 2014-02-02
2014-02-02 693
693Арифметическое кодирование
Метод кодирования Хаффмана хотя и является простым в реализации и относительно эффективным, тем не менее, не позволяет достичь максимального коэффициента сжатия, если только все вероятности не представляют собой отрицательных степеней числа 2. Арифметическое кодирование предназначено для достижения более высоких коэффициентов сжатия за счет усложнения вычислений. При этом изображение обрабатывается таким образом, чтобы вероятности приближались к отрицательным степеням числа 2. Арифметическое кодирование используется в стандартах JPEG и MPEG. Мы начнем с концепции, лежащей в основе арифметического кодирования, а затем рассмотрим некоторые детали.
Вспомним из обсуждения метода кодирования Хаффмана, что если отдельные кодируемые символы встречаются в исходном тексте с вероятностью Рi, то в лучшем случае мы можем использовать для каждого символа код длины Li, удовлетворяющей следующему неравенству:
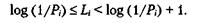
Здесь Рi представляет собой вероятность, с которой i -й символ встречается в исходных данных, a Li — длину двоичного кода, которым кодируется данный символ. Исходя из данного неравенства, можно показать, что
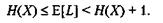
Здесь H(X) представляет собой энтропию множества символов X, a E[L] является средней длиной кода для множества X. В схеме сжатия без потерь H(X) всегда будет нижней границей объема сжатых данных, так как H(X) определяет среднее количество информации, содержащейся в символьном наборе. Наконец, было показано, что эффективность алгоритма сжатия может быть повышена путем объединения символов и одновременного кодирования блоков по К символов каждый. В результате мы получаем следующее неравенство:
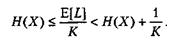
Таким образом, существует способ повышения эффективности алгоритма сжатия. Если нам нужно отправить сообщение длиной в N символов, мы можем использовать блок длиной N. Таким образом, мы обращаемся с каждым сообщением как с одним из MN возможных результатов, где М представляет собой количество атомарных символов, а N — длину сообщения. В качестве примера рассмотрим случай, обсуждавшийся ранее, в котором имеются два символа, А и В, встречающиеся в исходном тексте с вероятностями 0,8 и 0,2. Если мы передаем сообщение длиной в 3 символа (М = 2, N= 3), тогда существуют 23 = 8 возможных результатов. Если появление в потоке данных каждого символа не зависит от предыдущих символов, тогда мы можем написать вероятности всех 8 результатов:

Один из возможных методов состоит в применении кода. Для сообщения с восемью возможными результатами это разумно, но при очень длинных сообщениях использование этого метода приведет к большим вычислительным затратам. Метод арифметического кодирования предоставляет остроумную альтернативу. Заметим, что сумма вероятностей всех возможных сообщений должна быть равна 1,0. Таким образом, можно разложить все результаты на интервале [0,1] в виде отрезков, длины которых равны их вероятностям. На рисунке также показан простой метод генерирования интервалов по одному символу. Эта процедура выглядит следующим образом:
1. Алгоритм начинается с позиции первого символа в сообщении, а интервал делится в соответствии с вероятностями отдельных символов. В данном случае имеется два символа, А и В, встречающиеся в исходном тексте с вероятностями 0,8 и 0,2. Поэтому интервал [0, 1] разбивается на подынтервалы [0, 0,8) и [0,8, 1). Граница между интервалами может быть отнесена произвольно к любому из интервалов.
2. Каждый подынтервал разбивается тем же способом, который применялся на шаге 1. То есть каждый подынтервал дробится на доли в соотношении 4:1.
3. Этот процесс повторяется для N символьных позиций (сообщение длины N).

Теперь результату каждого сообщения поставлен в соответствие интервал, пропорциональный вероятности сообщения. Таким образом, каждый результат может быть представлен двоичным дробным числом, равным некоторой точке на интервале. Будем использовать для этого нижнюю границу каждого интервала. Результаты такой операции показаны в пятой колонке таблицы ниже, при этом используются пять значащих цифр правее двоичной запятой. Такой точности достаточно для однозначной идентификации каждого интервала, а следовательно, и каждого результата. Поэтому мы можем использовать дробную часть каждого значения в качестве кода для соответствующего результата (например, АВА= 10100). Однако полученные коды можно усовершенствовать. Например, можно удалить из кода некоторые цифры, если только это не приведет к неразличимости кодов (то есть ни один код не должен совпадать с начальными цифрами другого кода). Результат этой операции показан в шестой колонке таблицы. Обратите внимание на то, что в общем случае более короткие интервалы идентифицируются большим числом битов. В этом есть смысл: нижняя граница короткого интервала близка к нижней границе следующего интервала. Поэтому двоичные дроби для этих двух границ будут совпадать в нескольких разрядах. Чем меньше интервал, тем больше одинаковых разрядов в соответствующих дробях.
| Последовательность | Pi | Кумулятивная Вероятность | Интервал | Двоичное представление нижней границы | Код | PiLi | Pilog(1/Pi) |
| AAA | 0.512 | 0.512 | [0,0.512] | 0.00000 | 0.512 | 0.494 | |
| AAB | 0.128 | 0.64 | [0.512,0.64] | 0.10000 | 0.384 | 0.38 | |
| ABA | 0.128 | 0.768 | [0.64,0.768] | 0.10100 | 0.384 | 0.38 | |
| ABB | 0.032 | 0.8 | [0.768,0.8] | 0.11000 | 0.16 | 0.159 | |
| BAA | 0.128 | 0.928 | [0.8,0.928] | 0.11001 | 0.64 | 0.38 | |
| BAB | 0.032 | 0.96 | [0.928,0.96] | 0.11101 | 0.096 | 0.159 | |
| BBA | 0.032 | 0.992 | [0.96,0.992] | 0.11110 | 0.096 | 0.159 | |
| BBB | 0.008 | 1.0 | [0.992,1.0] | 0.11111 | 0.04 | 0.056 | |
| 2.408 | 2.167 |
Таким образом, мы разработали новый метод назначения кодов сообщениям. В последних двух колонках таблицы средняя длина нового кода сравнивается с энтропией множества сообщений. Несмотря на всю свою внешнюю привлекательность новый метод обладает двумя существенными недостатками:
· Если все возможные интервалы вычислять заранее, то объем необходимых вычислений будет огромен. Например, если длина сообщения равна 1000 символов и используется алфавит из 128 символов (например, набор символов ASCII), тогда число всех возможных сообщений будет составлять 1281000 = 102107.
· Описанная схема применима только к сообщениям фиксированной длины. Метод арифметического кодирования позволяет устранить оба недостатка.








