 2015-01-30
2015-01-30 544
544Традиционно многопроцессорная система строится по одной из 2-х схем взаимодействия между процессорами: взаимодействия типа "точка-точка" через выделенные линии и взаимодействия через единую внешнюю разделяемую память с использованием параллельной общей внешней шины.
При соединении "точка-точка" для связи между процессорами используется выделенный канал. В большинстве подобных систем каждый процессорный узел имеет более одного соединения и, следовательно, должен иметь несколько портов. В схеме с разделяемой шиной для объединения процессоров используется один канал.
1.1.1. Соединения типа "точка-точка"
Соединения типа "точка-точка" по выделенным каналам используется в задачах, требующих высокой скорости вычислений и ограниченной гибкости (рис.1). Общий алгоритм обработки данных разделяется на несколько этапов (частей), каждый из которых реализуется в отдельном процессоре (принцип конвейеризации). Данные последовательно проходят все этапы обработки.
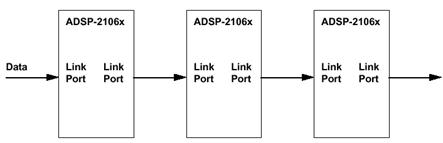
Рис.1
Благодаря большому объему внутренней памяти SHARC-процессоров (4 Мбит) этот способ подходит для большинства задач с фиксированным алгоритмом обработки данных. Его реализация позволяет снизить сложность системы, размеры платы, стоимость.
Некоторые классические примеры схем взаимодействия через соединения типа "точка-точка" приведены на рис.2. Для решения определенного класса задач может использоваться топология массива SIMD, в котором SHARC-процессоры соединены в 2-х или 3-х мерную сетку. В этом случае ведущий (master) процессор обеспечивает координацию процессоров, загрузку в них потока команд. Линк-коммуникации обеспечивают передачу данных между "соседними" процессорами. Данные могут вводиться/выводиться в систему, например, через последовательные порты.
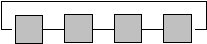
| КОЛЬЦО количество процессоров: p диаметр: p /2 длина бисекции: 2 |

| 2-D СЕТЬ количество процессоров: p = k 2 диаметр: 2 (sqrt(p)-1) длина бисекции: sqrt(p) |
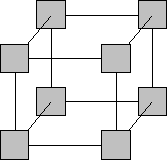
| 3D - ГИПЕРКУБ количество процессоров: 2 d диаметр: log p длина бисекции: p /2 |
Рис.2
Достоинствами схемы взаимодействия через соединения типа "точка-точка" является большое количество процессоров в системе, которое может поддерживаться без снижения скорости обмена данными. К тому же, поскольку схема является однородной и предсказуемой, она может использоваться как часть SIMD-системы.
Недостатком взаимодействия через линк-порты является то, что скорость взаимодействия через линк значительно ниже, чем по внешней шине и не превышает 40 Мбайт/с. Кроме того, требуется дополнительные усилия по программированию линк-обмена причем с двух сторон.
1.1.2. Кластерная многопроцессорность
 Кластерное соединение (кластер) состоит из нескольких процессоров, соединенных по внешней параллельной шине и имеющих благодаря этому межпроцессорный доступ к внутренней памяти каждого процессора и доступ к единой разделяемой внешней памяти (рис.2).
Кластерное соединение (кластер) состоит из нескольких процессоров, соединенных по внешней параллельной шине и имеющих благодаря этому межпроцессорный доступ к внутренней памяти каждого процессора и доступ к единой разделяемой внешней памяти (рис.2).
Встроенная логика управления внешней шиной позволяет разделять общую внешнюю шину (без использования дополнительных аппаратных средств) между 6 SHARC-процессорами и хост-процессором.
Такой подход используется при разработке систем, предназначенных для решения широкого класса задач и требующих значительной гибкости.
Примерами схем взаимодействия данных через разделяемую шину являются системы с доступом к однородной памяти (uniform memory access, UMA) и системы с доступом к неоднородной памяти (non-uniform memory access, NUMA). В UMA-системах ЦСП получают доступ к глобальной разделяемой памяти с использованием механизма переключения. Время доступа к глобальной памяти одинаково для всех процессоров. В качестве механизма переключения могут использоваться матричный переключатель (cross bar switch) или схема арбитража внешней шины (bus arbitration). Достоинством использования матричного переключателя является возможность наращивания числа процессоров, до тех пор, пока это позволяет стоимость системы. Механизм арбитража шины по сравнению с матричным переключателем характеризуется низкой стоимостью, но имеет ограниченные возможности по увеличению числа процессоров в системе.
В NUMA-системах каждый процессор имеет свою собственную локальную память, доступную через общее универсальное адресное пространство. Это позволяет процессору выполнять доступ к локальной памяти быстрее, чем к другой памяти в системе. Пример архитектуры NUMA-системы приведен на рис.2. В подобной системе каждый процессор может получить доступ не только к своей локальной или глобальной памяти, но и к локальной памяти других процессоров.
Для устранения ограничений, связанных с использованием общей шины (в каждый момент времени только два ADSP могут обмениваться данными) используются соединения типа "точка-точка" через линк-порты (рис.3). Одновременно на каждом процессоре могут быть задействованы до 6 линк-портов.
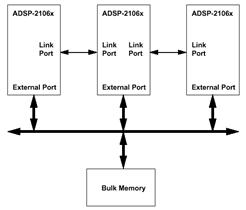
Рис.3
Схема с разделяемой шиной может использоваться с меньшим числом процессоров. Ее преимуществами являются простота в реализации и легкость обмена данными.








