 2014-10-30
2014-10-30 342
342В этом алгоритме ключевые слова (устойчивые словосочетания) из сообщений или отдельные сообщения информационных потоков, порождаемых информационными Web-сайтами, выступают аналогами дискретных сигналов. Каждому сообщению приписывается вес, который равен усредненной частоте появления во всем информационном потоке значимых ключевых слов. Очевидно, чем меньше этот вес, тем документ более уникальный. Рассматривается двухпроходный алгоритм формирования словаря уникальных слов из входного массива из N сообщений (первый проход), а также весов отдельных сообщений (второй проход). Вес сообщения определяется по формуле:
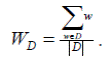
где WD – вес сообщения, w – ключевое слово из сообщение, |D| - количество ключевых слов в документе. В рамках модели как вес ключевых слов употребится частота их появлений во входном информационном потоке. В свою очередь, эта частота зависит от объема самого потока и от количества уникальных слов, т.е. объема автоматически формированного словаря уникальных слов.








