 2014-02-04
2014-02-04 660
660Г л а в а 6. АДАПТИВНЫЙ БАЙЕСОВ ПОДХОД
Основная идея адаптивного байесова подхода заключается в следующем. Пусть имеется существенная априорная неопределенность и статистическом описании данных наблюдения х, параметров l, влияющих на последствия принимаемых решений, или того и другого. Эта неопределенность не позволяет использовать обычный байесов формализм: найти для любого возможного правила решения величину среднего риска R(u(х)), величину апостериорного риска R(u, x) и определить положение минимума апостериорного риска по u, то есть найти значение u = u0(x), минимизирующее апостериорный риск и представляющее собой оптимальное байесово решение. Нужно подчеркнуть, что это связано именно с незнанием, а не с существованием; на самом деле для любых конкретных условий в пределах имеющейся априорной неопределенности существуют вполне определенные, но неизвестные нам истинные значения R(u(х)) = Rист(u(х)) для всех u(х), значения R(u,х) =Rист(u,х) для всех u и х и оптимальное решение u0(х), обращающее в минимум Rист(u, х).
Попытаемся, тем не менее, использовать тот порядок, который принят при нахождении байесова правила решения. (Как уже не раз подчеркивалось, главным его элементом является нахождение минимума апостериорного риска по u и положения этого минимума.) Чтобы реализовать это намерение, используем часть сведений, содержащихся в совокупности данных наблюдения х, для оценки истинной величины апостериорного риска с тем, чтобы получить его приближенное значение для всех возможных решений и или хотя бы (что наиболее существенно) в окрестности его минимума. После того, как такая оценка получена, остается только воспользоваться стандартными рецептами для нахождения байесова решения, минимизировав вместо истинного оценочное значение апостериорного риска.
Если при этом оставшаяся после оценки апостериорного риска часть сведений из общей совокупности данных наблюдения х достаточна для получения нетривиального решения (минимум оценочного значения апостериорного риска по и достигается для значения и, неодинакового при разных х), то мы действительно получим решение задачи синтеза в условиях априорной неопределенности. Если же, кроме того, использованная нами оценка апостериорного риска является состоятельной и близка к его истинному значению, то найденное таким способом решение будет достаточно близко к оптимальному байесову решению при отсутствии априорной неопределенности, когда статистические описания х, l и истинные значения среднего и апостериорного риска для всех u известны полностью.
Проиллюстрируем эту идею двумя элементарными примерами.
Пример 1.Пусть имеется двухальтернативная задача, о которой уже шла речь в п. 4.3.2, то есть требуется принять решение u = 1 или u = 2 по данным наблюдения x = {x1,..., хn, хn+1}, состоящим из совокупности (n+1)-й независимо распределенных величин, для которой плотность вероятности имеет вид (4.3.3)
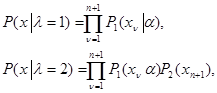
где известно все, кроме параметра 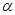 , вносящего априорную неопределенность в статистическое описание данных наблюдения. Пусть также заданы функции потерь g(u, l) = gik (i, k = l, 2) и априорные вероятности значений l - р(l = 1) = р1, р(l = 2) = р2 = 1 – р1. Апостериорный риск в данной задаче
, вносящего априорную неопределенность в статистическое описание данных наблюдения. Пусть также заданы функции потерь g(u, l) = gik (i, k = l, 2) и априорные вероятности значений l - р(l = 1) = р1, р(l = 2) = р2 = 1 – р1. Апостериорный риск в данной задаче
 (6.1.1)
(6.1.1)
зависит от неизвестного параметра а, что не дает возможности сравнить его значения для i = 1,2 и выбрать решение. Чтобы проделать требуемую минимизацию, нужно каким-то образом «узнать» значение а и подставить его в выражение (6.1.1). «Узнать» - это значит получить оценку для а по имеющимся данным наблюдения. В данном случае такая возможность имеется, поскольку все данные наблюдения, кроме хn+1, вообще не входят в выражение (6.1.1) для апостериорного риска и оказались как бы ненужными.
Используем эти данные - совокупность значений {x1,..., хn, хn+1} - для нахождения оценки 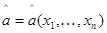 неизвестного параметра . Как уже не раз подчеркивалось, хорошей оценкой - асимптотически (а иногда и строго) эффективной, асимптотически нормально распределенной и сходящейся к истинному значению с увеличением объема данных, использованных для ее нахождения (в данном случае числа n наблюдений x1,..., хn), является оценка максимального правдоподобия. В соответствии с этим возьмем в качестве а оценку максимального правдоподобия *, определенную из уравнения
неизвестного параметра . Как уже не раз подчеркивалось, хорошей оценкой - асимптотически (а иногда и строго) эффективной, асимптотически нормально распределенной и сходящейся к истинному значению с увеличением объема данных, использованных для ее нахождения (в данном случае числа n наблюдений x1,..., хn), является оценка максимального правдоподобия. В соответствии с этим возьмем в качестве а оценку максимального правдоподобия *, определенную из уравнения
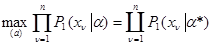 ,
,
и подставим ее в выражение (6.1.1) для использования величины Ri(xn+1,a*) (i=l,2) в качестве оценок неизвестных истинных значений апостериорного риска. После этого задача выбора решения становится вполне определенной и аналогично случаю отсутствия априорной неопределенности (известно) получим
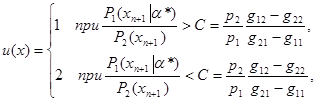 (6.1.2)
(6.1.2)
Если величина отклонения |* - | мала, то множество Х*n+1 значений хn+1, удовлетворяющих неравенству
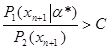 ,
,
мало отличается от множества Х0n+1 значений хn+1 , определяемого неравенством
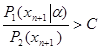 ,
,
которое является областью принятия решения u = 1 при отсутствии априорной неопределенности - известном значении . Поэтому вероятностные меры этих множеств относительно любого распределения вероятности xn+1 (в том числе распределений с плотностями Р2(хn+1) и Р1 (xn+1|)) отличаются друг от друга на величину, стремящуюся к нулю при * ® . Это означает, что условные и средние риски для решения u(х) из (6.1.2) и для оптимального решения при известном значении а также мало отличаются друг от друга и, следовательно, правило решения (6.1.2) является хорошим приближением к абсолютно оптимальному байесову правилу решения с полностью известным статистическим описанием.
Чтобы показать, что эти качественные рассуждения должны вызывать доверие, еще больше конкретизируем наш пример и дадим количественную оценку степени приближения правила решения (6.1.2) к оптимальному байесову. Пусть
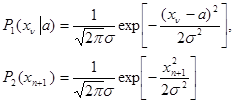
и пусть для определенности истинное значение > 0 и, кроме того, g11 = g22 = 0, g12 = g21 = 1, p1 = p2 = 1/2, C = 1. Тогда байесово правило решения
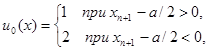 (6.1.3)
(6.1.3)
а правило (6.1.2) приводится к тому же виду с заменой на оценочное значение 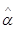 . Если в качестве последнего взять оценку максимального правдоподобия, то
. Если в качестве последнего взять оценку максимального правдоподобия, то
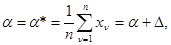
где отклонение D является случайной величиной с нулевым математическим ожиданием и дисперсией М{D2} = s2/n. Тогда множества X°n+1 и Х*n+1 определяются следующим образом:
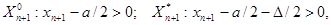
то есть различаются между собой на интервал [a/2, а/2 + D/2] при D > 0 или [а/2 + D/2, а/2] при D < 0, длина, которого D/2 является случайной величиной, порожденной случайностью {х1,.., хn}; в среднем (по ансамблю значений {х1,.., хn}) равна нулю и имеет среднеквадратичное значение а/2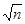 , стремящееся к нулю при увеличения n. Таким образом, вероятностные меры множеств X°n+1 и Х*n+1 могут отличаться между собой на величину порядка 1/.
, стремящееся к нулю при увеличения n. Таким образом, вероятностные меры множеств X°n+1 и Х*n+1 могут отличаться между собой на величину порядка 1/.
Не представляет труда рассчитать величину среднего риска для обоих случаев. Обозначим
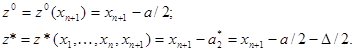
Средний риск оптимального байесова правила при известном равен
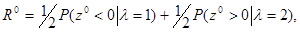
а для адаптивного правила с использованием оценочного значения = *
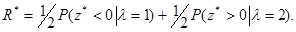
Величины z° и z* нормальны, имеют одинаковые (при фиксированном l) математические ожидания
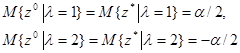
и дисперсии, одинаковые для l = 1 и l = 2 и равные соответственно s2 для z° и s2(1+1/4n) для z*. Вычисляя с использованием нормального распределения соответствующие вероятности, входящие в выражение для R ° и R *, получаем
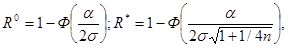 (6.1.4)
(6.1.4)
где Ф(а) - интеграл вероятности
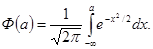 (6.1.5)
(6.1.5)
Из выражений (6.1.4) видно, насколько эффективен и хорош в данном случае рассматриваемый подход - даже при n = 1 различие между оптимальным и адаптивным байесовым правилами решения незначительно, а начиная с n = 2, 3 становится и вовсе несущественным.
Пример 2.Пусть требуется осуществить выбор одной из n альтернатив по результатам наблюдения величины xN+1, которая может принимать дискретные значения х(j) (j = 1,..., m). Обозначим соответствующее решение через uN+1. Пусть априорные данные о виде функции потерь (тем самым и о параметрах l этой функции) и о распределении вероятностей значений х(j) полностью отсутствуют, но мы располагаем дополнительными к xN+1 данными наблюдения о серии из N однородных и независимых повторений выбора решений из заданного множества альтернатив.
Пусть для каждого n-ro повторения (n = l, 2,..., N) известны: значение xv(xv= x(j), j= 1,...,m), которое наблюдалось перед принятием решения; само принятое решение uv(uv = iv, iv = 1,...,n) и величина потерь gv, к которым привел выбор решения uv. Полная совокупность имеющихся перед принятием решения uN+l данных наблюдения х тем самым представляет собой совокупность значений
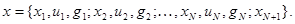
Благодаря независимости xN+1 от остальной совокупности данных при отсутствии априорной неопределенности апостериорный риск, решения uN+l зависел бы только от xN+1, то есть:
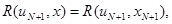
и оптимальное байесово правило решения имело бы следующую структуру:
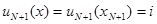
при

Используем все остальные данные наблюдения, которые при отсутствии априорной неопределенности вообще не нужны, для оценки функциональной зависимости апостериорного риска R(uN+1, xn+1) от uN+1 и xN+1. Эта зависимость полностью определяется n x m значениями: Rij = R(uN+1 = i, xn+1=x(j)), которые и нужно оценить с помощью совокупности данных 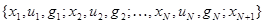 . Обозначим через Rij число раз, когда в серии n = l,2,...,N наблюдалось значение xv =x(j) и было принято решение uу=i. Тогда состоятельной оценкой' величины апостериорного риска Rij является среднее арифметическое
. Обозначим через Rij число раз, когда в серии n = l,2,...,N наблюдалось значение xv =x(j) и было принято решение uу=i. Тогда состоятельной оценкой' величины апостериорного риска Rij является среднее арифметическое
 (6.1.6)
(6.1.6)
где N(i,j) - множество значений индекса n, при которых наблюдалось значение xv =x(j), и было принято решение uv = i.
Используя эту оценку вместо истинной величины апостериорного ряска, получаем следующее представление для адаптивного байесова травила решения:
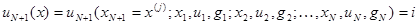
при
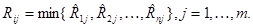 (6.1.7)
(6.1.7)
С ростом N и nij оценка (6.1.6) сходится к истинному значению апостериорного риска, а правило решения (6.1.7) - к оптимальному байесову правилу. При конечных значениях N и nij может оказаться, что какие-либо из значений Rij при данном j равны цмежду собой, то есть min{R1j,R2j,…, Rnj} определяется неоднозначно. Тогда правило решения (6.1.7) следует дополнить, например, выбором наугад (с равными вероятностями) среди тех значений i, для которых выполняется равенство Rij = min{R1j,R2j,…, Rnj}.
В качестве иллюстрации сходимости этого адаптивного правила решения к оптимальному байесову рассмотрим простой пример, когда число возможных решений n равно двум (i = l, 2) и число m возможных значений наблюдаемой величины x(j) также равно двум (j = 1, 2). Пусть потери от принятия любого из решений (i = l, 2) могут иметь два значения - нуль и единица, причем условная вероятность ненулевых потерь в случае принятия i-ro решения, при условии, что наблюдаемое значение xn+1= x(j) есть рij, а безусловная вероятность того, что xn+1= x(j), есть рij. Тогда
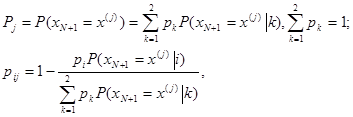
где P(xn+1 = x(j)|k) - значение функции правдоподобия для l = k = 1, 2; pk - априорная вероятность ситуации l = k = 1, 2, а рij является дополнением до единицы апостериорной вероятности i -й ситуации (l = i) при условии xn+1 = x(j). Однако нужно заметить, что исходная постановка задачи шире, чем этот поясняющий пример.)
Если возможные значения потерь (0 и 1), условные вероятности этих потерь pij и вероятности Pj значений xn+1 = x(j) известны, то мы имеем элементарную байесову задачу, в которой с легкостью находится апостериорный риск, оптимальное правило решения и минимальный байесов средний риск. Имеем соответственно
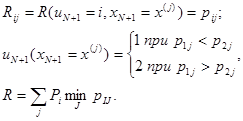
Пусть для определенности p11 < p21 и p12 > p22, тогда
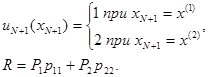
Рассчитаем теперь средний риск для адаптивного правила решения (6.1.7) в тех же условиях (с учетом дополнения его выбором решения наугад при равных значениях оценочного апостериорного риска для первого и второго решений).
Оценка (6.1.6) апостериорного риска в данном случае может быть записана как
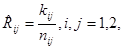
где kij - число раз, когда в серии из N повторений при наблюдении xv = x(j) и принятии решения uv = i потери оказались равными единице. При этом величина kij случайна и распределена на биномиальному закону:
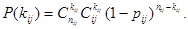
Математическое ожидание оценки
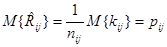
совпадает с истинным значением апостериорного риска при любой последовательности наблюдений xv и решений uv.
Для любого из значений x(j), например для j = 1, может оказаться, что либо R11< R21, и тогда мы выберем первое решение (u = 1) с математическим ожиданием потерь р11, либо R11< R21 и тогда мы неправильно выберем второе решение (u = 2) с математическим ожиданием потерь p21,либо, наконец, R11 = R21, и тогда мы благодаря выбору решения наугад с вероятностью 1/2 выберем или u1, пли u2 с математическим ожиданием потерь 1/2 (p11 + p21). Аналогичное положение будет иметь место и при j = 2. В итоге величина среднего риска для адаптивного правила решения определится следующим образом:
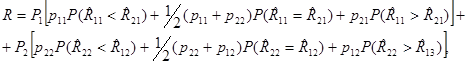
где вероятности выполнения неравенств и равенств вида
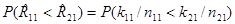
определяются с помощью биномиальных распределений для чисел kij.
Приведем еще выражение для среднего риска правила, при котором решение при любом значении xn+1 принимается наугад с вероятностью 1/2. Можно показать, что при полном отсутствии априорных сведений и отсутствии дополнительных данных наблюдения (N = 0) это лучшее правило решения. Для него
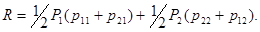
Таблица 6.1
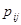
| N | ||||
| ∞ | |||||
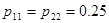 ; ; 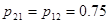
| 0.5 | 0.375 | 0.33 | 0.3 | 0.25 |
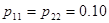 ; ; 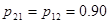
| 0.5 | 0.18 | 0.12 | 0.11 | 0.1 |
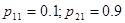 ; ; 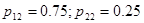
| 0.5 | 0.28 | 0.225 | 0.205 | 0.175 |
Зависимость среднего риска от объема дополнительных данных наблюдения (числа N) для P1 = Р2 = ½ и нескольких совокупностей значений pij приведена в табл. 6.1. При этом предполагается, что при любом из приведенных значений N числа nij одинаковы (nij = N /4). Значение N = 0 соответствует выбору решения наугад, значение N = ¥ - оптимальному байесову правилу принятия решения.
Приведенные примеры показывают, что рассматриваемый подход позволяет получить в условиях априорной неопределенности правила решения (алгоритмы обработки информации), которые обладают достаточно хорошими качествами. Даже при сравнительно небольшом количестве «избыточных» данных эффективность найденных правил решения близка к эффективности соответствующих оптимальных байесовых правил, а при увеличении объема полной совокупности данных наблюдения х происходит достаточно быстрая сходимость к результатам, которые имели бы место при отсутствии априорной неопределенности.
Вернемся снова к общему случаю. Имеет смысл еще раз пояснить суть рассматриваемого подхода. Она состоит в том, чтобы и в условиях априорной неопределенности сохранить для выбора наилучшего решения и нахождения наилучшего правила решения (алгоритма обработки информации) основное содержание байесова подхода. Это последнее заключается в том, что мы сопоставляем каждому состоянию наших знаний, которые характеризуются данными наблюдения х, ожидаемое значение потерь; осуществляем выбор решения, исходя из минимума ожидаемых при данном состоянии наших знаний потерь, и считаем оптимальным такое правило решения u(х), которое соответствует минимуму ожидаемых потерь для любого данного значения х. Именно в этом естественном принципе глубинный смысл байесова подхода - остальное же, на что подчас обращается излишне большое внимание: задание функции потерь, функции правдоподобия, априорного распределения, правила вычисления апостериорного распределения вероятности и апостериорного риска - относится к формальной, а не смысловой стороне подхода.
При этом предельно ясно, что смысловое содержание подхода - наилучшим решением является то, которое обеспечивает наименьшее значение ожидаемых потерь - вовсе не зависит от объема имеющихся априорных знаний. Степень полноты этих знаний влияет только на качество оценки ожидаемых потерь. При отсутствии априорной неопределенности ожидаемые потери для каждого из возможных решений n имеют точную количественную меру - величину апостериорного риска, которая определяется по простым формальным правилам как математическое ожидание потерь при данном состоянии наших знаний х. Нужно подчеркнуть, что эта оценка ожидаемых потерь (расчет величины апостериорного риска) производится по данным наблюдения х, а роль имеющихся априорных сведений о виде функции потерь и распределений вероятности х и l, заключается только в том, что они позволяют установить четкое функциональное соответствие между значением x и величиной ожидаемых при принятии решения и потерь.
При наличии априорной неопределенности по-прежнему необходимо оценить ожидаемые потери для каждого возможного решения. Как и при отсутствии априорной неопределенности, эта оценка, естественно, делается по имеющимся данным наблюдения х. Однако из-за недостатка априорных сведений невозможно установить точное функциональное соответствие между х и величиной апостериорного риска и следует как-то модифицировать свой подход к нахождению оценки ожидаемых потерь. В связи с этим роль и значение вновь полученной информации - данных наблюдения х - повышаются: эти данные выступают не просто в качестве аргумента известной функции апостериорного риска R(u, х), оценивающей ожидаемые потери, но должны быть также использованы для восстановления функционального соответствия между ними и величиной ожидаемых потерь. Процесс восстановления этого соответствия, обеспечивающий реализуемость основного принципа байесова подхода - выбора решения по минимуму ожидаемых потерь, имеет смысл называть адаптацией, а соответствующие правила решений u(х), устанавливающие функциональное соответствие между х и решением u, минимизирующим полученную с учетом ограниченности наших знаний оценку ожидаемых потерь, - адаптивными байесовыми правилами решения.
Применение этой терминологии, не очень много добавляющей по существу, но достаточно установившейся, объясняется тем, что нахождение правила решения при наличии априорной неопределенности так или иначе связано с приспособлением найденного при отсутствии априорной неопределенности правила решения (алгоритма обработки информации, управления и т. п.) к неизвестной (в смысле неполноты априорного статистического описания) обстановке, которая характеризуется какими-то истинными, но полностью или частично неизвестными функциями потерь, распределениями вероятности и значением апостериорного риска, измеряющим ожидаемые потери.
Итак, по существу адаптивный байесов подход основан на принципе выбора решения по минимуму ожидаемых потерь и в этом смысле не отличается от обычного байесова подхода, обеспечивающего нахождение абсолютно наилучших правил решения; методически адаптивный байесов подход основан на замене точной меры ожидаемых потерь — апостериорного риска - его состоятельной оценкой по имеющимся данным наблюдения х и последующем применении всех формальных процедур перехода от заданной функции апостериорного риска к оптимальному правилу решения. Состоятельность оценки апостериорного риска позволяет быть уверенным в том, что не будут допущены по крайней мере грубые ошибки при сопоставлении величин ожидаемых потерь для разных решений и выборе наилучшего решения. Применение же формальных процедур нахождения байесова правила решения по величине апостериорного риска дает гарантию, что ничего не ухудшится в дальнейшем и действительно получится наилучшее при данной оценке ожидаемых потерь правило решения. Конечно, для того, чтобы это правило решения было вообще наилучшим в условиях априорной неопределенности, нужно, чтобы и принятая оценка апостериорного риска была наилучшей, а для того, чтобы правило решения было близко наилучшему при отсутствии априорной неопределенности, нужно, чтобы оценочное и истинное значения апостериорного риска имели минимумы при одном и том же решении и почти для всех значений х или при близких значениях u для всех значений х.








