 2014-02-03
2014-02-03 2677
2677Технологии распределенных вычислений (РВ)+11.Распред-я обработка данных
Современное производство требует высоких скоростей обработки информации, удобных форм ее хранения и передачи. Необходимо также иметь динамичные способы обращения к информации, способы поиска данных в заданные временные интервалы, чтобы реализовывать сложную математическую и логическую обработку данных.
Управление крупными предприятиями, управление экономикой на уровне страны требуют участия в этом процессе достаточно крупных коллективов. Такие коллективы могут располагаться в различных районах города, в различных регионах страны и даже в различных странах. Для решения задач управления, обеспечивающих реализацию экономической стратегии, становятся важными и актуальными скорость и удобство обмена информацией, а также возможность тесного взаимодействия всех участвующих в процессе выработки управленческих решений.
В эпоху централизованного использования ЭВМ с пакетной обработкой информации пользователи вычислительной техники предпочитали приобретать компьютеры, на которых можно было бы решать почти все классы их задач. Однако сложность решаемых задач обратно пропорциональна их количеству, и это приводило к неэффективному использованию вычислительной мощности ЭВМ при значительных материальных затратах. Нельзя не учитывать и тот факт, что доступ к ресурсам компьютеров был затруднен из-за существующей политики централизации вычислительных средств в одном месте.
Принцип централизованной обработки данных (рис. 5.1) не отвечал высоким требованиям к надежности процесса обработки, затруднял развитие систем и не мог обеспечить необходимые временные параметры при диалоговой обработке данных в многопользовательском режиме. Кратковременный выход из строя центральной ЭВМ приводил к роковым последствиям для системы в целом.
 I
I
Рис. 5.1 - Система централизованной обработки данных
Появление персональных компьютеров потребовало нового подхода к организации систем обработки данных, к созданию новых информационных технологий. Возникло логически обоснованное требование перехода от использования отдельных ЭВМ в системах централизованной обработки данных к распределенной обработке данных (рис. 5.2).
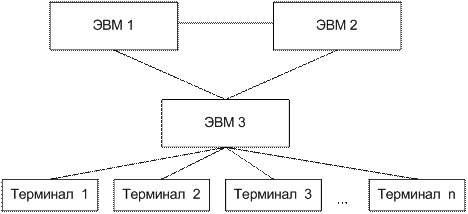
Рис. 5.2 - Система распределенной обработки данных
Распределенная обработка данных - обработка данных, выполняемая на независимых, но связанных между собой компьютерах, представляющих распределенную систему.
В основе распределенных вычислений лежат две основные идеи:
§ много организационно и физически распределенных пользователей, одновременно работающих с общими данными - общей базой данных (пользователи с разными именами, которые могут располагаться на различных вычислительных установках, с различными полномочиями и задачами);
§ логически и физически распределенные данные, составляющие и образующие тем не менее, общую базу данных (отдельные таблицы, записи и даже поля могут располагаться на различных вычислительных установках или входить в различные локальные базы данных).
Дня реализации распределенной обработки данных были созданы многомашинные ассоциации, структура которых разрабатывается по одному из следующих направлений:
§ многомашинные вычислительные комплексы (МВК);
§ компьютерные (вычислительные) сети.
Многомашинный вычислительный комплекс - группа установленных рядом вычислительных машин, объединенных с помощью специальных средств сопряжения и выполняющих совместно единый информационно-вычислительный процесс. Под процессом понимается некоторая последовательность действий для решения задачи, определяемая программой.
Многомашинные вычислительные комплексы могут быть:
§ локальными, при условии установки компьютеров в одном помещении, не требующих для взаимосвязи специального оборудования и каналов связи;
§ дистанционными, если некоторые компьютеры комплекса установлены на значительном расстоянии от центральной ЭВМ и для передачи данных используются телефонные каналы связи.
Пример 1. Три ЭВМ объединены в комплекс для распределения заданий, поступающих на обработку. Одна из них выполняет диспетчерскую функцию и распределяет задания в зависимости от занятости одной из двух других обрабатывающих ЭВМ. Это локальный многомашинный комплекс.
Пример 2. ЭВМ, осуществляющая сбор данных по некоторому региону, выполняет их предварительную обработку и передает для дальнейшего использования на центральную ЭВМ по телефонному каналу связи. Это дистанционный многомашинный комплекс.
Компьютерная (вычислительная) сеть - вычислительная система, включающая в себя несколько компьютеров, терминалов и других аппаратных средств, соединенных между собой линиями связи, обеспечивающими передачу данных
Терминал - устройство, предназначенное для взаимодействия пользователя с вычислительной системой или сетью ЭВМ. Состоит из устройства ввода (чаще всего это клавиатура) и одного или нескольких устройств вывода (дисплей, принтер и т.д.).
Унификация взаимодействия прикладных компонентов с ядром информационных систем в виде SQL-серверов, наработанная для клиент-серверных систем, позволила выработать аналогичные решения и для интеграции разрозненных локальных баз данных под управлением настольных СУБД в сложные децентрализованные гетерогенные распределенные системы. Такой подход получил название объектного связывания данных.
С узкой точки зрения, технология объектного связывания данных решает задачу обеспечения доступа из одной локальной базы, открытой одним пользователем, к данным в другой локальной базе (в другом файле), возможно находящейся на другой вычислительной установке, открытой и эксплуатируемой другим пользователем.
Решение этой задачи основывается на поддержке современными "настольными" СУБД (MS Access, MS FoxPro, dBase и др.) технологии "объектов доступа к данным" - DАО.
При этом следует отметить, что под объектом понимается интеграция данных и методов, их обработки в одно целое (объект), на чем основываются объектно-ориентированное программирование и современные объектно-ориентированные операционные среды. Другими словами, СУБД, поддерживающие DАО, получают возможность внедрять и оперировать в локальных базах объектами доступа к данным, физически находящимся в других файлах, возможно на других вычислительных установках и под управлением других СУБД.
Технически технология DАО основана на уже упоминавшемся протоколе ODBC, который принят за стандарт доступа не только к данным на SQL-серверах клиент-серверных систем, но и в качестве стандарта доступа к любым данным под управлением реляционных СУБД.
Непосредственно для доступа к данным на основе протокола ODBC используются специальные программные компоненты, называемые драйверами ODBC (инициализируемые на тех установках, где находятся данные).
Схематично принцип и особенности доступа к внешним базам данных на основе объектного связывания иллюстрируются на рис. 5 7.
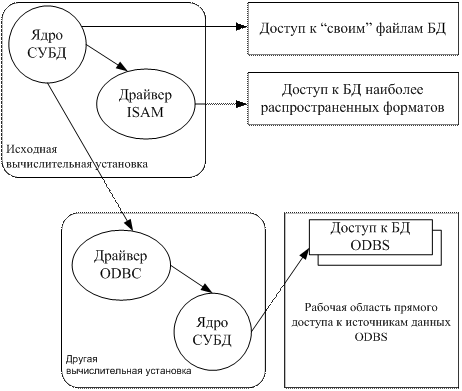
Рис. 5.7 - Принцип доступа к внешним данным па основе ODBC
Прежде всего, современные настольные СУБД обеспечивают возможность прямого доступа к объектам (таблицам, запросам, формам) внешних баз данных "своих" форматов. Иначе говоря, в открытую в текущем сеансе работы базу данных пользователь имеет возможность вставить специальные ссылки-объекты и оперировать с данными из другой (внешней, т. е. не открываемой специально в данном сеансе) базы данных.
Объекты из внешней базы данных, вставленные в текущую базу данных, называются связанными и, как правило, имеют специальные обозначения для отличия от внутренних объектов. При этом следует подчеркнуть, что сами данные физически в файл (файлы) текущей базы данных не помещаются, а остаются в файлах своих баз данных. В системный каталог текущей базы данных помещаются все необходимые для доступа сведения о связанных объектах - внутреннее имя и внешнее, т. е. истинное имя объекта во внешней базе данных, полный путь к файлу внешней базы и г. п.
Связанные объекты для пользователя ничем не отличаются от внутренних объектов. Пользователь может также открывать связанные во внешних базах таблицы данных, осуществлять поиск, изменение, удаление и добавление данных, строить запросы по таким таблицам и т. д. Связанные объекты можно интегрировать в схему внутренней базы данных, т е. устанавливать связи между внутренними и связанными таблицами.
Технически оперирование связанными объектами из внешних баз данных "своего" формата мало отличается от оперирования с данными из текущей базы данных.
Ядро СУБД при обращении к данным связанного объекта по системному каталогу текущей базы данных находит сведения о месте нахождения и других параметрах соответствующего файла (файлов) внешней базы данных и прозрачно (т. е. невидимо для пользователя) открывает этот файл (файлы). Далее обычным порядком организует в оперативной памяти буферизацию страниц внешнего файла данных для непосредственно доступа и манипулирования данными.
Следует также заметить, что на основе возможностей многопользовательского режима работы с файлами данных современных операционных систем, с файлом внешней базы данных, если он находится на другой вычислительной установке, может в тот же момент времени работать и другой пользователь, что и обеспечивает коллективную обработку общих распределенных данных.
Подобный принцип построения распределенных систем при больших объемах данных в связанных таблицах приведет к существенному увеличению трафика сети, так как по сети постоянно передаются даже не наборы данных, а страницы файлов баз данных, что может приводить к пиковым перегрузкам сети. Поэтому представленные схемы локальных баз данных со взаимными связанными объектами нуждаются в дальнейшей тщательной проработке.
Не менее существенной проблемой является отсутствие надежных механизмов безопасности данных и обеспечения ограничений целостности. Совместная работа нескольких пользователей с одними и теми же данными обеспечивается только функциями операционной системы по одновременному доступу к файлу нескольких приложений.
Аналогичным образом обеспечивается доступ к данным, находящимся в базах данных наиболее распространенных форматов других СУБД, таких, например, как базы данных СУБД FoxPro, dBASE.
При этом доступ может обеспечиваться как непосредственно ядром СУБД, так и специальными дополнительными драйверами ISAM (Indexed Sequential Access Method), входящими, как правило, в состав комплекта СУБД.
Объектное связывание ограничивается только непосредственно таблицами данных, исключая другие объекты базы данных (запросы, формы, отчеты), реализация и поддержка которых зависят от специфики конкретной СУБД.
Определенной проблемой технологий объектного связывания является появление "брешей" в системах защиты данных и разграничения доступа. Вызовы драйверов ODBC для осуществления процедур доступа к данным помимо пути, имени файлов и требуемых объектов (таблиц), если соответствующие базы защищены, содержат в открытом виде пароли доступа, в результате чего может быть проанализирована и раскрыта система разграничения доступа и защиты данных.

