2014-02-02
2014-02-02 1078
1078Сжатие
Алгоритмы LZ78 и LZW
Алгоритм распаковки
Процесс распаковки текста, сжатого при помощи алгоритма LZ77, прост. Алгоритм распаковки должен сохранять последние N символов распакованного результата. Когда встречается закодированная строка, алгоритм распаковки заменяет код с помощью долей указателя и длины.
Алгоритмы LZ78 и LZW пытаются обойти ограничения схемы LZ77, вместо ограниченного окна создавая словари. Как и схема LZ77, алгоритм LZW (и LZ78) поддерживает словарь строк вместе с их кодами как для сжатия, так и для распаковки. Когда любая строка словаря появляется на входе алгоритма сжатия, эта строка заменяется кодом. Распаковщик, наоборот, заменяет коды соответствующими им строками. По мере работы алгоритма сжатия к словарю добавляются новые строки.
В любой момент времени словарь содержит все односимвольные строки плюс некоторые многосимвольные строки. Механизм работает так, что любые ведущие подстроки присутствующей в словаре строки также могут использоваться в качестве элементов словаря. Например, если в словаре есть строка MEOW, снабженная своим уникальным кодовым словом, тогда строки МЕО и ME также присутствуют в словаре и у каждой есть свое уникальное кодовое слово. Логически словарь может быть представлен в виде набора деревьев, при этом корень каждого дерева соответствует символу алфавита. Таким образом, по умолчанию имеется 256 деревьев (все возможные 8-битовые символы). Далее будет более детально описан алгоритм, имеющий много общего со стандартом V.42bis и схемами LZ78 и LZW.
Прежде чем перейти к описанию алгоритма, введем следующие обозначения:
· С1 — следующее доступное неиспользуемое кодовое слово;
· С2 — размер кодового слова, по умолчанию 9 бит;
· N2 — максимальный размер словаря, равный количеству кодовых слов (2C2);
· N3 — размер символа, по умолчанию 8 бит;
· N5 — первое кодовое слово, используемое для обозначения строки из более
чем одного символа;
· N7 — максимальная длина строки, которая может быть закодирована.
Алгоритм сжатия реализует три основные действия:
· поиск совпадений строк и кодирование;
· добавление новых строк к словарю;
· удаление старых строк из словаря.
Алгоритм всегда ищет в словаре строку максимальной длины, совпадающую с входной строкой. Передатчик разбивает входной поток на строки, присутствующие в словаре, и преобразует каждую строку в соответствующее кодовое слово. Поскольку все односимвольные строки уже находятся в словаре, весь входной поток может быть разбит на строки, присутствующие в словаре. Приемник принимает поток кодовых слов и преобразует каждое кодовое слово в соответствующую символьную строку. Алгоритм всегда ищет новые строки, которые можно добавить к словарю, а также заменить ими старые строки, которые вряд ли встретятся в будущем. Процедура выглядит следующим образом:
1. Входные символы обрабатываются, чтобы получить совпадающие строки
большей длины.
2. Если совпадающая строка имеет максимальную длину (N7 символов), тогда
алгоритм передает код для этой строки и переходит к шагу 1.
3. В противном случае к совпадающей строке добавляется следующий символ,
а сама строка добавляется к словарю и ей назначается код. Однако посколь
ку эта строка еще отсутствует в словаре получателя, алгоритм передает код
оригинальной строки и использует оставшийся символ, чтобы опять начать
с шага 1.
Процедура добавления новой строки к словарю зависит от того, является ли словарь полным или нет. В любом случае передатчик хранит переменную С1 представляющую собой значение следующего доступного кодового слова. При инициализации системы переменной С1 присваивается значение N5, которое представляет собой следующее значение, после того как всем односимвольным строкам присвоены значения. Таким образом, по умолчанию значение С1 начинается с 256. До тех пор пока словарь пуст, при определении каждой новой строки ей назначается код С1 и этот код увеличивается на единицу.
Когда словарь полон, при определении новой строки ей назначается кодовое значение С1 затем выполняется следующая процедура:
1. С1 увеличивается на единицу.
2. Если значение С1 равно максимальному размеру словаря N2, оно устанавливается равным N5. To есть как только величина С1 достигает своего максимального значения, она снова устанавливается равной минимальному значению.
3. Если узел, идентифицируемый значением С1, не является листовым узлом,
тогда выполняется переход к шагу 1.
4. Если узел является листовым узлом, тогда он удаляется из словаря.
В конце этой процедуры в словаре появляется место для новой записи, а С1 представляет собой неиспользуемый код, присваиваемый этой записи. Теперь система готова к определению следующей новой строки словаря.
Рисунок нижеиллюстрирует работу алгоритма сжатия, для которого используется трехсимвольный алфавит. Вначале в словаре находятся только односимвольные строки (верхняя часть таблицы). Входные данные считываются слева направо. Поскольку в таблице нет совпадающих строк длиннее а, для этой строки выводится код 1, а к таблице добавляется новая строка ab, которой назначается код 4. Затем для начала новой строки используется символ b. Поскольку строки bа нет в словаре, она добавляется в словарь с кодом 5, а в выходной поток направляется символ b. Процесс продолжается подобным образом.
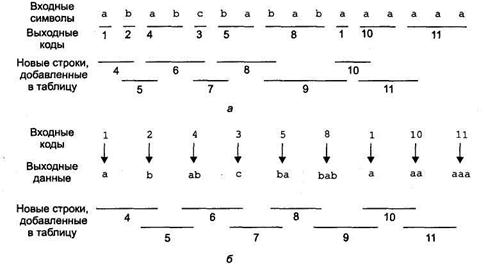
| СТРОКОВАЯ ТАБЛИЦА | АЛЬТЕРНАТИВНАЯ ТАБЛИЦА | ||
| СИМВОЛ | КОД | СИМВОЛ | КОД |
| A | a | ||
| B | b | ||
| c | c | ||
| ab | 1b | ||
| ba | 2a | ||
| abc | 4c | ||
| cb | 3b | ||
| bab | 5b | ||
| baba | 8a | ||
| aa | 1a | ||
| Aaaa | 10a |
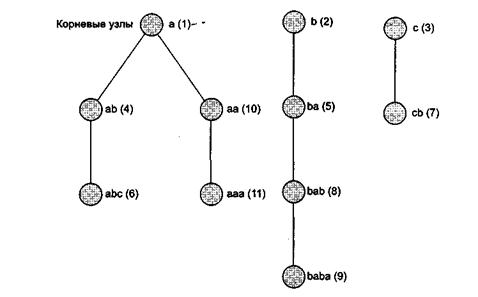
В таблице показан словарь, формируемый в данном примере. Более компактный метод хранения иллюстрирует правая часть таблицы, в которой каждая строка представляется в виде префиксного кода строки и последнего символа. При таком представлении все многосимвольные элементы словаря имеют равную длину.
Такое представление также предполагает структуру словаря, состоящую из нескольких деревьев, как показано на рисунке.
Интересный аспект работы семейства алгоритмов LZ78 заключается в том, что словарь не передается явно алгоритму распаковки. Вместо этого алгоритм распаковки создает идентичный словарь в процессе распаковки. Это возможно благодаря тому, что при распаковке строка, соответствующая коду, всегда встречается прежде самого кода.
Нижняя часть рисунка, описывающего процесс кодированияиллюстрирует процесс распаковки. Каждый встреченный код преобразуется в соответствующую символьную строку. Между тем, выходной поток используется для создания новых элементов словаря по тем же правилам, что и в алгоритме сжатия.