 2015-02-24
2015-02-24 830
830Рассмотрим использование функции Двухфакторный дисперсионный анализ без повторений (Anova: Two-Factor Without Replication) на следующем примере.
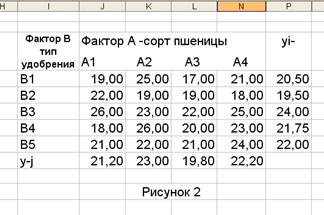
На рисунке. 2 представлены данные об урожайности (ц/га) четырех сортов пшеницы (четыре уровня фактора А), достигнутой при использовании пяти типов удобрений (пять уровней фактора В). Данные получены на 20 участках одинакового размера и аналогичного почвенного покрова. Необходимо определить, влияет ли сорт и тип удобрения на урожайность пшеницы.
Результаты двухфакторного дисперсионного анализа с помощью функции Двухфакторный дисперсионный анализ без повторений представлены на рисунке 3.
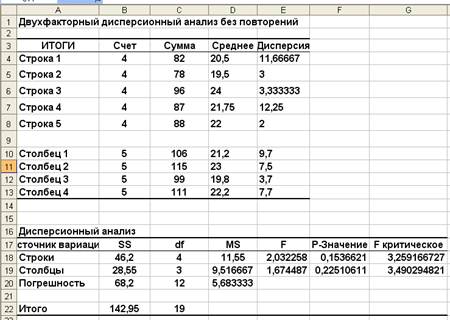 Как видно по результатам, расчетное значение величины F-статистики для фактора А (сорт пшеницы) FА=l,67, а критическая область образуется правосторонним интервалом (3,49; +∞). Так как FА=l,67 не попадает в критическую область, гипотезу НА: a1 = a2 + ••• = ak принимаем, т.е. считаем, что в этом эксперименте тип удобрения не оказал влияния на урожайность.
Как видно по результатам, расчетное значение величины F-статистики для фактора А (сорт пшеницы) FА=l,67, а критическая область образуется правосторонним интервалом (3,49; +∞). Так как FА=l,67 не попадает в критическую область, гипотезу НА: a1 = a2 + ••• = ak принимаем, т.е. считаем, что в этом эксперименте тип удобрения не оказал влияния на урожайность.
|
Так как FВ =2,03 не попадает в критическую область, гипотезу НВ: b1 = b2 =... = bm
также принимаем, т.е. считаем, что в данном эксперименте сорт пшеницы также не оказал влияния на урожайность.








