2014-10-30
2014-10-30 501
501В методе Байеса подразумевается использование оценочной базы — двух корпусов электронных писем, один из которых составлен из спама, а другой — из обычных писем. Для каждого из корпусов подсчитывается частота использования каждого слова, после чего вычисляется весовая оценка (от 0 до 1), характеризующая условную вероятность того, что сообщение с этим словом является спамом. Значения весов, близкие к ½, не учитываются при интегрированном расчете, поэтому слова с такими весами игнорируются и удаляются из словарей.
В соответствии с методом, предложенным Полом Грэмом (Paul Graham), если сообщение содержит n слов с весовыми оценками w1...wn, то оценка условной вероятности того, что письмо окажется спамом, основанная на данных из оценочных корпусов, вычисляется по формуле:
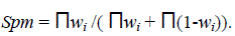
Приведенная формула обосновывается следующим соображением. Предполагается, что S – cобытие, заключающееся в том, что письмо – спам, А – событие, заключающееся в том, что письмо содержит слово t. Тогда, в соответствии с формулой Байеса, справедливо:
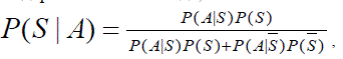
Если изначально не известно, является письмо спамом или нет, исходя из опыта предполагается, что P (S) = λ P(S), из чего следует:
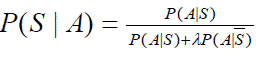
Далее формула обобщается следующим образом. Предполагается, что A1 и A2 – это события, заключающиеся в том, что письмо содержит слова t1 и t2. При этом вводится допущение, что эти события независимы (поэтому метод называется «наивным» байесовским). Условная вероятность того, что письмо, содержащее оба слова (t1 и t2) является спамом, равна:
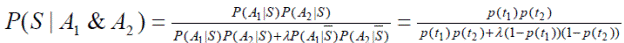
Обобщением формулы на случай произвольного количества слов и λ =1 и является формула П. Грэма.
Следует отметить, что широкое применение находит именно значение λ =1. Хотя это несколько упрощает вычисления, но серьезно искажает действительность и снижает качество.
На практике на основе словарей, которые постоянно модифицируются, для каждого сообщения рассчитывается значение Spm. Если оно больше некоторого порогового, то сообщение считается спамом.
5) Недостатки рассмотренных моделей:
- Булева модель – невысокая эффективность поиска, жесткий набор операторов, невозможность ранжирования.
- Векторно-пространственная модель связана с расчетом массивов высокой размерности, малопригодна для обработки больших массивов данных.
- Вероятностная модель характеризуется низкой вычислительной масштабируемостью, необходимостью постоянного обучения системы.
Приведенные классические модели изначально предполагали рассмотрение документов как множества отдельных слов, не зависящих друг от друга. Такая упрощающая концепция имеет название «Bag of Words». В реальных системах это упрощение преодолевается, например, расширенная булева модель учитывает контекстную близость (операторы NEAR, ADJ во многих известных системах). Системы, базирующиеся на вероятностной модели учитывают вхождение словосочетаний и связи отдельных терминов, хотя большинство из известных систем борьбы со спамом, построенные на вероятностной модели все-таки базируются на упрощенном подходе независимости отдельных слов.
Кроме представленных существуют и другие методы поиска, например, семантические, в рамках которых делаются попытки организации смыслового поиска за счет анализа грамматики текста, использования баз знаний, тезаурусов, онтологий, реализующих семантические связи между отдельными словами и их группами. Такие подходы пока остаются очень затратными, область их применения – профессиональные аналитические системы.