 2014-02-24
2014-02-24 2258
2258Простейшее цифровое представление речи заключается в непосредственной дискретизации непрерывного речевого сигнала в соответствии с теоремой Котельникова (см. Лекцию №4 «Дискретные сигналы»). Такое представление речевого сигнала соответствует импульсно-кодовой модуляции (ИКМ). Выбор частоты дискретизации зависит от конкретных условий решаемой задачи. Фрикативные звуки речи занимают сравнительно широкую полосу частот (примерно до 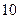 кГц). Вокализованные звуки, значительно влияющие на разборчивость речи, занимают полосу частот до
кГц). Вокализованные звуки, значительно влияющие на разборчивость речи, занимают полосу частот до 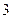 кГц. Таким образом, обычно используемая частота дискретизации выбирается в пределах от
кГц. Таким образом, обычно используемая частота дискретизации выбирается в пределах от 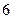 до
до 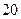 кГц.
кГц.
Следует отметить, что количество операций, выполняемое при обработке речи, находится в прямой зависимости от частоты дискретизации. Поэтому в соответствии с условиями решаемой задачи необходимо по возможности снижать частоту дискретизации. Для этого перед дискретизацией речевой сигнал предварительно обрабатывают с помощью аналогового ФНЧ, устраняя нежелательные высокочастотные составляющие.
Выбор числа двоичных единиц 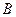 для кодирования одного отсчета речевого сигнала определяется задачей обработки. Объективной характеристикой точности представления сигнала посредством ИКМ является шум квантования:
для кодирования одного отсчета речевого сигнала определяется задачей обработки. Объективной характеристикой точности представления сигнала посредством ИКМ является шум квантования:
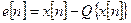 , (1)
, (1)
где 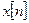 – исходная речевая последовательность;
– исходная речевая последовательность; 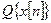 – оператор квантования.
– оператор квантования.
Можно показать, что при равномерном квантовании отношение сигнал шум (ОСШ),выраженное в децибелах, будет равно:
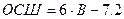 . (2)
. (2)
Например, если 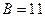 , то
, то 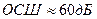 , что служит мерой качества хорошего телефонного канала связи. Добавление одного двоичного разряда для представления отсчета речевого сигнала увеличивает
, что служит мерой качества хорошего телефонного канала связи. Добавление одного двоичного разряда для представления отсчета речевого сигнала увеличивает 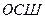 на дБ. Таким образом, для представления речевых сигналов посредством ИКМ требуется скорость передачи в пределах от
на дБ. Таким образом, для представления речевых сигналов посредством ИКМ требуется скорость передачи в пределах от 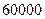 до
до 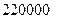 бит/с. Это необходимо учитывать при компьютерном хранении и обработке речи. Например, речевой сигнал длительностью
бит/с. Это необходимо учитывать при компьютерном хранении и обработке речи. Например, речевой сигнал длительностью 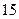 с будет занимать объём памяти примерно в
с будет занимать объём памяти примерно в 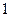 Мбайт.
Мбайт.
Для снижения скорости передачи речевых сигналов и, соответственно, уменьшения объемов требуемой памяти сокращают число двоичных единиц, выделяемых на один отсчет. Ключом к решению задачи является учет того обстоятельства, что для вокализованных участков речи, имеющих большую амплитуду, можно использовать большой шаг квантования, а для невокализованных – мелкий, т.е. квантование должно выполняться с неравномерным шагом. Это стабилизирует отношение сигнал/шум и делает его, не зависящим от уровня сигнала.
Чтобы относительная ошибка квантования оставалась постоянной при изменении амплитуды речевого сигнала, уровни квантования должны быть распределены по логарифмическому закону. Вместо распределения уровней квантования по логарифмическому закону можно выполнять квантование логарифма речевого сигнала. В этом случае перед квантованием речевой сигнал обрабатывают в компрессоре,а при восстановлении исходного речевого сигнала используют экспандер. Совокупность этих двух устройств называют компандером. Одной из часто используемых характеристик компрессии является функция:
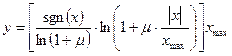 . (3)
. (3)
Функция компрессии (3) называется 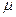 -законом. Экспандер реализует соответствующую обратную функцию:
-законом. Экспандер реализует соответствующую обратную функцию:
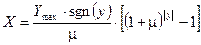 . (4)
. (4)
При использовании компрессора, функционирующего на основе (3), для обеспечения 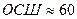 дБ достаточно
дБ достаточно 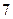 бит на один отсчет речевого сигнала, т.е. скорость передачи может быть снижена по сравнению с равномерным квантованием в
бит на один отсчет речевого сигнала, т.е. скорость передачи может быть снижена по сравнению с равномерным квантованием в 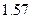 раз. Отметим, что формулы (3) и (4) требуют, чтобы все отсчеты находились в интервале
раз. Отметим, что формулы (3) и (4) требуют, чтобы все отсчеты находились в интервале 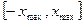 . Любой отсчет, не принадлежащий указанному интервалу, полагается равным
. Любой отсчет, не принадлежащий указанному интервалу, полагается равным 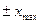 . Значения константы обычно равны
. Значения константы обычно равны 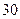 ;
; 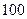 ;
; 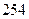 .
.
Другой подход к снижению скорости передачи основан на учете избыточности речевого сигнала. Соседние отсчеты речевого сигнала, дискретизированного в соответствии с теоремой Котельникова, имеют сравнительно высокую корреляцию. Это позволяет по предыдущим отсчетам предсказать текущее значение речевого сигнала. Предположим, что 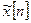 является предсказанным значением речевого сигнала . Если это предсказание является достаточно точным, то ошибка предсказания:
является предсказанным значением речевого сигнала . Если это предсказание является достаточно точным, то ошибка предсказания:
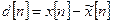 (5)
(5)
должна иметь небольшую величину, и, следовательно, дисперсия ошибки квантования разностного сигнала будет меньше, чем дисперсия ошибки квантования отсчетов речи . Таким образом, квантователь с заданным количеством уровней обеспечит меньшую погрешность при квантовании разностного сигнала, чем при квантовании исходного сигнала. Поэтому для представления разностного сигнала требуется меньшее число двоичных разрядов.
Квантователь, построенный на использовании указанного подхода, называется дифференциальным (разностным) импульсно-кодовым модулятором (ДИКМ). Схема его показана на рис.2. Здесь 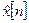 представляет восстановленный сигнал, образуемый путем добавления квантованного разностного сигнала
представляет восстановленный сигнал, образуемый путем добавления квантованного разностного сигнала 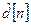 к .
к .
Кодер: Декодер:
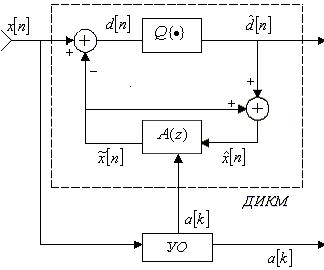
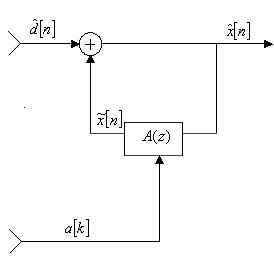
Рис.2. Общая схема ДИКМ.
Покажем, что восстановленный сигнал будет отличаться от на величину шума квантования разностного сигнала:
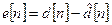 . (6)
. (6)
Заметим, что:
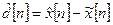 . (7)
. (7)
Тогда, подставляя (5) и (7) в (6), получим искомый результат:
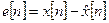 . (8)
. (8)
Для предсказания значений речевого сигнала в схеме используется нерекурсивный ЦФ с передаточной функцией 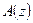 , реализующей уравнение:
, реализующей уравнение:
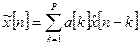 (9)
(9)
В простейшем случае для предсказания используют фильтр первого порядка.
В том случае, когда для кодирования разностного сигнала используется один бит, рассматриваемый модулятор называется дельта-модулятором. Обычно дельта модулятор функционирует на более высоких частотах дискретизации, чем ДИКМ.
Для уменьшения ошибки квантования в ДИКМ может применяться адаптивное изменение шага квантования и коэффициентов предсказывающего фильтра. Такие модуляторы называются адаптивными дифференциальными импульсно-кодовыми модуляторами (АДИКМ). Коэффициенты предсказывающего фильтра вычисляются в устройстве оценивания (УО) так, чтобы минимизировать дисперсию ошибки предсказания (5). Оценивание коэффициентов предсказывающего фильтра возможно как по входной речевой последовательности , так и по восстановленной последовательности . Основные принципы вычисления коэффициентов линейного предсказания будут рассмотрены ниже.
АДИКМ позволяет снизить скорость передачи до 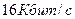 . Благодаря этому АДИКМ широко применяется для представления речевых сигналов в компьютерных системах.
. Благодаря этому АДИКМ широко применяется для представления речевых сигналов в компьютерных системах.
Тема: ИНФОРМАЦИОННЫЕ ТЕХНОЛОГИИ В
ОБРАБОТКЕ РЕЧЕВЫХ И АУДИО СИГНАЛОВ.
Лекция №10. Анализ речевых сигналов.
Психоакустическая модель восприятия звука.
10.1. Анализ речевых сигналов во временной области.
При решении многих задач обработки речи интерес представляют временные характеристики речевых сигналов. Поскольку речь является нестационарным процессом, то ее принято анализировать на коротких участках ( мс), где спектрально-корреляционные характеристики остаются примерно постоянными.
мс), где спектрально-корреляционные характеристики остаются примерно постоянными.
Одним из важных параметров речевого сигнала является его энергия:
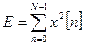 . (1)
. (1)








