2015-02-27
2015-02-27 1147
1147Двоичное дерево поиска представляет собой бинарное дерево, обладающее следующим свойством. Значение любого из узлов L 1, L 2, L 3, …, Ln левого поддерева, выходящего из некоторого корня K, всегда меньше значения самого этого корня: Value (Li) < Value (K), тогда как отношение узлов R 1, R 2, R 3, …, Rn правого поддерева к корню определяется нестрогим неравенством: Value (Ri) >= Value (K).
Ниже изображено двоичное дерево поиска (рис. 4.4). Из его корня, значение которого 10, выходят два поддерева, причем все левые элементы меньше правых и самого корня, а правые, соответственно, больше. Такое следование продолжается и на следующих уровнях, т. е. если, например, взять поддерево с корнем 16, то значения всех правых элементов будут больше или равны 16, а левых – меньше.
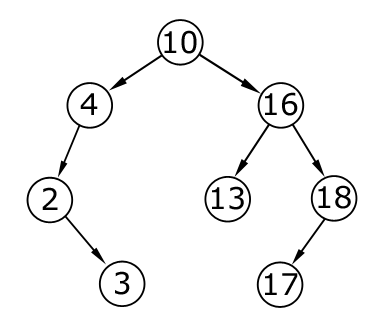
Рисунок 4.4 – Двоичное дерево поиска
Алгоритм поиска по такой структуре данных будет достаточно эффективен, ведь максимальное количество шагов, которое может понадобиться для обнаружения нужного элемента, равно количеству уровней самого бинарного дерева поиска. Поиск элемента в двоичном дереве состоит из следующих шагов:
1. если дерево не содержит в себе элементов, то остановить поиск;
2. иначе сравнить искомый элемент (ключ) с корнем:
· если значение ключа равно значению корня – поиск завершен;
· если значение ключа больше значения корня – искать в правой части;
· если значение ключа меньше значения корня – искать в левой части.
Эти действия выполняются до того момента, пока элемент не будет найден, либо окажется что он вовсе отсутствует.
Рассмотренный метод для изображенного на рисунке выше бинарного дерева поиска, будет работать по такому сценарию. Допустим, значение ключа равно 13, и нужно найти узел с тем же значением. Вначале сравнивается ключ с корнем, значение которого 10. Так как 13 больше 10, далее для поиска следует выбрать правую ветку дерева, поскольку элементы в ней больше 10, что известно из основного свойства бинарного дерева поиска. Далее поиск осуществляется в правом поддереве. Ключ 13 сравнивается с вершиной 16. Первое значение меньше, следовательно, поиск продолжается в левой части, и именно там расположен искомый элемент.
Помимо операции поиска, в рассматриваемую структуру данных эффективно добавлять элементы, а также извлекать их из нее. Во многих ситуациях целесообразным оказывается обычное двоичное дерево перестроить в дерево поиска, отсортировав его элементы одним из алгоритмов сортировки.
Куча
Имеется список целых чисел 5, 1, 7, 3, 9, 2, 8. Построим два дерева, в которых каждому узлу соответствует одно из значений этого списка, причем первое дерево будет организованно нисходящей иерархией, а второе – восходящей (рис. 4.5).
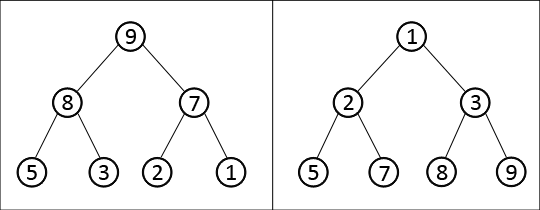
Рисунок 4.5 – Структура данных «Куча»
Когда корневой элемент кучи имеет наибольшее из возможных значений, то ее называют max-кучей, а когда наименьшее – min-кучей.
Два получившихся дерева полностью удовлетворяют свойству кучи: если n является узлом-предком относительно m, а m соответственно узлом-потомком узла n, то для max-кучи всегда выполняется неравенство n ≥ m, а для min-кучи n ≤ m.
Данные, представленные такой структурой, удобны в обработке; некоторые операции с ними оказываются весьма не ресурсоемкими, например, удаление минимального (для min-кучи) или максимального (для max-кучи) элемента, добавление нового элемента и др.
Чтобы лучше понять принципы функционирования такой структуры данных как куча, рассмотрим программу, в которой определяются максимальный и минимальный элементы кучи. В качестве примера будем использовать две кучи, изображенные на рисунке выше, а представим их в программе при помощи простого одномерного массива.
Пусть известно, с каким из видов дерева (min- или max-кучей) имеем дело. Тогда определить максимальный элемент max-кучи, и минимальный элемент min-кучи не составит труда, поскольку в обоих случаях это элемент под одним и тем же номером, а именно первый элемент массива. Составим программу на C++ для решения данной задачи:
const int n=7;
int i, j;
string T;
int s;
int min_heap[n]={1, 2, 3, 5, 7, 8, 9};
int max_heap[n]={9, 8, 7, 5, 3, 2, 1};
void Min()
{ cout<<"Корень min-кучи: "<<min_heap[0]; }
void Max()
{ cout<<"Корень max-кучи: "<<max_heap[0]; }
void main ()
{
cout<<"min-heap или max-heap? > ";
cin>>T;
if (T=="min-heap") Min();
else if (T=="max-heap") Max();
else cout<<"Ошибка!";
}
Столкнуться со структурами данных типа кучи в программировании можно не раз. Так, например, их используют для оптимизации некоторых алгоритмов, многие популярные языки оперируют ими. Кроме того существуют различные варианты этой структуры, каждый из которых характерен своими специфическими свойствами.