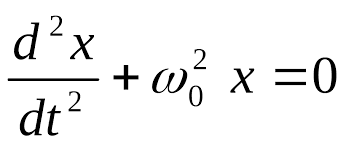2015-01-30
2015-01-30 711
711Код Шеннонапозволяет построить почти оптимальный код с длинами кодовых слов Li < - log pi +1. Тогда Lcp <H(p1, …,pn) +1. Код Шеннона строится следующим образом.
1. Упорядочим символы исходного алфавита А={ a1,a2,…,an } по убыванию их вероятностей: p1≥p2≥p3≥…≥pn.
2. Составим нарастающие суммы вероятностей Qi:
Q0=0, Q1=p1, Q2=p1+p2, Q3=p1+p2+p3, …, Qn=1.
3. Представим Qi в двоичной системе счисления и возьмем в качестве кодового слова первые é- log2 pi ù знаков после запятой.
Для вероятностей, представленных в виде десятичных дробей, удобно определить длину кодового слова Li из соотношения
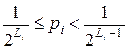 ,
, 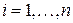 .
.
Пример. Пусть дан алфавит A={ a1, a2, a3, a4, a5, a6 } с вероятностями p1 =0.36, p2 =0.18, p3 =0.18, p4 =0.12, p5 =0.09, p6 =0.07. Построенный код приведен в таблице.
Таблица 11 Код Шеннона
| ai | Pi | Qi | Li | кодовое слово |
| a1 a2 a3 a4 a5 a6 | 1/22≤0.36<1/2 1/23≤0.18<1/22 1/23≤0.18<1/22 1/24≤0.12<1/23 1/24≤0.09<1/23 1/24≤0.07<1/23 | 0.36 0.54 0.72 0.84 0.93 |
Построенный код является префиксным. Вычислим среднюю длину кодового слова и сравним ее с энтропией. Значение энтропии вычислено при построении кода Хаффмена (H = 2.37).
Lср = 0.36 . 2+(0.18+0.18) . 3+(0.12+0.09+0.07) . 4=2.92< 2.37+1