формальные правила, которые могут быть использованы для выделения информационных объектов:
- на основе описания предметной области выявить документы и их атрибуты, подлежащие хранению в базе данных;
- определить функциональные зависимости между атрибутами;
- выбрать все зависимые атрибуты и указать для каждого все его ключевые атрибуты, т. е. те, от которых он зависит;
- сгруппировать атрибуты, одинаково зависимые от ключевых атрибутов. Полученные группы зависимых атрибутов вместе с их ключевыми атрибутами образуют информационные объекты.
При определении логической структуры реляционной базы данных на основе модели каждый информационный объект адекватно отображается реляционной таблицей, а связи между таблицами соответствуют связям между информационными объектами.
В процессе создания сначала конструируются таблицы базы данных, соответствующие информационным объектам построенной модели данных. Далее может создаваться схема данных, в которой фиксируются существующие логические связи между таблицами. Эти связи соответствуют связям информационных объектов. В схеме данных могут быть заданы параметры поддержания целостности базы данных, если модель данных была разработана в соответствии с требованиями нормализации. Целостность данных означает, что в БД установлены и корректно поддерживаются взаимосвязи между записями разных таблиц при загрузке, добавлении и удалении записей в связанных таблицах, а также при изменении значений ключевых полей.
После формирования схемы данных осуществляется ввод непротиворечивых данных из документов предметной области.
На основе созданной базы данных формируются необходимые запросы, формы, макросы, модули, отчеты, производящие требуемую обработку данных базы и их представление.
С помощью встроенных средств и инструментов базы данных создается пользовательский интерфейс, позволяющий управлять процессами ввода, хранения, обработки, обновления и представления информации базы данных.
Проектирование базы данных на основе модели типа объект — отношение
Имеется целый ряд методик создания информационно-логических моделей. Одна из наиболее популярных в настоящее время методик при разработке моделей использует ERD (Entity-Relationship Diagrams). В русскоязычной литературе эти диаграммы называют «объект — отношение» либо «сущность — связь». Модель ERD была предложена Питером Пин Шен Ченом в 1976 г. К настоящему времени разработано несколько ее разновидностей, но все они базируются на графических диаграммах, предложенных Ченом. Диаграммы конструируются из небольшого числа компонентов. Благодаря наглядности представления они широко используются в CASE-средствах (Computer Aided Software Engineering).
Рассмотрим используемую терминологию и обозначения.
Сущность (Entity) — реальный либо воображаемый объект, имеющий существенное значение для рассматриваемой предметной области, информация о котором подлежит хранению.
Каждая сущность должна обладать уникальным идентификатором. Каждый экземпляр сущности должен однозначно идентифицироваться и отличаться от всех других экземпляров данного типа (сущности).
Каждая сущность должна обладать некоторыми свойствами:
- иметь уникальное имя; причем к этому имени должна всегда применяться одна и та же интерпретация (определение сущности). И наоборот: одна и та же интерпретация не может применяться к различным именам, если только они не являются псевдонимами;
- обладать одним или несколькими атрибутами, которые либо принадлежат сущности, либо наследуются ею через связь;
- обладать одним или несколькими атрибутами, которые однозначно идентифицируют каждый экземпляр сущности.
Сущность может быть независимой либо зависимой. Признаком зависимой сущности служит наличие у нее наследуемых через связь атрибутов (рис. 1.).
 |
Каждая сущность может обладать любым количеством связей с другими сущностями модели.
Связь (Relationship) — поименованная ассоциация между двумя сущностями, значимая для рассматриваемой предметной области. Одна из участвующих в связи сущностей — независимая, называется родительской сущностью, другая — зависимая, называется дочерней или сущностью-потомком. Как правило, каждый экземпляр родительской сущности ассоциирован с произвольным (в том числе нулевым) количеством экземпляров дочерней сущности. Каждый экземпляр сущности-потомка ассоциирован в точности с одним экземпляром сущности-родителя. Таким образом, экземпляр сущности-потомка может существовать только при существовании сущности-родителя.
Связи дается имя, выражаемое грамматическим оборотом глагола и помещаемое возле линии связи.
Имя каждой связи между двумя данными сущностями должно быть уникальным, но имена связей в модели не обязаны быть уникальными. Каждая связь имеет определение. Определение связи образуют соединением имени сущности-родителя, имени связи, выражения степени связи и имени сущности-потомка.
 |
Например, связь продавца с контрактом может быть определена следующим образом:
- продавец может получить вознаграждение за один или более Контрактов;
- контракт должен быть инициирован ровно одним Продавцом.
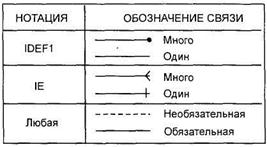
На диаграмме связь изображается отрезком (ломаной). Концы отрезка с помощью специальных обозначений (рис. 2) указывают степень связи. Кроме того, характер линии — штриховая или сплошная, указывает обязательность связи.
Атрибут — любая характеристика сущности, значимая для рассматриваемой предметной области. Он предназначен для квалификации, идентификации, классификации, количественной характеристики или выражения состояния сущности. Атрибут представляет тип характеристик (свойств), ассоциированных с множеством реальных или абстрактных объектов (людей, мест, событий, состояний, идей, пар предметов и т. д.) (рис. 3).
Экземпляр атрибута — это определенная характеристика конкретного экземпляра сущности. Экземпляр атрибута определяется типом характеристики (например, «Цвет») и ее значением (например, «лиловый»), называемым значением атрибута. В ER-модели атрибуты ассоциируются с конкретными сущностями. Каждый экземпляр сущности должен обладать одним конкретным значением для каждого своего атрибута.
 |
Атрибут может быть либо обязательным, либо необязательным. Обязательность означает, что атрибут не может принимать неопределенных значений (null values). Атрибут может быть либо описательным (т. е. обычным дескриптором сущности), либо входить в состав уникального идентификатора (первичного ключа).
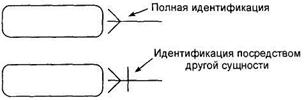
Уникальный идентификатор — это атрибут или совокупность атрибутов и/или связей, однозначно характеризующая каждый экземпляр данного типа сущности. В случае полной идентификации экземпляр данного типа сущности полностью идентифицируется своими собственными ключевыми атрибутами, в противном случае в идентификации участвуют также атрибуты другой сущности — родителя.
Характер идентификации отображается в диаграмме на линии связи (рис. 4).

Каждый атрибут идентифицируется уникальным именем, выражаемым грамматическим оборотом существительного, описывающим представляемую атрибутом характеристику. Атрибуты изображаются в виде списка имен внутри блока ассоциированной сущности, причем каждый атрибут занимает отдельную строку. Атрибуты, определяющие первичный ключ, размещаются наверху списка и выделяются знаком «#».
Каждая сущность должна обладать хотя бы одним возможным ключом. Возможный ключ сущности — это один или несколько атрибутов, чьи значения однозначно определяют каждый экземпляр сущности. При существовании нескольких возможных ключей один из них обозначается в качестве первичного ключа, а остальные — как альтернативные ключи.
В настоящее время на основе подхода Чена создана методология IDEF1X, которая разработана с учетом таких требований, как простота изучения и возможность автоматизации. IDEFlX-диаграммы используются рядом распространенных CASE-средств (в частности, ERwin, Design/IDEF).
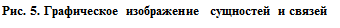
 Сущность в методологии IDEF1X называется независимой от идентификаторов или просто независимой, если каждый экземпляр сущности может быть однозначно идентифицирован без определения его отношений с другими сущностями. Сущность называется зависимой от идентификаторов или просто зависимой, если однозначная идентификация экземпляра сущности зависит от его отношения к другой сущности (рис. 5).
Сущность в методологии IDEF1X называется независимой от идентификаторов или просто независимой, если каждый экземпляр сущности может быть однозначно идентифицирован без определения его отношений с другими сущностями. Сущность называется зависимой от идентификаторов или просто зависимой, если однозначная идентификация экземпляра сущности зависит от его отношения к другой сущности (рис. 5).
Каждой сущности присваивается уникальное имя и номер, разделяемые косой чертой «/» и помещаемые над блоком.
Если экземпляр сущности-потомка однозначно определяется своей связью с сущностью-родителем, то связь называется идентифицирующей, в противном случае — неидентифицируюшей.
Идентифицирующая связь между сущностью-родителем и сущностью-потомком изображается сплошной линией. На рис. 5: №2 — зависимая сущность, Связь 1 — идентифицирующая связь. Сущность-потомок в идентифицирующей связи является зависимой от идентификатора сущностью. Сущность-родитель в идентифицирующей связи может быть как независимой, так и зависимой от идентификатора сущностью (это определяется ее связями с другими сущностями).
Штриховая линия изображает неидентифицирующую связь. На рис. 5: №4 — независимая сущность, Связь 2 — неидентифицирующая связь. Сущность-потомок в неидентифицируюшей связи будет независимой от идентификатора, если она не является также сущностью-потомком в какой-либо идентифицирующей связи.
Связь может дополнительно определяться с помощью указания степени или мощности (количества экземпляров сущности-потомка, которое может существовать для каждого экземпляра сущности-родителя).
В IDEF1X могут быть выражены следующие мощности связей:
- каждый экземпляр сущности-родителя может иметь ноль, один или более связанных с ним экземпляров сущности-потомка;
- каждый экземпляр сущности-родителя должен иметь не менее одного связанного с ним экземпляра сущности-потомка;
- каждый экземпляр сущности-родителя должен иметь не более одного связанного с ним экземпляра сущности-потомка;
- каждый экземпляр сущности-родителя связан с некоторым фиксированным числом экземпляров сущности-потомка.

Мощность связи обозначается, как показано на рис. 6 (мощность по умолчанию — N).
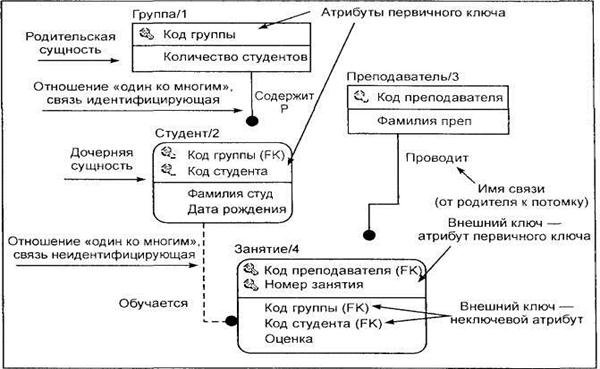 |

Атрибуты изображаются в виде списка имен внутри блока сущности. Атрибуты, определяющие первичный ключ, размещаются наверху списка и отделяются от других атрибутов горизонтальной чертой (рис. 7).
В результате получается информационно-логическая модель, которая используется рядом распространенных CASE-средств, таких, как ERwin, Design/IDEF. В свою очередь, CASE-технологии имеют высокие потенциальные возможности при разработке баз данных и информационных систем, а именно, увеличение производительности труда, улучшение качества программных продуктов, поддержка унифицированного и согласованного стиля работы.
Сущности могут иметь также внешние ключи (Foreign Key). При идентифицирующей связи они используются в качестве части или целого первичного ключа, при неидентифицирующей — служат неключевыми атрибутами. В списке атрибутов внешний ключ отмечается буквами FK в скобках.

