 2015-02-04
2015-02-04 484
484Одним из часто используемых методов эффективного кодирования является так называемый код Хаффмена.
Пусть сообщения входного алфавита 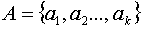 имеют соответственно вероятности их появления
имеют соответственно вероятности их появления 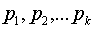 .
.
Тогда алгоритм кодирования Хаффмена состоит в следующем:
1. Сообщения располагаются в столбец в порядке убывания вероятности их появления.
2. Два самых маловероятных сообщения объединяем в одно сообщение 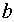 ,которое имеет вероятность, равную сумме вероятностей сообщений
,которое имеет вероятность, равную сумме вероятностей сообщений 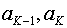 , т. е.
, т. е. 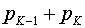 . В результате получим сообщения
. В результате получим сообщения 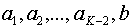 , вероятности которых
, вероятности которых 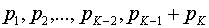 .
.
3. Повторяем шаги 1 и 2 до тех пор, пока не получим единственное сообщение, вероятность которого равна 1.
4. Проводя линии, объединяющие сообщения и образующие последовательные подмножества, получаем дерево, в котором отдельные сообщения являются концевыми узлами. Соответствующие им кодовые слова можно определить, приписывая правым ветвям объединения символ “1”, а левым - “0”. Впрочем, понятия “правые” и “левые” ветви в данном случае относительны.

На основании полученной таблицы можно построить кодовое дерево
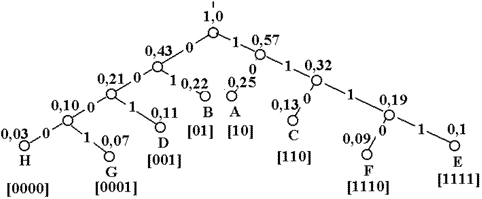
Так как в процессе кодирования сообщениям сопоставляются только концевые узлы, полученный код является префиксным и всегда однозначно декодируем.
При равномерных кодах одиночная ошибка в кодовой комбинации приводит к неправильному декодированию только этой комбинации. Одним из серьёзных недостатков префиксных кодов является появление трека ошибок, т.е. одиночная ошибка в кодовой комбинации, при определенных обстоятельствах, способна привести к неправильному декодированию не только данной, но и нескольких последующих кодовых комбинаций.








