 2014-02-02
2014-02-02 6661
6661При проектировании реляционной базы данных вам необходимо решить вопрос о наиболее эффективной структуре данных. Приведение модели к требуемому уровню нормальной формы является основой построения реляционной базы данных. В процессе нормализации элементы данных группируются в таблицы, представляющие объекты и их взаимосвязи. Теория нормализации основана на том, что определенный набор таблиц обладает лучшими свойствами при включении, модификации и удалении данных, чем одна таблица Основные цели, которые при этом преследуются:
- Обеспечить быстрый доступ к данным в таблицах.
- Исключить ненужное повторение данных, которое может являться причиной ошибок при вводе и нерационального использования дискового пространства вашего компьютера.
- Обеспечить целостность данных таким образом, чтобы при изменении одних объектов автоматически происходило соответствующее изменение связанных с ними объектов.
Процесс уменьшения избыточности информации в базе данных называется нормализацией. В теории нормализации баз данных разработаны достаточно формализованные подходы по разбиению данных, обладающих сложной структурой, среди нескольких таблиц. Эти вопросы детально освещаются в специальной литературе. Мы остановимся на некоторых практических аспектах нормализации таблиц, не рассматривая их теоретическое обоснование. Нормализация информационной модели выполняется в несколько этапов. Теория нормализации баз данных оперирует с пятью нормальными формами таблиц (от первой до пятой включительно). Эти формы предназначены для уменьшения избыточной информации от первой до пятой нормальной формы. Поэтому каждая последующая нормальная форма должна удовлетворять требованиям предыдущей формы и некоторым дополнительным условиям. При практическом проектировании баз данных четвертая и пятая формы, как правило, не используются, поэтому мы ограничимся рассмотрением первых трех нормальных форм. Отношения обладают следующими свойствами
Отношение называется нормализованным, если каждая компонента кортежа является простым, атомарным значением, не состоящим из группы значений. Это не позволяет заменять значение атрибута другим: отношением (что привело бы к сетевому или иерархическому отношению).
Нормализованное отношение представляется в виде личной структуры. Имя таблицы (соответствует имени отношения, имена столбцов - именам атрибутов, а строки таблицы - кортежам.
Упорядочение кортежей теоретически несущественно, однако оно может влиять на эффективность, доступа к кортежам.
Все строки (кортежи) отношения должны быть различными.
В отношении могут существовать несколько одиночных или составных атрибутов, которые однозначно идентифицируют кортеж отношения. Такие атрибуты называются возможными ключами. Один из них выбирается в качестве первичного ключа для обеспечения доступа к кортежам.
Реляционная база данных, является совокупностью изменяющихся во времени нормализованных (отношений различных степеней, которые могут быть связаны Друг с другом через общие домены.
Замечание. Различие между математическим отношением и отношением базы данных состоит в том, что состояние последнего может меняться со временем при добавлении и/или удалении отдельных кортежей. Число атрибутов, входящих в отношение, называется степенью отношения, а число кортежей отношения - кардинальным числом или мощностью отношения. Навигация по отношениям базы данных осуществляется путем их соединения с помощью атрибутов, определенных над общими или сравнимыми доменами. Операция соединения включает сравнение значений «атрибутов соединения» кортежей одного отношения (исходного) с кортежами другого отношения (щелевого) и выборку пар кортежей, удовлетворяющих сравнению.
Для демонстрации проектирования нормализованной базы данных, рассмотрим таблицу «ПУТЕВЫЕ ЛИСТЫ», которая содержит информацию о водителях, автомобилях, выходах автомобилей на линию и имеет следующий набор полей (Таблица 5.4.1):
| № п/п | Наименование поля | Тип поля |
| № путевого листа | Текстовый(6) | |
| Дата выезда | Дата | |
| Организация | Текстовый(30) | |
| Фамилия | Текстовый(15) | |
| Имя | Текстовый(10) | |
| Отчество | Текстовый(15) | |
| Подразделение | Текстовый(12) | |
| Группа персонала | Текстовый(5) | |
| Домашний адрес | Текстовый(30) | |
| Марка автомобиля | Текстовый(12) | |
| Госномер | Текстовый(9) | |
| Норма расхода бензина | Числовой | |
| Дата постановки на учет | Дата | |
| Показания спидометра при выезде | Числовой | |
| Показания спидометра при возвращении | Числовой | |
| Пробег по городу | Числовой | |
| Пробег по трассе | Числовой | |
| Пробег по крупному городу | Числовой | |
| Остаток бензина при выезде | Числовой | |
| Заправка | Числовой | |
| Остаток бензина при возвращении | Числовой |
Таблица 5.4.1 Структура таблицы
Таблицу 5.4.1 можно рассматривать как однотабличную базу данных.
Заметим, что каждый водитель может за месяц выйти на линию до 24-х раз. А, следовательно, и все сведения о водителе будут повторяться. Такая структура данных является причиной следующих проблем, возникающих при работе с базой данных:
- Придется тратить значительное время на ввод повторяющихся данных. Например, для всех заказов, сделанных одним из покупателей, вам придется каждый раз вводить одни и те же данные о водителях;
- При изменении адреса или телефона водителя необходимо корректировать все записи, содержащие сведения об этом покупателя.
- Наличие повторяющейся информации приведет к неоправданному увеличению размера базы данных. В результате снизится скорость выполнения запросов. Кроме того, повторяющиеся данные нерационально используют дисковое пространство компьютера.
- Любые внештатные ситуации потребуют от значительного времени для получения требуемой информации. Например, при многократном вводе повторяющихся данных возрастает вероятность ошибки. При больших размерах таблиц поиск ошибок будет занимать значительное время.
Первая нормализованная форма таблицы.
f Данные, представленные в виде двумерной таблицы, являются первой нормальной формой реляционной модели данных.
Таблица, структура которой приведена в таблице 5.4.1, является ненормализованной; Таблица в первой нормальной форме должна удовлетворять следующим требованиям:
1. Таблица не должна иметь повторяющихся записей.
2. В таблице должны отсутствовать повторяющиеся группы полей.
3. Строки должны быть не упорядочены.
4. Столбцы должны быть не упорядочены.
Для удовлетворения условия 1 каждая таблицы должна иметь уникальный индекс. Таблица Путевые листы не содержит уникального индекса, что допускает наличие в таблице повторяющихся записей. Для выполнения условия 1 создадим уникальный индекс, содержащий поле «ТабНомер» для связывания таблиц 5.4.2 и 5.4.3
Требование 2 постулирует устранение повторяющихся групп. Создадим две таблицы со следующей структурой:
| Список водителей | Путевые листы | |
 ТабНомер ТабНомер | ТабНомер | |
 Фамилия Фамилия | ГосНомер | |
| Имя | № путевого листа | |
| Отчество | Дата выезда | |
| Подразделение | Показания спидометра при выезде | |
| Группа персонала | Показания спидометра при возвращении | |
| Домашний адрес | Пробег по городу | |
| Организация | Пробег по трассе | |
| Пробег по крупному городу | ||
| Остаток бензина при выезде | ||
| Таблица 5.4.2 | Заправка | |
| Остаток бензина при возвращении | ||
| Таблица 5.4.3 |
| Справочник автомобилей |
| Марка автомобиля |
| Госномер |
| Норма расхода бензина |
| Дата постановки на учет |
| Таблица 5.4.4 |
Для таблицы 5.4.2(Список водителей) определим первичный ключ «ТабНомер»
Вторая нормальная форма.
f Отношение задано во второй нормальной форме, если оно является отношением в первой нормальной форме и каждый атрибут, не являющийся первичным в этом отношении, полностью зависит от любого возможного ключа этого отношения.
Из приведенного выше определения следует, что понятие второй нормальной формы применимо только к таблицам, имеющим составной индекс. Таблица «Путевые листы» не является таблицей во второй нормальной форме, так как любая запись не определяется однозначно набором полей «ТабНомер» и «ГосНомер». В таблице «Список водителей» поля «Организация», «группа персонала», «Фамилия», «Имя», «Отчество» также однозначно не определяется набором полей. В состав набора, кстати, входит и ключевое поле «ТабНомер».
Третья нормальная форма.
f Отношение задано в третьей нормальной форме, если оно задано во второй нормальной форме и каждый атрибут этого отношения, не являющийся первичным, не транзитивно зависит от каждого возможного ключа этого отношения.
Сведение таблицы к третьей нормальной форме предполагает разделение таблицы с целью помещения в отдельную таблицу (или несколько таблиц) столбцов, которые не зависят от полного ключа. В результате такого разбиения каждое из неключевых полей должно оказаться независимым от какого-либо другого неключевого поля.
Создадим еще три таблицы:
| Группа персонала | Организация | Паспортные данные | ||
| КодГруппы | КодОрг | ТабНом | ||
| Наименование | Наименование | № паспорта | ||
| Таблица 5.4.5 | ФИО руководителя | Серия | ||
| Подразделения | № телефона | Фамилия | ||
| КодПодр | Таблица 5.4.6 | Имя | ||
| Наименование | Отчество | |||
| Таблица 5.4.7 | Адрес | |||
| Таблица 5.4.8 |
Окончательно состав таблиц, их структура и связи между ними будут выглядеть так (Рис 5.4.1)
После определения структуры таблиц, отношений между ними и совпадающих полей, которые будут использованы для связывания от дельных таблиц, мы готовы приступить к созданию многотабличной базы данных
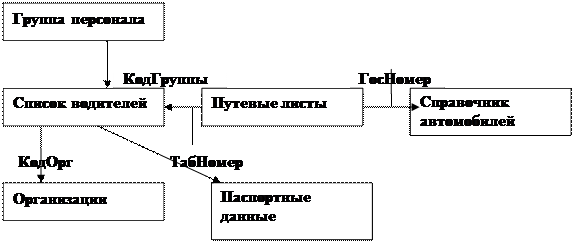
Рис 5.4.1 Взаимосвязи между таблицами

