 2014-02-02
2014-02-02 3009
3009Хэш-таблицы
Еще один способ организации данных, используемый в базах данных – использование хэш-таблиц. Хэш-таблицы получили свое название от метода, используемого для организации доступа – хешированный индекс. Этот метод обеспечивает быструю произвольную выборку и обновление записей.
Этот метод принципиально отличается от B+ деревьев – т.е. имеет принципиально другой алгоритм размещения строк в таблице. Рассмотрим особенности построения и использования хеш индексов.
Идея хеширования
Символический ключ (или идентификатор) – это совокупность атрибутов, на которых строится хэш индекс; должен уникально идентифицировать каждую запись таблицы. Он преобразуется в физический адрес. Функция преобразования – это и есть хэш функция.
Принцип отображения: m: 1, т.е. m разных идентификаторов могут быть преобразованы в один и тот же хэш индекс (или собственно адрес). Такие идентификаторы называются синонимами, а ситуация, в которой возникают синонимы – коллизией.
При возникновении коллизий необходимы специальные меры для их разрешения, т.е. для размещения синонима в пространстве таблицы так, чтобы его можно было найти. Обычно поступают так: все адресное пространство, непосредственно доступное функции хеширования, делится на несколько областей фиксированного размера – бакетов (buckets). Это может быть страница (блок) физической памяти или несколько страниц – т.е. любой участок памяти, адресуемый как одно целое. Хэш функция отображает идентификатор в номер бакета. В одном бакете может размещаться несколько записей (строк таблицы).
Процесс разрешения коллизий состоит из двух шагов.
• Выполняется просмотр бакета с целью выявления в нем свободного пространства для новой записи. Если оно есть, новая запись размещается в этом бакете. Если свободного пространства нет – тогда выполняется шаг 2.
• Обрабатывается переполнение бакета.
Область памяти (совокупность бакетов), на которую хеш функция отображает символический ключ, обычно называют первичной областью, а остальную часть доступной памяти – областью переполнения (Рис. 7.36):
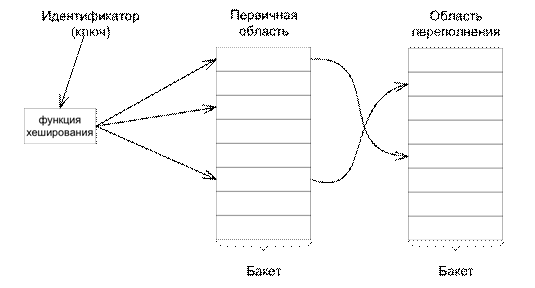
Рис. 7.36. Использование пространства
Методы обработки переполнения призваны обеспечить эффективное хранение записей переполнения.
Принципы построения хеш индекса
Хэш-индекс строится (определяется) на основании некоторой хэш-функции. Хэш-функция отображает значение заданных атрибутов в конкретное размещение в памяти (т.е. в физический адрес – обычно относительный). При использовании хэш-функции важно учитывать следующее:
• Адрес, получаемый в результате, должен попасть в диапазон адресов, соответствующий выделенному пространству. Поэтому пространство под таблицу резервируется при создании таблицы, и в хэш-функции часто используется операция % (остаток от деления на размер таблицы).
• Хэш-функция должна давать достаточно однородные значения хэш-индексов, чтобы не было скопления синонимов (или коллизий), требующих специальных методов обработки.
Поэтому, поскольку на качество хеширования может существенно повлиять выбор функции хеширования, обычно учитываются следующие правила построения хэш-функции:
а) первичный ключ обязательно входит в атрибуты, на которых строится хэш-индекс;
б) хэш-функция должна использовать значения всех атрибутов первичного ключа.
Наилучшей функцией хеширования является функция, отображающая NR значений ключа в точности в NR значений собственных адресов (хэш-индексов) без синонимов. Теоретически существует NR! (факториал) таких способов отображения. Однако если учесть, что существует NRNR способов присвоения NR ключам NR собственных адресов, вероятность такого идеального отображения ничтожно мала [13, стр. 601]. Поэтому тратятся усилия на выбор хэш-функции, достаточно равномерно отображающей ключи на адресное пространство.
Вероятность возникновения коллизий можно уменьшить за счет:
а) выбора хорошей хэш-функции,
б) выделения избыточного адресного пространства.
Если же коллизии, тем не менее, возникают, необходимо их разрешать, используя тот или иной метод обработки переполнения.
Методы обработки переполнения
Метод открытой адресации
При использовании данного метода обработки переполнения основная область и лбласть переполнения объединяются в одно общее пространство.
Изначально все бакеты пусты. Хэш-функция отображает ключи в номера бакетов, в которых сохраняются соответствующие записи. Когда какой-нибудь бакет, например, А, будет заполнен, и хэш-функция отображает новую запись в этот же бакет А, тогда запись переполнения заносится в первую свободную позицию ближайшего незаполненного бакета, например, В (Рис. 7.37). Не успешный поиск продолжается до тех пор, пока не будет обнаружена свободная позиция, или же в результате просмотра всех бакетов не будет получен исходный бакет. Выполняется линейный поиск.
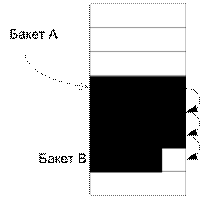
Рис. 7.37. Метод открытой адресации
Один и тот же бакет может использоваться и для размещения переполняющих записей, и для собственных записей. Количество бакетов, которые надо просмотреть, прежде чем запомнить запись, называется смещением записи. Для синонимов имеет место значительное увеличение смещения, что плохо.
Есть разновидности с нелинейным поиском, но все равно это не лучший способ обработки переполнения.
Метод срастающихся цепочек
Выделяется специальная группа свободных бакетов с учетом возможности переполнения, но они все еще входят в первичную область. Область организуется в двухсвязный список (Рис. 7.37, а).
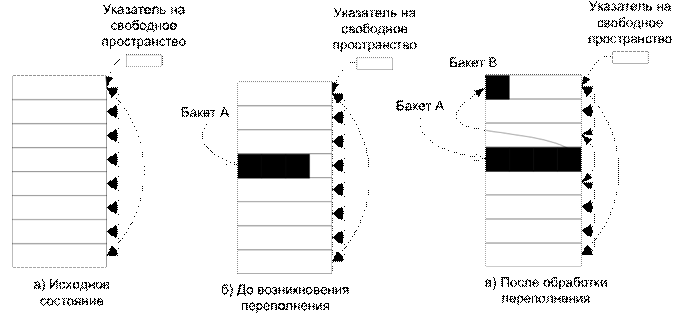
Рис. 7.38. Метод срастающихся цепочек
Изначально все бакеты пусты и связаны двусвязным списком; указатель на свободное пространство определяет первый незаполненный бакет.
Хэш-функция отображает ключи в номера бакетов, в которых сохраняются соответствующие записи (Рис. 7.38, б). Когда какой-нибудь бакет, например, А, будет заполнен, он исключается из списка свободных бакетов. Если хэш-функция отображает новую запись в бакет А, тогда из списка свободных бакетов выбирается первый незаполненный бакет (по указателю на свободное пространство), в котором и размещается новая запись (например, бакет В). При этом бакеты А и В связываются между собой указателем (Рис. 7.38, в).
Когда и бакет В будет заполнен, он также будет исключен из списка свободных бакетов; при этом указатель на свободное пространство переместится на следующий незаполненный бакет.
Бакет В может использоваться и для размещения записей, переполняющих бакет А, и для собственных записей. В случае переполнения бакета В происходит сращивание цепочек синонимов для бакетов А и В.
Метод раздельных цепочек
Для каждого бакета первичной области выделяются локальные бакеты для области переполнения. Все бакеты переполнения выделяются в отдельную область переполнения, и их адреса не могут быть использованы в качестве собственных адресов записей.

Рис. 7.39. Метод раздельных цепочек
Сравнивая рассмотренные выше принципы организации В+ дерева индексов и хеш индекса, можно сделать следующий основной вывод:
B+ деревья используют индексы, которые существуют как объекты базы данных, занимают дисковое пространство и содержат в себе указатели на реальные строки таблицы. В общем случае, B+ дерево не изменяет способ хранения самой таблицы и может быть создано для таблицы, в которую включены строки данных (т.е. это некоторая надстройка над таблицей).
Хэш индексы не представляются значимыми объектами, отображаются на реальные строки таблицы, причем это отображение существенно зависит от размеров таблицы; влияют на способ хранения таблицы и могут его изменить, поэтому хэш индекс должен быть создан до включения какой-либо строки в таблицу.
В соответствии с этим, можно сформулировать следующие важные отличия хэш индексов от индексов B+ дерева.
• B+ дерево имеет реальные объекты – индексы. С хэш таблицей реальные объекты – индексы не связаны.
• B+ дерево не влияет на структуру таблицы, особенности ее отображения в памяти; доступ к строкам таблицы осуществляется через дерево индексов. Хэш таблица имеет специальную организацию, влияющую на доступ к ее строкам.
• В B+ дереве строки таблицы упорядочены (на уровне листьев) по ключу. В хэш таблице никакой речи об упорядоченности строк не может быть, поэтому выборки, требующие упорядоченности (ORDER BY), очень не эффективны.
• При поиске в B+ дереве определены понятия < и > для ключей (выбирается соответствующее поддерево или индекс B+ дерева). Для хэш таблиц такие понятия отсутствуют, эффективный поиск осуществляется только по условию =. Поиск по условиям < и > реализуется с помощью полного сканирования таблицы.
• Пространство для таблицы, использующей B+ дерево, выделяется в процессе вставки новых строк. Пространство для хэш таблиц должно быть выделено предварительно, при создании таблицы. Выделение недостаточного объема памяти приводит к низкой эффективности доступа. Если выделить слишком много памяти, можно столкнуться с неэффективным использованием пространства.
Отсюда, можно дать следующие рекомендации:
1. если размер таблицы сильно изменяется – не хэш таблица;
2. если часто организуется поиск по критериям < > – не хэш таблица;
3. если используются справочники (мало изменяемые таблицы, поиск в них по =) – хэш таблицы.
Надо отметить, что если B+ дерево индексов используется всеми реляционными СУБД, то организация хеш таблиц реализована далеко не всеми СУБД. Так, в DD2® хеш таблицы не используются, а, например, в Oracle – используются. Пример задания хэш таблицы в СУБД Oracle.
Сначала задаются свойства кластерного хэш индекса:
CREATE CLUSTER HD(
DID NUMBER (5,0) SIZE 1K
HASH IS DID
HASHKEYS 200)
Указывается, что строки с одним и тем же значением хеш индекса будут иметь средний размер 1 Кбайт. Число различных значений хеш индекса равно 200 (дополнительный объем памяти распределяется автоматически).
Теперь можно создать хэш таблицу:
CREATE TABLE T(
MDID NUMBER (5) NOT NULL PRIMARY KEY,
...
) CLUSTER HD(MDID)
1. Создание индексов в DB2®
В DB2® доступ к записям таблицы осуществляется на основе B+ дерева индексов. Уникальный не кластерный индекс автоматически создается при создании таблицы (предложение CREATE TABLE) на колонках, для которых в определении таблицы указываются ограничения уникальности (UNIQUE) или первичного ключа (PRIMARY KEY), в возрастающем порядке для каждой колонки. Имя индекса совпадает с именем ограничения, указанным конструкцией CONSTRAINT.
При необходимости, можно создавать индексы на каких-либо колонках таблицы и после ее создания. При этом могут быть созданы как уникальные индексы, так и не уникальные индексы. Для этих целей служит специальное предложение подмножества ЯОД SQL – CREATE INDEX.
Предложение CREATE INDEX создает индекс на основе одного или нескольких атрибутов таблицы. Ниже рассматриваются не все возможности предложения CREATE INDEX. Полное описание предложения см. в SQL Reference [11].
Предложение CREATE INDEX имеет следующий синтаксис:
CREATE [ UNIQUE ] INDEX имя_индекса ON имя_таблицы
(имя_колонки [ ASC | DESC ] [, … ])
[ CLUSTER ]
[ PCTFREE целое ] [ LEVEL2 PCTFREE целое ]
[ MINPCTUSED целое ] [[ DIS ] ALLOW REVERSE SCANS ]
[ PAGE SPLIT { SYMMETRIC | HIGH | LOW } ]
В описании предложения будем использовать понятие ключа индекса – столбец или набор столбцов, на которых определен индекс; эти столбцы определяют полезность индекса. Хотя при создании ключа индекса порядок его столбцов не имеет значения, он учитывается оптимизатором при выборе индекса для оптимизации запроса.
UNIQUE – запрещает создавать в таблице две или более строки с одинаковым значением ключа индекса. Уникальность гарантируется на этапе завершения предложения SQL, которое модифицирует строки или вставляет новые. Уникальность также проверяется в процессе выполнения предложения CREATE INDEX. Если в таблице уже есть строки с одинаковыми значениями в некоторой колонке ключа, индекс не создается. Если указано UNIQUE, все NULL значения рассматриваются как одно и то же значение. Например, если ключ определен на одной колонке, которая может иметь NULL значения, допускается наличие только одного значения NULL для данной колонки.
INDEX имя_индекса – называет индекс. Имя должно быть уникальным в пределах базы данных.
ON имя_таблицы – указывает таблицу базы данных, для которой создается индекс.
имя_колонки – определяет колонку, которая является частью ключа индекса. Каждое имя колонки должно определять колонку таблицы. Допускается указание до 16 колонок. Имена колонок не должны повторяться. Колонки, имеющие тип LOB или LONG, не могут быть указаны как часть индекса.
ASC – указывает, что индексы должны храниться в возрастающем порядке значений колонок; данное условие определено как значение по умолчанию.
DESC – указывает, что элементы индексов должны храниться в убывающем порядке значений колонок.
CLUSTER – определяет кластерный индекс таблицы. Для кластерного индекса вставляемые новые строки физически располагаются близко к существующим строкам с похожими значениями ключа (т.е. физически строки таблицы хранятся в упорядоченном по ключам виде). Это улучшает производительность выполнения запросов. Только один кластерный индекс может быть создан для таблицы. Кластеризация обычно более эффективна, если кластерный индекс является еще и уникальным.
Следующие конструкции предложения CREATE INDEX – PCTFREE, LEVEL2 PCTFREE и MINPCTUSED – относятся к организации хранения индексов на физических страницах. Менеджер баз данных хранит индексы в виде B+ деревьев, нижний уровень которых составляют листья. На страницах-листьях хранятся сами значения ключей индекса. Промежуточные вершины B+ дерева условно разбиваются на уровни: вершины первого уровня непосредственно ссылаются на листья, вершины второго уровня ссылаются на вершины первого уровня, и т.д.
PCTFREE целое – указывает, какая часть каждой (и промежуточной, и листа) страницы индекса (в процентах) остается свободной при построении индекса. Первый элемент добавляется на страницу индекса без ограничений. Когда на странице индексов размещаются дополнительные элементы, на каждой странице остается, по крайней мере, целое % свободного пространства. Значение целого может быть указано в диапазоне от 0 до 99. Если указано значение, большее 10, только 10% свободного пространства будет оставаться на промежуточных страницах индексов. Если данная опция не указана, по умолчанию принимается PCTFREE 10.
LEVEL2 PCTFREE целое – указывает, какой процент на страницах индекса второго уровня остается свободным при построении индекса. Значение целого может быть указано в диапазоне от 0 до 99. Если LEVEL2 PCTFREE не указано, на всех промежуточных страницах индекса остается свободное пространство, определяемое опцией PCTFREE (но не более 10%). Если указано LEVEL2 PCTFREE, тогда целое % свободного пространства остается свободным на промежуточных страницах второго уровня, и минимум из 10 или целое % свободного пространства остается на промежуточных страницах третьего и более высоких уровней.
Если на страницах индекса оставляется больше свободного пространства, реже будет выполняться расщепление страниц. Это уменьшает потребность в реорганизации таблицы, восстанавливающей последовательный порядок страниц, что улучшает эффективность предварительной выборки.
MINPCTUSED целое – указывает, будет ли автоматически выполняться операция фонового слияния страниц-листьев индекса (фоновая дефрагментация), и ограничивает минимальное значение в % пространства, используемого на страницах-листьях индекса. Фоновая дефрагментация индекса предотвращает такую ситуацию, в которой после удаления или обновления большого объема данных на многих страницах-листьях индекса остается всего по нескольку ключей. Если, после удаления ключа со страницы-листа индекса, процент пространства, используемого на странице, становится меньше или равен значению целое, делается попытка выполнить слияние оставшихся ключей на этой странице с соседней страницей. Если есть достаточное пространство на одной из этих страниц, выполняется слияние листьев, и одна из страниц удаляется. Значение целого может быть указано в диапазоне от 0 до 99. По соображениям производительности рекомендуется указывать значение ≤ 50%. Указание данной опции влияет на производительность операций обновления и удаления.
Если фоновая дефрагментация индекса не применяется, то память можно освободить только путем реорганизации данных или индекса.
Вместо опции MINPCTUSED предложения CREATE INDEX целесообразно рассмотреть использование опции CLEANUP ONLY ALL предложения REORG INDEXES для слияния страниц листьев. Страницы, освобожденные в ходе фоновой дефрагментации, могут применяться только для других индексов той же таблицы. При полной реорганизации освобождаемые страницы могут использоваться для других объектов (при работе с хранением, управляемым базой данных) или же становятся свободным дисковым пространством (при работе с хранением, управляемым системой). Кроме того, во время фоновой дефрагментации освобождаются только страницы-листья индекса, тогда как во время полной реорганизации размер индекса уменьшается до минимума за счет сокращения числа листьев и промежуточных страниц, а также числа уровней индекса.
DISALLOW REVERSE SCANS – указывает, что индекс поддерживает только прямое сканирование или сканирование индекса в порядке, определенном во время создания индекса. Это значение принимается по умолчанию.
ALLOW REVERSE SCANS – указывает, что индекс поддерживает и прямое, и обратное сканирование, т.е. в порядке, определенном при создании индекса, и в обратном порядке.
PAGE SPLIT – указывает способ разбиения страниц индекса.
SYMMETRIC – указывает, что страницы индекса, при необходимости выполнить расщепление страницы, разбиваются примерно посередине. Данный способ разбиения устанавливается по умолчанию.
HIGH – указывает способ разбиения страницы индекса, при котором эффективно используется пространство страниц, когда значения вставляемых ключей индекса соответствуют некоторому шаблону. Ключ индекса должен состоять, по крайней мере, из двух колонок. Для подмножества значений ключей индекса левые (одна или более) колонки индекса должны иметь одинаковое значение, а правые колонки (также одна или более) должны иметь значения, которые увеличиваются при каждой операции вставки.
LOW – указывает способ разбиения страницы индекса, при котором эффективно используется пространство страниц, когда значения вставляемых ключей индекса соответствуют некоторому шаблону. Ключ индекса должен состоять, по крайней мере, из двух колонок. Для подмножества значений ключей индекса левые (одна или более) колонки индекса должны иметь одинаковое значение, а правые колонки (также одна или более) должны иметь значения, которые уменьшаются при каждой операции вставки.
Создание большого числа индексов для таблицы, для которой выполняется много операций изменения данных, может замедлить обработку запросов.
Если индекс определяется для пустой таблицы, индекс создается, но записи индекса будут создаваться при загрузке таблицы или вставке в нее строк. Если таблица содержит данные, менеджер баз данных создает записи индекса при выполнении предложения CREATE INDEX.
Примеры:
Пример 1.Создать индекс UNIQUE_NAM на колонке ProjName таблицы PROJECT. Индекс должен гарантировать, что никакие две строки таблицы не будут иметь одинаковое значение колонки ProjName. Значения индекса должны располагаться в возрастающем порядке.
CREATE UNIQUE INDEX UNIQUE_NAM ON PROJECT ( ProjName )
Уникальный не кластерный индекс создается и на этапе создания таблицы для тех колонок, для которых в предложении CREATE TABLE указано ограничение уникальности UNIQUE или первичного ключа PRIMARY KEY. Так, тот же индекс мог быть создан при создании таблицы PROJECT следующим образом:
CREATE TABLE PROJECT(
...
ProjName VARCHAR(20) NOT NULL CONSTRAINT UNIQUE_NAM UNIQUE,
...
)
При создании таблицы индекс создается на пустой таблице, поэтому никакие проверки в процессе создания индекса не выполняются. Если же индекс создается с помощью предложения CREATE INDEX, и таблица PROJECT уже содержит записи, данное предложение завершится с ошибкой, если в таблице имеются строки с одинаковыми значениями в колонке ProjName.
Пример 2.Можно создать не уникальный индекс, допускающий повторение значений, чтобы обеспечить эффективное получение столбцов, не входящих в первичный ключ. Создать не уникальный индекс JOB_BY_DPT на колонках WorkDept и Job таблицы EMPLOYEE, размещая значения индекса в возрастающем порядке.
CREATE INDEX JOB_BY_DPT ON EMPLOYEE ( WorkDept, Job )
Пример 3. Создать кластерный индекс INDEX1 на колонке LastName таблицы EMPLOYEE:
CREATE INDEX INDEX1 ON EMPLOYEE (LastName) CLUSTER
Для таблицы можно определить только один кластерный индекс.
Пример 4. Создать индекс LASTN на колонке LastName таблицы EMPLOYEE, включив функцию фоновой дефрагментации индекса. Минимальное используемое пространство на конечных страницах индекса – 20%. Если это условие задано, то будет применяться фоновая дефрагментация индекса.
CREATE INDEX LASTN ON EMPLOYEE (LastName) MINPCTUSED 20
Если после физического удаления ключа со страницы-листа этого индекса оставшиеся ключи будут занимать не более двадцати процентов страницы индекса, то будет предпринята попытка удалить эту страницу, объединив оставшиеся ключи этой страницы с ключами, расположенными на одной из соседних страниц индекса. Если ключи из этих двух страниц умещаются на одной странице, выполняется слияние страниц, и одна страница индекса удаляется.
Пример 5. Создать кластерный индекс на колонке первичного ключа DeptNo таблицы DEPT.
Если при создании таблицы DEPT для колонки DeptNo будет указано ограничение первичного ключа, на этой колонке будет автоматически создан не кластерный уникальный индекс, и создать на этой колонке новый индекс будет нельзя. Поэтому, если на колонках первичного ключа нужно создать кластерный индекс, последовательность действий должна быть следующей:
1. с помощью предложения CREATE TABLE создать таблицу, не указывая в ней ограничение первичного ключа:
CREATE TABLE DEPT (
DeptNo CHAR(3) NOT NULL,
DeptName VARCHAR(36) NOT NULL UNIQUE,
MgrNo CHAR(6)
)
2. с помощью предложения CREATE INDEX создать уникальный кластерный индекс на требуемых колонках таблицы:
CREATE UNIQUE INDEX DEPTCLUSTINDEX ON DEPT (DeptNo) CLUSTER
3. с помощью предложения ALTER TABLE добавить в таблицу ограничение первичного ключа для соответствующих колонок:
ALTER TABLE DEPT ADD CONSTRAINT DEPTCLUSTINDEX PRIMARY KEY (DeptNo)
или
ALTER TABLE DEPT ADD PRIMARY KEY (DeptNo)
Если предложение ALTER TABLE используется для добавления ограничений первичного ключа или уникальности, в качестве имени ограничения может быть указано имя созданного уникального индекса, или же имя ограничения может не указываться. И в том, и в другом случае система генерирует для ограничения имя в соответствии со своими правилами. В результате созданный индекс будет использоваться в качестве индекса первичного ключа.
1. Организация файлов базы данных в DB2®
Физическая организация реляционной базы данных в DB2® UDB
Универсальная база данных видит окружение в виде иерархии объектов (Рис. 7.40).
Высший уровень иерархии – рабочие станции (или серверы), на которых установлена система.
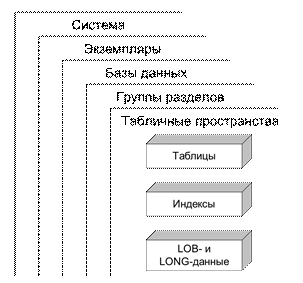
Рис. 7.40. Иерархия объектов
В ходе процесса инсталляции программные файлы для фонового процесса, известные как менеджер БД DB2®, физически копируются в определенное место на сервере – создается экземпляр менеджера БД DB2®. Экземпляры отвечают за управление системными ресурсами и базами данных, которые подпадают под их контроль.
Первоначально создается один экземпляр, но в принципе их может быть много. Каждый экземпляр является полнофункциональной средой, полностью независимой от других экземпляров. Каждый экземпляр имеет собственный файл конфигурации, настраивающий его окружение. Файл конфигурации создается при создании экземпляра DB2®. Содержащиеся в нем параметры влияют на системные ресурсы на уровне экземпляра, независимо от баз данных, составляющих части этого экземпляра.
Каждый экземпляр контролирует доступ к одной или нескольким собственным базам данных, к которым не могут обращаться другие экземпляры. Базы данных работают независимо друг от друга.
В реляционной базе данных данные представлены в виде собрания таблиц. Таблицы хранятся во внешней памяти, и структуры хранения имеют свою организацию.
Каждая база данных включает в себя набор таблиц системного каталога, описывающий логическую и физическую структуру данных, файл конфигурации, содержащий значения параметров этой базы данных, и журнал восстановления с текущими и архивными транзакциями.
DB2 создает и поддерживает набор таблиц системного каталога для каждой базы данных. Эти таблицы содержат информацию об определениях объектов баз данных, например, для таблиц, представлений и индексов, а также информацию защиты о полномочиях пользователей для этих объектов. Таблицы системного каталога создаются при создании базы данных и изменяются во время нормальной работы. Их нельзя явно создать или отбросить, но можно запросить и просмотреть их содержимое.
Файл конфигурации базы данныхсоздается при создании базы данных и размещается там же, где и сама база. Для одной базы данных существует один файл конфигурации. Помимо прочего, его параметры задают количество ресурсов, выделяемых для базы данных. Значения для многих из этих параметров можно изменить для улучшения производительности или увеличения емкости. В зависимости от рода работы, выполняемой с базой данных, могут потребоваться разные изменения. У каждой базы данных есть собственный файл конфигурации, и большинство параметров из этого файла задают объем ресурсов, выделяемых базе данных. Кроме того, файл содержит описательную информацию, а также флаги состояния базы данных.
База данных содержит один или несколько разделов, в которых создаются табличные пространства, а сами таблицы создаются уже в табличных пространствах. Табличные пространства используются в целях контроля над тем, где физически хранятся данные.
Группа разделов базы данных– это набор из одного или нескольких разделов базы данных. При создании таблиц для базы данных сначала создается группа разделов, в которой будут храниться табличные пространства, а затем создается табличное пространство, в котором будут храниться таблицы.
Таблицы – предназначены для хранения данных, логически упорядоченных по строкам и столбцам. Таблица содержит определенное число столбцов и произвольное число строк. Все данные базы данных и таблиц собраны в табличных пространствах. Данные в таблице логически связаны, а между таблицами могут быть заданы отношения.
Для организации доступа к данным используются индексы. Индекс – это набор ключей, каждый из которых указывает на строки в таблице. Индекс позволяет эффективнее получать доступ к строкам в таблице, создавая прямой путь к данным через указатели. Оптимизатор SQL автоматически выбирает наиболее эффективный путь доступа к данным в таблицах. При определении наиболее быстрого доступа к данным он принимает во внимание индексы.
Табличные пространства
База данных разбивается на части, которые называются табличными пространствами. Табличное пространство – это пространство, предназначенное для хранения объектов базы данных (таблиц, индексов, LOB и LONG данных). При создании таблицы можно решить, что определенные объекты (например, данные индексов и больших объектов) будут храниться отдельно от остальных табличных данных (Рис. 7.41). Табличное пространство может быть размещено на одном или нескольких физических устройствах хранения.
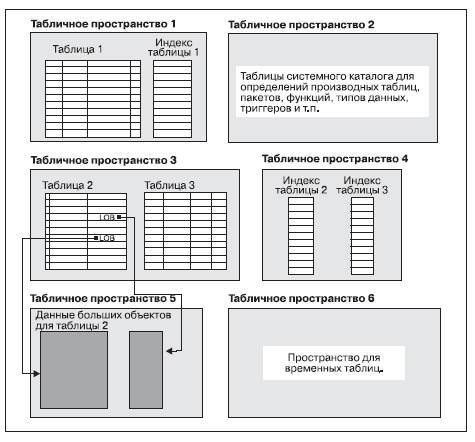
Рис. 7.41. Использование табличных пространств
Определения и атрибуты табличных пространств хранятся в системном каталоге баз данных.
В системе различают обычные табличные пространства и большие табличные пространства. Каждое табличное пространство имеет имя.
Таблицы, содержащие пользовательские данные, находятся в обычных табличных пространствах. Пользовательское табличное пространство по умолчанию называется USERSPACE1.
Таблицы системного каталога находятся в обычном табличном пространстве. Табличное пространство системного каталога по умолчанию называется SYSCATSPACE.
Таблицы, содержащие длинные поля данных или данные больших объектов, например объектов мультимедиа, размещаются в больших табличных пространствах или обычных табличных пространствах. Основные данные из таких столбцов хранятся в обычном табличном пространстве, а данные длинных полей и больших объектов хранятся либо в том же обычном табличном пространстве, либо в указанном большом табличном пространстве.
Индексы хранятся в обычных табличных пространствах или больших табличных пространствах.
Для хранения временных объектов, создаваемых при выполнении каких-либо предложений SQL, используются временные табличные пространства. Временные табличные пространстваподразделяются на системные и пользовательские. Системные временные табличные пространстваиспользуются для хранения внутренних временных данных, требующихся при таких операциях SQL, как сортировка, реорганизация таблиц, создание индексов и объединение таблиц. Системное временное табличное пространство по умолчанию называется TEMPSPACE1.
Пользовательские временные табличные пространстваиспользуются для хранения объявленных глобальных временных таблиц, в которых хранятся временные данные программы. Пользовательские временные табличные пространства при создании базы данных по умолчанию не создаются.
По умолчанию табличные данные хранятся на страницах по 4 Кбайта. Каждая страница (независимо от ее размера) содержит 68 дополнительных байтов для менеджера баз данных. Для хранения пользовательских данных (или строк) останется 4028 байт, хотя никакая строка на странице размером 4 Кбайта не может превышать 4005 байт в длину. Строка не можетзанимать несколько страниц. При использовании страниц размером 4 Кбайта допустимо не более 500 столбцов.
Обычно строки вставляются в таблицу в порядке ″первый подходящий″. В файле (при помощи карты свободного места) ищется первый отрезок свободного места, достаточно большой, чтобы вместить новую строку. При изменении строки она изменяется на старом месте, если только на странице достаточно для этого пространства. Если это не так, то на старом месте строки создается запись, указывающая на новое местоположение измененной строки в табличном файле.
С помощью предложения SQL ALTER TABLE APPEND ON можно указать, что данные должны всегда добавляться в конец таблицы. В этом случае информация о свободном месте на страницах данных не сохраняется.
Страницы табличных данных несодержат данных для колонок типов LONG и LOB. Если в таблице какие-либо колонки объявлены как LONG или LOB, в строках на странице табличных данных в соответствующих позициях содержится дескриптор для этих колонок, а сами значения размещаются в отдельных табличных объектах, структура которых отличается от других типов данных.
База данных создается с помощью команды CREATE DATABASE, имеющей большое количество параметров, позволяющих задать все необходимые характеристики базы данных. В простейшем случае команда имеет вид:
CREATE DATABASE имя_базы_данных
Данная команда позволяет создать базу данных с указанным именем, характеристики которой устанавливаются в соответствии с правилами по умолчанию. В частности, при этом создаются табличные пространства с именами SYSCATSPACE для системных каталогов, USERSPACE1 для пользовательских таблиц и индексов, TEMPSPACE1 для временных таблиц, создаваемых системой. При необходимости, администратор системы может создавать дополнительные табличные пространства с помощью предложения CREATE TABLESPASE. Описание предложения можно найти в SQL Reference [11].
Логическая организация реляционной базы данных в DB2® UDB
На логическом уровне все объекты базы данных (таблицы, представления, триггеры, функции и другие) размещаются в схемах. Схема представляет собой коллекцию именованных объектов и сама также является объектом базы данных.
Схема может быть создана явно, с помощью предложения CREATE SCHEMA, имеющего следующий синтаксис:
CREATE SCHEMA идентификатор_схемы [ SQL-предложения_схемы ]
Идентификатор_схемы может быть задан одним из трех способов:
1. имя_схемы; в этом случае владельцем схемы становится текущий пользователь;
2. AUTORIZATION авторизационное_имя; в этом случае владельцем схемы становится указанный в данной конструкции пользователь, и имя схемы совпадает с именем владельца схемы;
3. имя_схемы AUTORIZATION авторизационное_имя; в этом случае задаются явно и имя схемы, и владелец схемы.
SQL-предложения схемы включают предложения CREATE, COMMENT, GRANT.
Схема может создаваться неявно, когда создается некоторый другой объект базы данных, например, таблица; в этом случае пользователь, создающий объект, должен иметь полномочия IMPLICIT_SCHEMA. При неявном создании схемы в качестве имени схемы используется имя пользователя.
Имя схемы – уникально и не может начинаться символами SYS. Владельцем схемы становится текущий пользователь, создающий схему, или пользователь, указанный в конструкции AUTORIZATION.
Имя любого другого объекта базы данных состоит из двух частей – имени схемы и имени самого объекта, разделенных символом «точка»:
имя_схемы. имя_объекта
Соответственно, в любом предложении SQL, в котором используется тот или иной объект базы данны, имя объекта может быть представлено полностью, например:
SELECT *
FROM UDBA.EMPL
Если при именовании объекта базы данных имя схемы не указывается, в качестве имени схемы по умолчанию подставляется имя пользователя.
При создании объектов базы данных (например, таблиц) имя объекта также может быть указано вместе с именем схемы, например:
CREATE TABLE MYSCHEMA.TAB(
…
)
В этом случае если указанная в предложении схема не существует, она будет создана; создаваемый объект базы данных (таблица в данном примере) будет размещен в указанной схеме.
Если же в предложениях CREATE имя схемы не указывается, создаваемые объекты размещаются в текущей схеме, имя которой можно получить с помощью специального регистра CURRENT SCHEMA.
Существуют ограничения на схемы, в которых можно размещать создаваемые объекты. Так, при создании таких объектов базы данных, как таблицы, представления и индексы, нельзя (явно или неявно) указывать схемы с именами SYSIBM, SYSCAT, SYSFUN, SYSSTAT. При создании типов данных, определенных пользователем, функций, последовательностей и триггеров имя схемы не может начинаться символами SYS.








