 2014-02-09
2014-02-09 440
440К вторичным методам статистической обработки результатов наблюдений относят методы, позволяющие судить о динамике изменения отдельных статистик выборки и статистических связях, существующих между случайными величинами, которые исследуются в данном эксперименте (например, регрессионный анализ, корреляционный анализ, методы сравнения первичных статистик у двух выборок и др.).
■ Регрессия - зависимость среднего значения (точнее, математического ожидания) случайной величины Y от величины х. При этом принято говорить: «регрессия Y на x». Независимая величина x может быть не обязательно случайной.
Регрессионный анализ устанавливает формы зависимости между случайной величиной Y и значениями одной или нескольких переменных величин, причем значения последних считаются точно заданными (в простейшем случае предполагается линейная зависимость). Такая зависимость обычно определяется некоторой математической моделью (уравнением регрессии), содержащей несколько неизвестных параметров. Прогнозирование - одна из важных областей применения регрессионного анализа в педагогике.
 Эмпирическое уравнение регрессии имеет вид y = bx + a, где a – свободный член уравнения регрессии, b - коэффициент регрессии, которые вычисляются по формулам:
Эмпирическое уравнение регрессии имеет вид y = bx + a, где a – свободный член уравнения регрессии, b - коэффициент регрессии, которые вычисляются по формулам:
Здесь` x и` y - выборочные средние арифметические:
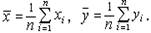 |
Пример 3.16. В таблице 3.6 приведены результаты тестирования (в баллах) показанные группой школьников (n =10), изучающих ТЕМУ №1 и ТЕМУ №2. В этом примере обе величины (и зависимая и независимая) являются случайными, а их значения получаются по случайной выборке из генеральной совокупности. Найдите уравнение регрессии.








