 2014-02-02
2014-02-02 1271
1271Структурная схема обработки запроса
Внутренние структуры хранения
Определение
Определение
Отношение R(A1A2…An), где A1, A2, …, An – произвольные подмножества множества атрибутов R, удовлетворяет зависимости соединения *(A1, A2, …, An) тогда и только тогда, когда оно равносильно соединению своих проекций с подмножествами атрибутов A1, A2, …, An (т.е. восстанавливается без потерь путем соединения своих проекций).
Например, если определено отношение со схемой R(S, P, J), то это отношение удовлетворяет зависимости соединения *(SP, PJ, SJ), если оно равносильно соединению своих проекций на подмножества атрибутов {S, P}, {P, J} и {S, J}.
Отношение R находится в 5НФ тогда и только тогда, когда любая зависимость соединения в отношении R следует из существования некоторого потенциального ключа отношения R (или каждая зависимость соединения в отношении R подразумевается потенциальными ключами отношения R).
5НФ называют еще нормальной формой проекции – соединения.
Важными особенностями реляционной СУБД, влияющими на организацию хранения данных во внешней памяти, являются следующие:
• наличие двух уровней системы для организации доступа к данным,
• поддержка отношений-каталогов,
• регулярность структуры данных.
Наличие двух уровней
Рассмотрим структурную схему обработки запроса (Рис. 7.1):
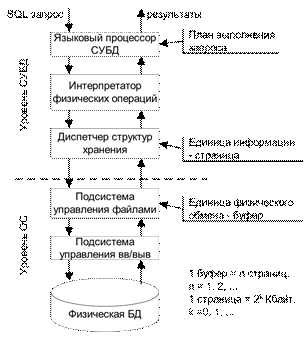
Рис. 7.1. Структурная схема обработки запроса
При такой организации подсистема нижнего уровня должна поддерживать во внешней памяти набор базовых структур, конкретная интерпретация которых входит в число функций подсистемы верхнего уровня.
Поддержка отношений-каталогов
Каталоги базы данных содержат информацию, связанную с объектами базы данных (имена, свойства и т.п.). Эта информация поддерживается системой языкового уровня. С точки зрения структур внешней памяти, отношение-каталог ничем не отличается от обычного отношения.
Регулярность структуры данных
Так как основным объектом базы данных является таблица, главный набор объектов внешней памяти может иметь очень простую регулярную структуру. При этом необходимо обеспечить возможность эффективного выполнения операторов языкового уровня как над одним отношением, так и над несколькими отношениями.
Для этого во внешней памяти должны поддерживаться дополнительные управляющие структуры – индексы.
Отсюда, возникают следующие разновидности объектов базы данных, размещаемых во внешней памяти:
• строка отношения (строка таблицы) – основная часть базы данных, большей частью непосредственно видимая пользователем;
• индексы – объекты, создаваемые по инициативе пользователя или верхнего уровня системы из соображений повышения эффективности выполнения запросов;
• управляющая (служебная) информация, поддерживаемая для удовлетворения внутренних потребностей нижнего уровня системы (например, информация о свободной памяти).
Это и определяет структуру файлов базы данных.
Конкретная организация файлов определяется конкретной СУБД, однако перечисленные выше компоненты, в том или ином виде, присутствуют в любых файлах баз данных.
Тем не менее, имеются общие принципы представления во внешней памяти основных объектов базы данных – таблиц и индексов.
Таблицы обычно хранятся во внешней памяти по строкам. Одинаковые значения атрибутов в разных строках дублируются. Такой способ хранения обеспечивает удобный доступ ко всей строке, но могут потребоваться лишние обращения к памяти, если нужно получить часть строки.
Организация доступа к данным, в общем случае, использует два способа получения данных:
• последовательная выборка данных, позволяющая получить совокупность всех строк таблицы, возможно, упорядоченных по каким-либо атрибутам; такую выборку характеризует следующее предложение:
SELECT * FROM таблица
• произвольная выборка данных, позволяющая получить конкретные строки таблицы, удовлетворяющие некоторому критерию отбора; часто в качестве такого критерия указывается условие совпадения с конкретным значением некоторых (уникальных) атрибутов:
SELECT * FROM таблица WHERE первичный_ключ = значение
Для обеспечения эффективного доступа к данным, размещаемым во внешней памяти, должны использоваться соответствующие методы доступа и дополнительные структуры, позволяющие эффективно выполнять любые запросы.
Обычно рассматриваются два метода доступа к данным:
1. последовательный метод доступа, при котором некоторая целевая запись размещается непосредственно после записи, предшествующей целевой; чтобы получить целевую запись, надо последовательно обратиться ко всем предшествующим цели записям;
2. произвольный метод доступа, при котором положение целевой записи, в общем случае, не зависит от расположения предшествующей; целевая запись может быть получена при непосредственном обращении к ней.
Последовательный метод доступа позволяет легко организовать последовательную выборку данных, но не дает удобных средств организации произвольной выборки: произвольная выборка также сводится к обычному сканированию таблицы. Произвольный метод доступа, при соответствующей организации данных, позволяет эффективно реализовать и последовательную, и произвольную выборку данных. Поэтому в современных СУБД используются произвольные методы доступа. На их основе создаются дополнительные структуры – индексы, обеспечивающие быстрый доступ к требуемым данным. В настоящее время широко распространены методы доступа, основанные на использовании древовидных структур. Эти методы доступа предполагают использование специальных объектов базы данных – индексов, организованных в виде некоторой древовидной структуры. Уникальные индексы создаются на основе ключей таблицы, и в первую очередь, на основе первичного ключа.
Каждый индекс ассоциируется с записью данных (строкой таблицы). Чтобы найти конкретную запись, сначала нужно по заданному значению ключа найти ассоциированный с записью индекс.
Существуют различные древовидные структуры; прежде всего, это – бинарные деревья поиска, но могут быть определены и другие древовидные структуры. Рассмотрим их подробнее.
Прежде всего, рассмотрим двоичные (или бинарные) деревья поиска. Они могут обеспечить разумный компромисс и для произвольной, и для последовательной выборки данных.
Бинарное дерево поиска представляет собой упорядоченную тройку (TL, R, TR), где R – корневая вершина дерева, TL, TR – левое и правое поддеревья вершины R, соответственно.
Каждое из поддеревьев может быть пустым или представляет собой такое же бинарное дерево. TL и TR содержат, соответственно, NL и NR вершин, NL ≥ 0, NR ≥ 0. Общее количество записей в бинарном дереве NR = NL + NR + 1.
Бинарное дерево поиска на множестве NR ключей есть бинарное дерево TNR, в котором каждая вершина помечена отдельным ключом и расположена в соответствии с определенным порядком ключей. Для любой вершины i ключи вершин в его левом поддереве «меньше» ключа вершины i, который, в свою очередь, «меньше» ключей вершин в его правом поддереве.
В каждой вершине бинарного дерева должны храниться:
• значение вершины, т.е. значение полного первичного ключа и некоторая запись RowId, указывающая на размещение соответствующей строки таблицы,
• левый и правый указатели на поддеревья.
Механизм поиска очевиден.
При анализе алгоритма поиска определяют длину пути до целевой записи как количество просмотренных вершин дерева от корня до целевой вершины.
Вставка в бинарное дерево проста, но при этом можно получить разные формы дерева – от линейного списка (Рис. 7.2, а) до сбалансированного дерева (Рис. 7.2, б). Наиболее часто встречается нечто среднее между этими двумя крайними случаями (Рис. 7.2, в).
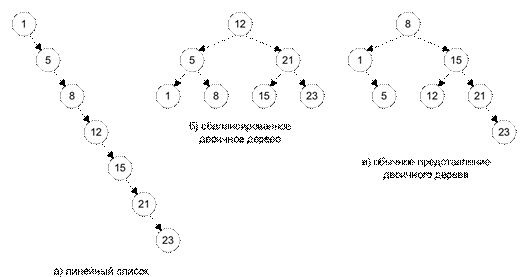
Рис. 7.2. Примеры бинарных деревьев
Введем некоторые определения.
1. Уровень вершины или листа i, обозначаемый Li, определяется длиной пути от корневой вершины TNR до вершины i.
Корневая вершина, по определению, имеет уровень 0.
2. Высота дерева определяется как максимальный уровень среди всех вершин дерева.
3. Бинарное дерево называется сбалансированным, если разница уровней любых двух листьев не превышает 1.
Использование сбалансированного дерева минимизирует среднюю длину доступа.
Неудобство бинарных деревьев поиска заключается в том, что они слишком «высокие»; требуется просмотреть достаточно большое количество вершин дерева, прежде чем будет найдена искомая.
Операции поиска и вставки (в несбалансированное дерево) очевидны.
С операцией удаления связаны определенные проблемы.
Удаление листа выполняется просто.
При удалении промежуточной вершины необходимо сохранить упорядоченность вершин дерева. Возможны разные алгоритмы удаления; например, на место удаляемой промежуточной вершины перемещается элемент с минимальным значением ключа из правого поддерева, подчиненного удаляемой вершине (Рис. 7.3).
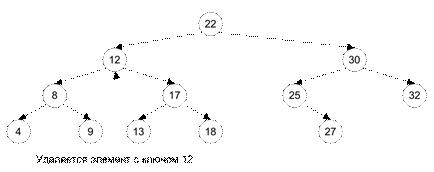
Рис. 7.3. Пример удаления элемента из бинарного дерева
Удаление промежуточной вершины может потребовать реорганизации нескольких уровней бинарного дерева.
На практике бинарные деревья поиска применяются крайне редко, так как из-за своей «высоты» требуют много обращений к внешней памяти при поиске.

