 2015-01-30
2015-01-30 753
753Одним из наиболее "узких" мест при выполнении алгоритмов ЦОС является обмен информацией с памятью, который состоит из пересылки данных и выборки инструкций. Предположим, что нам необходимо выполнить операцию умножения двух чисел, расположенных в различных ячейках памяти с сохранением результата в регистре процессора. Для этого следует извлечь из памяти три слова: два операнда, подлежащие перемножению, и инструкцию.
Рис.1 помогает понять, как эта операция реализуется на микропроцессорах с традиционной архитектурой фон Неймана (John Von Neumann, 1903-1957), содержащих одно пространство памяти и одну шину для обмена данными между ней и центральным процессором. Поэтому перемножение двух чисел требует как минимум трех циклов только на обращение к памяти!
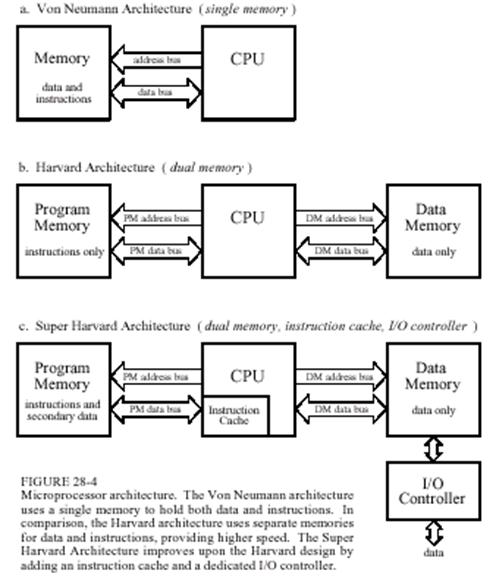
Рис.1.
В отличие от этого Гарвардская архитектура (разработана в 40-х годах в Гарвардском университете под руководством Говарда Айкена, Howard Aiken, 1900-1973) предполагает наличие двух раздельных пространств для хранения данных и инструкций и отдельными шинами для каждого из них. Поскольку шины функционируют независимо, инструкция и данные могут быть извлечены одновременно и сокращает количество тактов на обращение к памяти в нашем примере до двух. Такая архитектура используется в большинстве современных ЦСП, возможно с некоторыми модификациями (в частности, Модифицированная Гарвардская архитектура предполагает возможность хранения в памяти команд не только инструкций, но и данных).
Следующим уровнем сложности является Супер-Гарвардская архитектура (SHARC – Super Harvard ARChitecture, термин введен фирмой Analog Devices), одними из основных отличий которых от Гарвардской архитектуры является наличие кэша команд и контроллер ввода/вывода.
Рассмотрим, например, как наличие кэша инструкций позволяет повысить производительность. Как было отмечено выше, во избежание двойного обращения к памяти данных за операндами, можно разместить один из них в памяти команд. На первый взгляд ситуация не изменилась: теперь необходимы два обращения к памяти команд за инструкцией и данными. Однако если учесть, что большинство ЦОС алгоритмов содержат циклы и большую часть процессорного времени выполняется обработка тел циклов, то становится ясно, что одни и те же инструкции в ходе нескольких итераций одного цикла будет выбирать многократно. Т.е. для повышения производительности подсистемы "процессор-память" достаточно поместить те инструкции, выборка которых конфликтует с выборкой данных в кэш-память процессора. В этом случае дополнительное количество тактов из-за конфликта при обращении к памяти программ будет потрачено лишь при первом проходе: на втором и последующих проходах требуемая инструкция будет извлекаться из кэша, а оба операнда за 1 (!) такт из памяти данных и программ.
Второй особенностью SHARC-архитектуры и архитектур других современных ЦСП является наличие контроллера ввода/вывода. Коммуникационные порты ЦСП (последовательные и линки) обеспечивают скорости потокового обмена данными между процессором и внешними устройствами (АЦП, ЦАП, другими процессорами) порядка сотен Мбит/с. Чтобы обеспечить ввод/вывод данных из процессора с такой скоростью не снижая вычислительных возможностей процессора контроллер ввода/вывода посредством механизма прямого доступ к памяти (Direct Memory Access, DMA) позволяет записывать и считывать данные напрямую из внутренней памяти процессора, освобождая процессорное ядро от этой работы. Для одновременного доступа к внутренней памяти и процессорного ядра и DMA-контроллера (и, возможно, других блоков), внутренняя память обычно выполняется как многопортовая.
К другим особенностям современных ЦСП относятся:
- генераторы адресов данных для каждого из пространств памяти, содержащие по 4-8 групп регистров-указателей, позволяющие хранить одновременно, без сохранения в памяти до нескольких десятков адресов буферов (массивов) данных; + бит-реверсная адресация;
- методы, характерные для универсальных RISC-процессоров: конвейерный режим (обычно применяется двух- или трехкаскадный конвейер, что позволяет одновременно выполнять две или три инструкции на разных стадиях обработки), размещение операндов большинства команд в регистрах, использование теневых регистров для сохранения состояния вычислений при переключении контекста (при прерываниях), аппаратная поддержка циклов (без дополнительных тактов ожидания);
- аппаратный умножитель, применяющийся для сокращения времени выполнения одной из основных операций ЦОС – операции умножения. В процессорах общего назначения эта операция реализовывается за несколько тактов сдвига и сложения и занимает много времени, а в ЦСП благодаря специализированному умножителю выполняется за один такт;
- возможность выполнения нескольких вычислительных операций одновременно благодаря независимости блоков АЛУ, умножителя, сдвигателя, генератора адресов, VLIW-архитектура;
- возможность выполнения одинаковых вычислительных операций над различными наборами данных одновременно (SIMD-технология);
- система команд ЦСП оптимизирована для выполнения базовых задач цифровой обработки сигналов (умножение с накоплением, битовые операции (для графики), инверсия битов адреса (для БПФ), кольцевые буфера (для фильтров) и др.;
- наличие (в дополнение к коммуникационным портам) собственных встроенных АЦП и ЦАП (в этом случае процессор относится к устройствам типа mixed signal).








