 2015-02-04
2015-02-04 1668
1668В традиционных кодировках для кодирования одного символа используется 8 бит. Легко подсчитать, что такой 8-разрядный код позволяет закодировать 256 различных символов.
В качестве международного стандарта принята кодовая таблица ASCII (American Standard Code for Information Interchange), кодирующая первую половину символов с числовыми кодами от 0 до 127(рис. 1).
Национальные стандарты кодировочных таблиц включают первую, международную часть кодовой таблицы без изменений, а во второй половине содержат коды национальных алфавитов, символы псевдографики и некоторые математические знаки. В настоящее время существуют пять различных кодировок кириллицы: КОИ-8-Р (рис. 2), Windows, MS-DOS, Macintosh и ISO, что вызывает трудности при работе с русскоязычными документами.
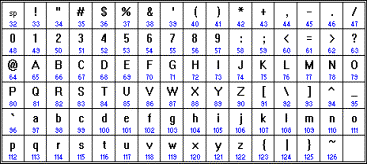
| Рис. 1. Международная кодировка ASCII |
Хронологически одним из первых стандартов кодирования русских букв на компьютерах был КОИ–8 (Код обмена информацией, 8-битный). Эта кодировка применялась еще в 70-е гг. XX в. на компьютерах серии ЕС ЭВМ, а с середины 80-х стала использоваться в первых русифицированных версиях операционной системы UNIX.
Наиболее распространенной в настоящее время является кодировка Microsoft Windows, обозначаемая сокращением CP1251 (CP означает Code Page – кодовая страница) (рис. 3).
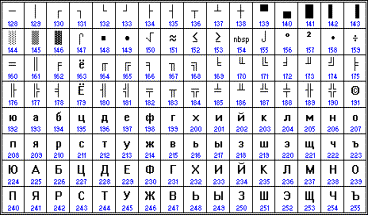
| Рис. 2. Кодировка КОИ 8-Р |
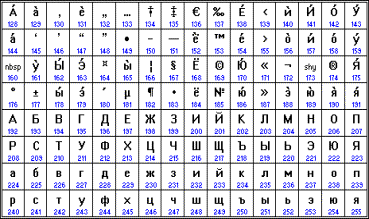
Рис. 3. Кодировка CP1251
От начала 90-х годов, времени господства операционной системы MS DOS, остается кодировка CP866. Компьютеры фирмы Apple, работающие под управлением операционной системы Mac OS, используют свою собственную кодировку Mac. Кроме того, Международная организация по стандартизации (International Standards Organization, ISO) утвердила в качестве стандарта для русского языка еще одну кодировку под названием ISO 8859-5.








