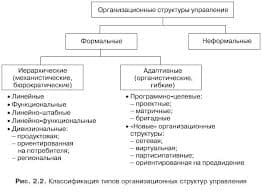
2015-02-24
2015-02-24 983
983
|
 >•Откройте табличный процессор Microsoft Excel. Щелкните мышью на ярлыке Лист2 (Sheet2), чтобы перейти на другой рабочий лист.
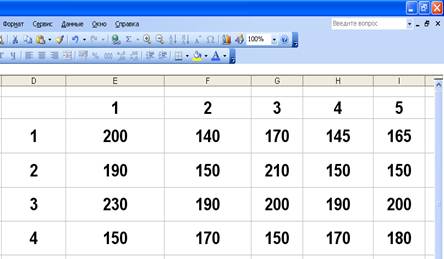
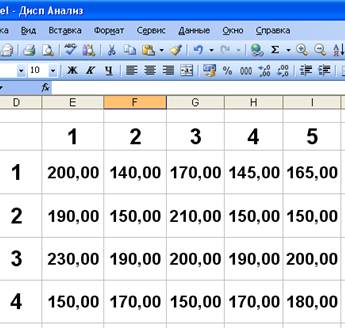
>•Откройте табличный процессор Microsoft Excel. Щелкните мышью на ярлыке Лист2 (Sheet2), чтобы перейти на другой рабочий лист. >• Введите данные для дисперсионного анализа, изображенные на рис.1.
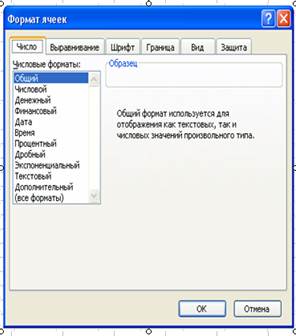
>•Преобразуйте данные в числовой формат. Для этого выберите команду меню Формат • Ячейки. На экранe появится окно формат ячеек (Рис.2). Выберите Числовой формат и введенные данные преобразуются к виду, показанному на рис. 3
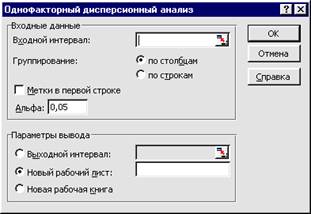
>•Выберите команду меню Сервис • Анализ данных (Тоо1s * Dаtа Апа1уsis). На экранe появится окно Анализ данных (Dаtа Апа1уsis) (Рис.4).
>• Щелкните мышью на строке Однофакторный дисперсионный анализ (Аnоvа: Single Factor) в списке Инструменты анализа (Апа1уsis Тоо1s).
>• Нажмите кнопку ОК, чтобы закрыть окно Анализ данных (Dаtа Апа1уsis). На экране появится окно Однофакторный дисперсионный анализ для проведения дисперсионного анализа данных (Рис.5).
|
|
>• Щелкните мышью в поле Входной интервал. Выделите диапазон ячеек E3::I6, данные в котором нужно проанализировать. В поле Входной интервал (Input Range) группы элементов управления Входные данные, (Input) появится указанный диапазон.
|

|
>• Установите флажок Метки в первой строке (Labels in Firts Rom) в группе элементов управления Входные данные (Input), если первый столбец выделенного диапазона данных содержит названия строк.
>• В поле ввода Альфа (А1рhа) группы элементов управления Входные данные по умолчанию отображается величина 0,05, которая связана с вероятностью возникновения ошибки в дисперсионном анализе.
>• Если в группе элементов управления Параметры вывода (Input options) не установлен переключатель Новый рабочий лист (Nev Worksheet Ply), то установите его, чтобы результаты дисперсионного анализа были помещены на новый рабочий лист
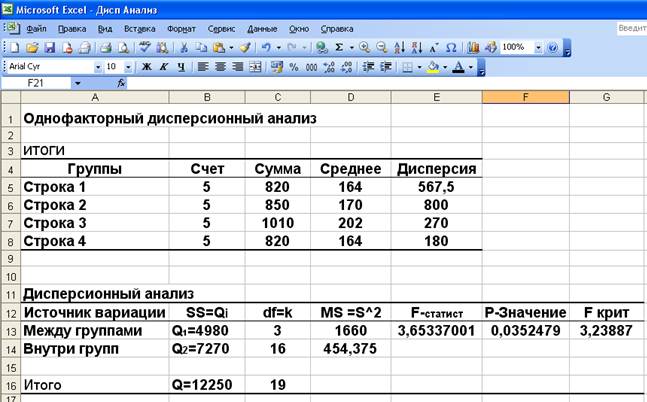
> Нажмите кнопку ОК, чтобы закрыть окно Однофакторный дисперсионный анализ (Аnоvа: Single Factor). На новом рабочем листе появятся результаты дисперсионного анализа (Рис. 6).
 |
| Рис.6 |
В диапазоне ячеек А4:Е6 расположены результаты описательной статистики. В строке 4 находятся названия параметров, в строках 5 - 8 - статистические значения, вычисленные по партиям.
В столбце Счет (Соunt) расположены количества измерений, в столбце Сумма - суммы величин, в столбце Среднее (Аvегаgе) - средние арифметические значения, в столбце Дисперсия (Vаriаnсе) - дисперсии.
Полученные результаты показывают, что наибольшая средняя разрывная нагрузка в партии №3, а наибольшая дисперсия разрывной нагрузки –в партии №1.
В диапазоне ячеек А11:G16 отображается информация, касающаяся существенности расхождений между группами данных. В строке 12 находятся названия параметров дисперсионного анализа, в строке 13 - результаты межгрупповой обработки, в строке 14 - результаты внутригрупповой обработки, а в строке 16 – суммы значений упоминавшихся двух строк.
В столбце SS (Qi) расположены величины варьирования, т.е. суммы квадратов по всем отклонениям. Варьирование, как и дисперсия, характеризует разброс данных. По таблице можно заметить, что межгрупповой разброс разрывной нагрузки существенно выше величины внутригруппового варьирования.
В столбце df (k) находятся значения чисел степеней свободы. Данные числа указывают на количество независимых отклонений, по которым будет вычисляться дисперсия. Например, межгрупповое число степеней свободы равняется разности количеству групп данных и единицы. Чем больше число степеней свободы, тем выше надежность дисперсионных параметров. Данные степеней свобод в таблице показывают, что для внутригрупповых результатов надежность выше, чем для межгрупповых параметров.
В столбце MS (S2) расположены величины дисперсии, которые определяются отношением варьирования и числа степеней свобод. Дисперсия характеризует степень разброса данных, но в отличие от величины варьирования, не имеет прямой тенденции увеличиваться с ростом числа степеней свобод. Из таблицы видно, что межгрупповая дисперсия значительно больше внутригрупповой дисперсии.
В столбце F находится, значение F-статистики, вычисляемое отношением межгрупповой и внутригрупповой дисперсий.
В столбце F критическое (F crit) расположено F-критическое значение, рассчитываемое по числу степеней свободы и величине Альфа (А1рhа). F-статистика и F-критическое значение используют критерий Фишера - Снедекора.
Если F-статистика больше F-критического значения, то можно утверждать, что различия между группами данных носят неслучайный характер. т.е. на уровне значимости α = 0,05 (с надежностью 0,95) нулевая гипотеза отвергается и принимается альтернативная: различие между партиями сырья оказывает существенное влияние на величину разрывной нагрузки.
В столбце Р-значение (Р-value) находится значение вероятности того, что расхождение между группами случайно. Так как в таблице данная вероятность очень мала, то отклонение между группами носит неслучайный характер.