 2015-02-18
2015-02-18 1846
1846Этот алгоритм в целом похож на алгоритм для грамматик простого предшествования, рассмотренный выше. Он также выполняется расширенным МП-автоматом и имеет те же условия завершения и обнаружения ошибок. Основное отличие состоит в том, что при определении отношения предшествования этот алгоритм не принимает во внимание находящиеся в стеке нетерминальные символы и при сравнении ищет ближайший к верхушке стека терминальный символ. Однако после выполнения сравнения и определения границ основы при поиске правила в грамматике нетерминальные символы следует, безусловно, принимать во внимание.
Алгоритм состоит из следующих шагов.
Шаг 1. Поместить в верхушку стека символ 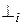 , считывающую головку — в начало входной цепочки символов.
, считывающую головку — в начало входной цепочки символов.
Шаг 2. Сравнить с помощью отношения предшествования терминальный символ, ближайший к вершине стека (левый символ отношения), с текущим символом входной цепочки, обозреваемым считывающей головкой (правый символ отношения). При этом из стека надо выбрать самый верхний терминальный символ, игнорируя все возможные нетерминальные символы.
Шаг 3. Если имеет место отношение <· или = ×, то произвести сдвиг (перенос тощего символа из входной цепочки в стек и сдвиг считывающей головки на один шаг вправо) и вернуться к шагу 2. Иначе перейти к шагу 4.
Шаг 4. Если имеет место отношение ·>, то произвести свертку. Для этого надо найти на вершине стека все терминальные символы, связанные отношение («основу»), а также все соседствующие с ними нетерминальные символы (при определении отношения нетерминальные символы игнорируются). Если терминальных символов, связанных отношением = ×, на верхушке стека нет, то в качестве основы используется один, самый верхний в стеке терминальный символ стека. Все (и терминальные, и нетерминальные) символы, составляющие основу надо удалить из стека, а затем выбрать из грамматики правило, имеющее правую часть, совпадающую с основой, и поместить в стек левую часть выбранного правила. Если правило, совпадающее с основой, найти не удалось, то необходимо прервать выполнение алгоритма и сообщить об ошибке, иначе, если разбор не закончен, то вернуться к шагу 2.
Шаг 5. Если не установлено ни одно отношение предшествования между текущим символом входной цепочки и самым верхним терминальным символом в стеке, то надо прервать выполнение алгоритма и сообщить об ошибке.
Конечная конфигурация данного МП-автомата совпадает с конфигурацией при распознавании цепочек грамматик простого предшествования.
Пример
Дано: G ({(,), ^, &, ~, a }, { S, T, E, F }, P, S), где
P: S → S ^ T | T
T → T & E | E
E →~ E | F
F → (E) | a
Построить: распознаватель для G.
Таблица 3.10 - Построение множеств L (A) и R (A)
| i | Li (A) | Ri (A) |
| L 0(S)={ S, T } L 0(T)={ T, E } L 0(E)={~, F } L 0(F)={(, a } | R 0(S)={ T } R 0(T)={ E } R 0(E)={ E, F } R 0(F)={), a } | |
| L 1(S)={ S, T, E } L 1(T)={ T, E, ~, F } L 1(E)={~, F, (, a } L 1(F)={(, a } | R 1(S)={ T, E } R 1(T)={ E, F } R 1(E)={ E, F,), a } R 1(F)={), a } | |
| L 2(S)={ S, T, E, ~, F, (, a } L 2(T)={ T, E, ~, F, (, a } L 2(E)={~, F, (, a } L 2(F)={(, a } | R 2(S)={ T, E, F,), a } R 2(T)={ E, F,) a } R 2(E)={ E, F,), a } R 2(F)={), a } | |
| L 3(S)={ S, T, E, ~, F, (, a } L 3(T)={ T, E, ~, F, (, a } L 3(E)={~, F, (, a } L 3(F)={(, a } | R 3(S)={ T, E, F,), a } R 3(T)={ E, F,) a } R 3(E)={ E, F,), a } R 3(F)={), a } |
Таблица 3.11 - Построение множеств Lt (A) и Rt (A)
| i | Lt (A) | Rt (A) |
| Lt 0(S)={ ^ } Lt 0(T)={ & } Lt 0(E)={ ~ } Lt 0(F)={(, a } | Rt 0(S)={^} Rt 0(T)={&} Rt 0(E)={~} Rt0 (F) = {), a} | |
| Lt 1(S)={^, &, ~, (, a } Lt 1(T)={&, ~, (, a } Lt 1(E)={~, (, a } Lt 1(F)={(, a } | Rt 1(S)={^, &, ~,), a } Rt 1(T)={&, ~,), a } Rt 1(E)={~,), a } Rt 1(F)={), a } | |
| Lt 2(S)={^, &, ~, (, a } Lt 2(T)={&, ~, (, a } Lt 2(E)={~, (, a } Lt 2(F)={(, a } | Rt 2(S)={^, &, ~,), a } Rt 2(T)={&, ~,), a } Rt 2(E)={~,), a } Rt 2(F)={), a } |
Таблица 3.12 - Матрица операторного предшествования символов грамматики
| Символы | ^ | & | ~ | ( | ) | а | 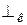 |
| ^ | ·> | <· | <· | <· | ·> | <· | ·> |
| & | ·> | ·> | <· | <· | ·> | <· | ·> |
| ~ | ·> | ·> | <· | <· | ·> | <· | ·> |
| ( | <· | <· | <· | <· | =× | <· | |
| ) | ·> | ·> | ·> | ·> | |||
| а | ·> | ·> | ·> | ·> | |||
| | <· | <· | <· | <· | <· |
Для ^ находящейся в правиле вывода слева от нетерминала Т, во множество Lt (Т) входят символы &, ~, (, a, значит в строке матрицы для ^ ставим знак меньшего предшествования в позициях этих символов. С другой стороны этот символ ^ находится справа от S. Во множество Rt (S) входят символы ^, &, ~,), a, значит знак большего предшествования ставится в столбце для ^ в позициях этих символов. Символы (и) в правиле вывода находятся радом, поэтому в позиции этих символов ставится знак равного предшествования (игнорируя нетерминал Е).








