 2014-02-13
2014-02-13 1382
1382Одной из основных трудностей при принятии решений (даже у естественного интеллекта) является наличие неопределенностей при получении, формировании и представлении знаний.
Мы говорим: «Я поздно пришел домой». «Поздно» - это во сколько?
Или: «Это дорогой компьютер». А «дорогой» - это сколько?
Интеллектуализированным информационным системам во многом труднее оценивать ситуацию, воспринимать события и явления в предметной области, решать задачи контроля, управления, поиска и другие при наличии нечеткого представления знаний.
Особенностью большинства интеллектуализированных информационных систем является их функционирование в сложных предметных областях со множеством объектов, разнообразных процессов и носителей естественного интеллекта - людей. В этих условиях при исследовании предметных областей и описании их математическими моделями возникает проблема дефицита информации.
Дефицит информации возникает по следующим причинам:
- из-за неполноты (ограниченности) информации, описывающей объект или наблюдаемый процесс (явление);
- из-за качественного (неформализованного) представления информации, порождаемой трудно формализуемой ситуацией;
- из-за нечеткости информации, появляющейся в условиях неопределенности.
Проблему, связанную с недостатком информации, решают следующими способами:
- стараются уменьшить дефицит информации;
- примиряются с недостатком информации и продолжают исследование в сложившихся условиях.
При попытке формализовать человеческие знания исследователи столкнулись с проблемой, затруднявшей использование традиционного математического аппарата для их описания. Существует целый класс описаний, оперирующих качественными характеристиками объектов (много, мало, сильный, очень сильный и т. п.). Эти характеристики обычно размыты и не могут быть однозначно интерпретированы, однако содержат важную информацию (например, «Одним из возможных признаков гриппа является высокая температура»).
Кроме того, в задачах, решаемых интеллектуальными системами, часто приходится пользоваться неточными знаниями, которые не могут быть интерпретированы как полностью истинные или ложные (логические true/false или 0/1). Существуют знания, достоверность которых выражается некоторой промежуточной цифрой, например 0.7.
Лингвистическая переменная (ЛП) - это переменная, значение которой определяется набором вербальных (то есть словесных) характеристик некоторого свойства.
Например, ЛП «рост» определяется через набор {карликовый, низкий, средний, высокий, очень высокий}.
Значения лингвистической переменной (ЛП) определяются через так называемые нечеткие множества (НМ), которые в свою очередь определены на некотором базовом наборе значений или базовой числовой шкале, имеющей размерность. Каждое значение ЛП определяется как нечеткое множество (например, НМ «низкий рост»).
Нечеткое множество определяется через некоторую базовую шкалу В и функцию принадлежности НМ - m(х), хÎВ, принимающую значения на интервале [0...1]. Таким образом, нечеткое множество В - это совокупность пар вида (х, m(х)), где хÎВ.
Часто встречается и такая запись:
В = å(хi / m(хi)), i=1,n.
где хi - i-e значение базовой шкалы.
Функция принадлежности определяет субъективную степень уверенности эксперта в том, что данное конкретное значение базовой шкалы соответствует определяемому НМ. Эту функцию не стоит путать с вероятностью, носящей объективный характер и подчиняющейся другим математическим зависимостям.
Например, для двух экспертов определение НМ «высокая» для ЛП «цена автомобиля» в условных единицах может существенно отличаться в зависимости от их социального и финансового положения.
«Высокая_цена_автомобиля_1» - {50000/1 + 25000/0.8 + 10000/0.6 + 5000/0.4}.
«Высокая_цена_автомобиля_2» = {25000/1 + 10000/0.8 + 5000/0.7 + 3000/0.4}
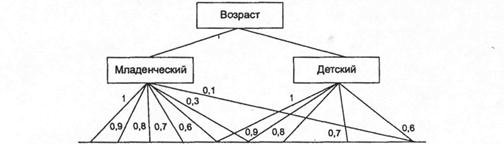
Рассмотрим пример. Пусть перед нами стоит задача интерпретации значений ЛП «возраст», таких как «молодой» возраст, «преклонный» возраст или «переходный» возраст. Определим «возраст» как ЛП (рис. 5.9). Тогда «молодой», «преклонный», «переходный» будут значениями этой лингвистической переменной.
Полный базовый набор значений ЛП «возраст» следующий: В - {младенческий, детский, юный, молодой, зрелый, преклонный, старческий}.

Рис. 5.9 - Лингвистическая переменная «возраст» и нечеткие множества, определяющие ее значения
Для ЛП «возраст» базовая шкала - это числовая шкала от 0 до 120, обозначающая количество прожитых лет, а функция принадлежности определяет, насколько мы уверены в том, что данное количество лет можно отнести к данной категории возраста. На рис. 5.10 отражено, как одни и те же значения базовой шкалы могут участвовать в определении различных НМ.
0 1 2 3 4 5 6 7 8 9 10
Рис. 5.10 – Формирование нечетких множеств
Например, определить значение НМ «младенческий возраст» можно так:
«младенческий» = { 0.5/1 + 1/0.9 + 2/0.8 + 3/0.7 + 4/0.6 + 5/0.3 + 10/0.1}.
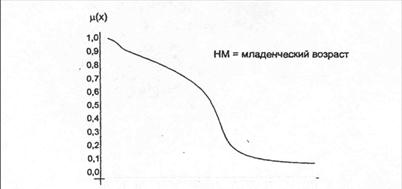
Рисунок 5.11 иллюстрирует оценку НМ неким усредненным экспертом, который ребенка до полугода с высокой степенью уверенности относит к младенцам (m = 1). Дети до четырех лет причисляются к младенцам тоже, но с меньшей степенью уверенности (0.5< m <0.9), а в десять лет ребенка называют так только в очень редких случаях - к примеру, для девяностолетней бабушки и 15 лет может считаться младенчеством. Таким образом, нечеткие множества позволяют при определении понятия учитывать субъективные мнения отдельных индивидуумов.

0 1 2 3 4 5 6 7 8 9 10 11 Возраст
Рис. 5.11 - График функции принадлежности нечеткому множеству «младенческий возраст»
Усиление или ослабление лингвистических понятий достигается введением специальных квантификаторов.
Например, если понятие «старческий возраст» определяется как
«старческий» = { 60/0.6 + 70/0.8 + 80/0.9 + 90/1},
то понятие «очень старческий возраст» определится как
con(А) = А2 = å(хi / mi2),
i
то есть
«очень старческий возраст» = {60/0.36 + 70/0.64 + 80/0.81 + 90/1}.
В настоящее время в большинство инструментальных средств разработки систем, основанных на знаниях, включены элементы работы с нечеткими множествами, кроме того, разработаны специальные программные средства реализации так называемого нечеткого вывода, например «оболочка» FuzzyCLIPS.

