 2014-02-02
2014-02-02 681
681Чистое арифметическое кодирование
Мы начнем с простейшей формы алгоритма арифметического кодирования. Хотя этот алгоритм преодолевает упомянутые ранее недостатки, в нем сохраняются некоторые вычислительные сложности. Тем не менее, проще понять метод арифметического кодирования, рассмотрев сначала более простую форму. При арифметическом кодировании нет необходимости заранее генерировать интервалы для всех возможных сообщений. Вместо этого интервалы для отдельного сообщения вычисляются посимвольно. Таким образом, для передачи одного сообщения вычисляется только один интервал. Кроме того, поскольку процесс является посимвольным, нет необходимости фиксировать длину сообщения заранее. Вычисления продолжаются до тех пор, пока не будет достигнут конец сообщения.
Каждый шаг алгоритма начинается с полуоткрытого интервала [L, Н), вначале инициализируемого как [0,1):
1. Текущий интервал разбивается на подынтервалы по одному для каждого возможного символа. Каждый подынтервал пропорционален вероятности, с которой соответствующий символ встречается в тексте.
2. Выбирается подынтервал, соответствующий текущему символу. Этот по
дынтервал становится текущим интервалом.
3. Если обработано все сообщение, выполняется следующий шаг, если нет, воз
вращаемся к шагу 1.
4. Выводится количество битов, достаточное для того, чтобы можно было от
личить данный интервал от двух соседних интервалов.
5. Выводится некий специальный код конца сообщения, чтобы уведомить по
лучателя.
На первом шаге нет необходимости вычислять все подынтервалы. Вместо этого вычисляются только подынтервал, соответствующий текущему символу. Кратко эта операция описана далее. Введем следующие обозначения:

При этом каждая итерация алгоритма включает следующие вычисления:
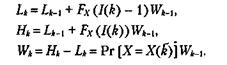
Ширина конечного подынтервала равна произведению вероятностей каждого встретившегося за время работы алгоритма символа и поэтому представляет собой вероятность того, что данное сообщение т встретится в MN возможных сообщениях. Это можно выразить так:
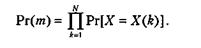
Можно показать, что для уникальной идентификации интервала сообщения т требуется, самое большее, 2+log(1/Pr(m)) бит. Чтобы продемонстрировать это на интуитивно понятном уровне, рассмотрим два первых интервала с соответствующими длинами Рr(1) и Рr(2), то есть интервалы [0, Рr(1))и [Рr(1), Рr(1) + Рr(2)). Теперь предположим, что для определения интервала мы используем его нижнюю границу. При этом двоичная дробь, представляющая Рr(1), будет кодом для второго интервала. Существует некоторое число j, такое, что 2-j будет наименьшей величиной, удовлетворяющей неравенству 2-j > Рr(1). Это число представляет собой двоичную дробь, начинающуюся с (log(l/Pr(m)) - 1) бит, за которыми следует 1. При использовании этого значения в качестве кода для второго интервала гарантируется, что этот код уникально идентифицируется по отношению к первому интервалу. Обратите внимание на то, что в данной формулировке не делается предположений о стационарности или независимости переходов.








