2015-03-22
2015-03-22 2442
2442Содержание
Введение 4
| 1. | Цель работы | |
| 2. | Теоретическая часть | |
| 3. | Задание к лабораторной работе | |
| 4. | Порядок выполнения работы | |
| 5. | Варианты заданий | |
| 6. | Требования к оформлению отчета | |
| 7. | Контрольные вопросы | |
| Список литературы | ||
ЛАБОРАТОРНАЯ РАБОТА
ИЗУЧЕНИЕ МЕТОДОВ ИНТЕЛЛЕКТУАЛЬНОГО АНАЛИЗА ДАННЫХ В СРЕДЕ STATGRAPHICS:
КОМПОНЕНТНЫЙ АНАЛИЗ, КЛАСТЕРНЫЙ АНАЛИЗ
Введение
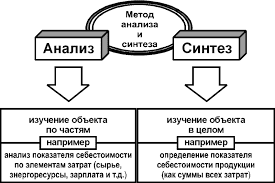
Интеллектуальный анализ данных, или Data Mining, – это процесс обнаружения в сырых данных ранее неизвестных, нетривиальных, практически полезных и доступных для интерпретации знаний, необходимых для принятия решений в различных сферах человеческой деятельности [1,2].
Основной целью современных технологий Data Mining (discovery-driven data mining) является автоматический поиск в больших по объему многомерных данных некоторых шаблонов (паттернов), характерных для каких-либо фрагментов неоднородных многомерных данных. К основным задачам Data Mining относятся задачи: классификации, регрессии, поиска ассоциативных правил, кластеризации.
Основные методы Data Mining подразделяются на несколько групп. Первую группу составляют базовые методы, к которым относятся алгоритмы, основанные на переборе. Во вторую группу включаются статистические методы, такие как регрессионный, дискриминантный, факторный, компонентный, кластерный и другие виды статистического анализа. И, наконец, к третьей группе относятся интеллектуальные методы: нечеткая логика, генетические алгоритмы, нейронные сети.
Изучению особенностей применения компонентного и кластерного анализов в среде StatGraphics для решения задач Data Mining посвящена данная лабораторная работа.
Цель работы
Целью работы является изучение особенностей выполнения компонентного и кластерного анализа в среде StatGraphics и применения полученных результатов для исследования структуры данных и извлечения знаний.
Теоретическая часть
2.1. Основные типы извлекаемых закономерностей
Выделяют пять стандартных типов закономерностей (задач), которые позволяют выявлять методы Data Mining: ассоциация, последовательность, классификация, кластеризация, прогнозирование.
Закономерность типа «а ссоциация» наблюдается в данных, когда несколько событий связаны друг с другом и происходят при этом одновременно. Например, исследование, проведенное в супермаркете, может показать, что 65% купивших кукурузные чипсы берут также и «кока-колу», а при наличии скидки за такой комплект «колу» приобретают в 85% случаев. Располагая сведениями о подобной ассоциации, менеджерам легко оценить, насколько действенна предоставляемая скидка.
Закономерность типа «последовательность» предполагает наличие в данных цепочки связанных друг с другом и распределенных во времени событий. Так, например, после покупки дома в 45% случаев в течение месяца приобретается и новая кухонная плита, а в пределах двух недель 60% новоселов обзаводятся холодильником.
Закономерность типа «классификация» выявляется в данных на основе анализа признаков уже классифицированных объектов, при этом известна принадлежность объектов к классам. Результатом является формирование правил отнесения объектов к классам.
Закономерность типа «кластеризация» предполагает наличие в данных сходых по каким-либо признакам групп объектов, причем количество групп и принадлежность объектов к ним заранее не заданы. С помощью кластеризации средства Data Mining самостоятельно выделяют различные однородные группы данных.
Поиск закономерности типа «прогнозирование» проводится на основе информации, хранящейся в базе данных в виде временных рядов. Если удается построить математическую модель и найти шаблоны, адекватно отражающие эту динамику, есть вероятность, что с их помощью можно предсказать и поведение системы в будущем.
2.2. Метод главных компонент
Метод главных компонент относится к группе методов визуализации данных.
Методы визуализации данных являются методами анализа данных без учителя и имеют целью выявление структуры данных на основе выяснения взаимоотношений между объектами и их признаками. Результатом применения этих методов является визуальное представление о структуре данных.
Визуализация данных - это процесс получения тем или иным способом графического отображения множества объектов в новое координатное пространство, которое может быть либо трехмерным, либо двухмерным (плоскостью), либо одномерным (числовой осью). При этом построенное отображение в новом координатном пространстве должно максимально отражать особенности распределения этих объектов в исходном многомерном пространстве.
При использовании двух- и трехмерного представления информации пользователь имеет возможность увидеть следующие закономерности набора данных:
- его кластерную структуру;
- топологические особенности;
- наличие трендов;
- существование других зависимостей, присущих исследуемому набору данных.
Методы визуализации данных включают в себя следующие четыре группы методов: линейные методы снижения размерности, нелинейные отображения, многомерное шкалирование и заполняющие пространство кривые.
Линейные методы снижения размерности позволяют визуализировать многомерные данные путем построения нового координатного пространства, в котором каждая координатная ось является линейной комбинацией исходных признаков.
Эти линейные комбинации признаков (оси) соответствуют так называемым латентным (скрытым) признакам, которые присутствуют в данных. Латентные признаки возникают в результате взаимодействия (корреляции) исходных элементарных признаков, и это означает, что в данных присутствуют некоторые скрытые закономерности. Таким образом, латентные признаки являются обобщением элементарных признаков и представляют собой интегрированные характеристики данных или признаки более высокого порядка.
Представление этих интегрированных характеристик в виде линейных комбинаций хорошо интерпретируется – коэффициенты в уравнениях координатных осей трактуются, например, как веса или вклады признаков в формирование интегрированных характеристик.
Отметим, что признаки, имеющие наибольшие весовые коэффициенты по модулю, обнаруживают наибольшую изменчивость (т. е. разброс, дисперсию) при переходе от одного объекта к другому. Именно такие признаки отражают наиболее существенные свойства исследуемых объектов и главным образом интересуют исследователя во многих практических задачах.
Таким образом, линейные методы снижения размерности наряду с решением задачи визуализации позволяют решить еще две задачи:
- задачу сжатия данных (редукции данных), если количество новых координатных осей больше трех, и визуализация невозможна;
- задачу классификации исходных признаков, то есть определения взаимосвязей между признаками путем объединения значимых признаков в группы и формирования новых интегральных признаков.
Наиболее распространенным линейным методом снижения размерности является метод главных компонент.
Метод главных компонент позволяет на основе анализа n объектов, каждый из которых характеризуется р исходными признаками х1,..., хp , построить р главных компонент F1,F2,…,Fn (координатных осей нового пространства), причем новая система координат является системой ортонормированных линейных комбинаций. Каждая i -ая координатная ось является линейной комбинацией исходных признаков и записывается в виде:
F1=ω11(x1-m1)+ ω21(x2-m2)+…+ ωp1(xp-mp),
где ωij – весовой коэффициент, определяющий вклад i- ого признака в формирование j -ой компоненты, mi – математическое ожидание i- ого признака.
Алгоритм построения главных компонент (ГК) с геометрических позиций состоит в следующем.
1 шаг. Производится центрирование исходных данных (рис.1а); начало координат переносится в центр распределения данных (центроид), являющийся центром эллипсоида рассеивания объектов (случайного вектора-строки Х) (рис.1б).
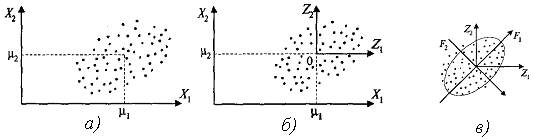
Рис. 1. Геометрическая интерпретация процедуры формирования главных компонент
2 шаг. Строятся главные компоненты F1, F2,…,Fp (рис.1в). Линейные комбинации выбираются таким образом, что среди всех возможных линейных ортонормированных комбинаций исходных признаков первая главная компонента F1(X) обладает наибольшей дисперсией. Графически это выглядит как ориентация новой координатной оси F1 вдоль направления наибольшей вытянутости эллипсоида рассеивания объектов в исходном пространстве p признаков.
Вторая главная компонента F2(X) перпендикулярна первой и строится исходя из предположений нахождения максимальной дисперсии среди всех оставшихся линейных комбинаций, не коррелированных с первой ГК. При этом разброс наблюдений вдоль новой оси F1 для исследователя наиболее важен, менее важен разброс вдоль оси F2. Графически это интерпретируется направлением наибольшей вытянутости эллипсоида рассеивания, который перпендикулярен первой главной компоненте.
Следующие главные компоненты определяются по аналогичной схеме. Количество главных компонент равно количеству исходных элементарных признаков.
Главные компоненты вычисляются по убыванию дисперсии и в сумме объясняют 100% дисперсии элементарных признаков; процент объясняемой дисперсии для любой ГК рассчитывается на основании собственных значений.
3 шаг. Выбор значащих главных компонент.
Выбор значащих главных компонент основывается на различных критериях. Примером является графический критерий «Каменистая осыпь» (Кеттель, 1966), согласно которому строится система координат: по оси OX – главные компоненты, по оси OY – собственные значения. На графике находится точка, в которой убывание собственных значений максимально замедляется. Согласно графику оставляем 2-3 главные компоненты.
4 шаг. Определение названия для значащих главных компонент
Для определения названия значащих главных компонент необходимо для любой одной главной компоненты Fj расположить все множество значений весовых коэффициентов Wi на числовой оси и условно разбить его на два подмножества: подмножество незначимых весовых коэффициентов W1 и подмножество значимых весовых коэффициентов W2.
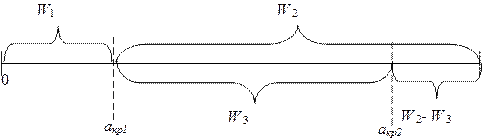
Рис.2. Разбиение множества весовых коэффициентов на подмножества
Далее в подмножестве значимых весовых коэффициентов W2 необходимо выделить еще два подмножества:
W3 – подмножество значимых весовых коэффициентов, не участвующих в названии ГК;
W2 – W3 – подмножество значимых весовых коэффициентов, участвующих в формировании названия.
Дополнительное выделение подмножества W3 вызвано стремлением к более простой структуре главных компонент, что всегда легко поддается интерпретации. Оценка значимости выбранных коэффициентов производится с помощью коэффициента информативности: 
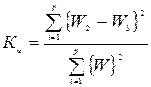 .
.
Рекомендуемое значение коэффициента Ки=0,75-0,95.
Пример. Имеются значения показателей производственно-хозяйственной деятельности предприятий машиностроения: x1 – уровень выработки на одного среднегодового работника; x2 – уровень фондоотдачи; x3 –размер оборотных производственных средств; x4 — размер затрат на выпуск единицы товарной продукции; x5 – численность промышленно-производственного персонала; x6 – рентабельность продукции; x7 – уровень энерговооруженности труда;
Вычислены весовые коэффициенты для первой главной компоненты: w11 =0.9, w21 =0.8, w31 =0.1, w41 =0.8, w51 =0.3, w61 =0.7, w71 =0.2.
На основе предварительной оценки выделим для первой главной компоненты F1 следующие подмножества весовых коэффициентов:
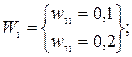
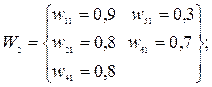
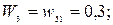
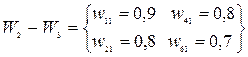
Значение коэффициента информативности дает основания утверждать, что состав подмножества ω2- ω3 для главной компоненты F1 достаточно надежен:
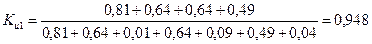 ,
,
т.е. значениями признаков X1, Х2, Х4, Х6 состав главной компоненты F1 определяется более чем на 94%. Для первой главнойкомпоненты F1 формируется название «Эффективность производства».
отметим, что, если значение коэффициента информативности меньше нижней границы допустимого интервала, то необходимо ввести еще один коэффициент в подмножество W2 – W3 из подмножества W3.
К д остоинствам метода главных компонент следует отнести:
1) наименьшее искажение структуры исходных объектов при их проецировании в пространство меньшей размерности;
2) возможность применения для анализа данных в сочетании с другими методами исследования данных, например в корреляционно-регрессионном анализе.
Недостатком метода главных компонент является возможность возникновения ситуации, когда весовые коэффициенты имеют близкие по величине значения. В этом случае результат слабо интерпретируем. Эта проблема решается применением других видов анализа, например факторного анализа, а также добавлением или исключением переменных из анализа.
2.3. Кластерный анализ
Кластерный анализ предназначен для разбиения множества объектов на заранее неизвестное или в редких случаях заданное количество групп (кластеров) на основании некоторого математического критерия кластеризации
Постановка задачи кластеризации.
Дано: множество n объектов, характеризуемых m признаками. (то есть дана матрица признаков Х [ n x m ], где xij – значения признака j для объекта i).
Необходимо: выполнить разбиение заданного множества объектов на заранее неизвестное или в редких случаях заданное количество групп (кластеров) на основании некоторого математического критерия качества кластеризации.
В переводе с английского claster - гроздь, пучок, скопление, группа элементов, характеризуемых каким-либо общим свойством.
Критерий качества кластеризации в той или иной мере отражает следующие неформальные требования:
1) внутри групп объекты должны быть тесно связаны между собой;
2) объекты разных групп должны быть далеки друг от друга;
3) при прочих равных условиях распределения объектов по группам должны быть равномерными.
Требования пунктов 1) и 2) выражают стандартную концепцию компактности классов разбиения; требование пункта 3) состоит в том, чтобы критерий не навязывал объединения отдельных групп объектов [3,4].
Задачи, решаемыеметодами кластерного анализа:
1) проведение классификации объектов с учетом множества признаков;
2) проверка выдвигаемых предположений о наличии некоторой структуры в изучаемом множестве объектов;
3) построение новых классификаций для слабо изученных явлений, то есть поиск в изучаемом множестве заранее неизвестной структуры.
Результаты кластерного анализа (полученного разбиения на кластеры) зависят от вариантов решения следующих трех проблем:
– выбора меры сходства (метрики) для
а) определения расстояния между объектами;
б) объединения двух кластеров;
– выбора критериев качества кластеризации;
– выбора алгоритмов кластеризации.
Меры сходства (метрики) для определения расстояния между объектами
Способов определения меры расстояния между объектами существует несколько:
1) наиболее распространенный способ - евклидово расстояние: 
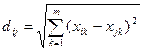 - где
- где 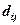 – расстояние между i -м и j -м объектами; xil, xjl – значения l -го признака соответственно i -го и j -го объектов; ωk – вес, приписываемый k -му признаку.
– расстояние между i -м и j -м объектами; xil, xjl – значения l -го признака соответственно i -го и j -го объектов; ωk – вес, приписываемый k -му признаку.
2) взвешенное евклидово расстояние: 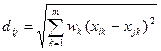 ;
;
3) манхэттенское расстояние (расстояние городских кварталов), также называемое «хэмминговым» или расстоянием city-block: 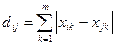 – для этой меры влияние отдельных выбросов меньше, чем при использовании евклидова расстояния, поскольку здесь координаты не возводятся в квадрат.
– для этой меры влияние отдельных выбросов меньше, чем при использовании евклидова расстояния, поскольку здесь координаты не возводятся в квадрат.
Меры сходства для объединения двух кластеров
Пусть Sl, Sm – l-я и m-я группы (классы, кластеры) объектов, Nl – число объектов, образующих группу, а ρ(Sl, Sm) – расстояние между группами Sl и Sm.
Наиболее распространенными мерами сходства для объединения двух кластеров S, и S2 являются [2]:
1) метод «ближайшего соседа» - расстояние между двумя кластерами определяется расстоянием между двумя наиболее близкими объектами (ближайшими соседями) в различных кластерах;
2) метод центров тяжести - в качестве расстояния между двумя кластерами берется расстояние между центральными точками кластеров;
3) метод «дальнего соседа» - расстояние между кластерами определяются наибольшим расстоянием между любыми двумя объектами в различных кластерах
Обобщенный алгоритм кластерного анализа
Алгоритмы кластерного анализа отличаются большим разнообразием. Это могут быть, например, алгоритмы, реализующие полный перебор сочетаний объектов или осуществляющие случайные разбиения множества объектов. Как правило, все они представляют собой итеративные алгоритмы дробления исходной совокупности. В процессе деления новые кластеры формируются до тех пор, пока не будет выполнено правило остановки. Большинство таких алгоритмов состоит из двух этапов.
Этап 1. Задается начальное (искусственное или произвольное) разбиение на кластеры и определяется некоторый математический критерий качества автоматической классификации.
Этап 2. Объекты переносятся из кластера в кластер до тех пор, пока значение критерия качества не перестанет улучшаться. При этом возможен либо полный перебор вариантов, либо сокращенный на основании каких-либо эвристик.
Многообразие алгоритмов кластерного анализа обусловлено множеством различных критериев, отражающих те или иные аспекты качества автоматического группирования.
Критерии качества автоматического группирования
Наиболее часто применяемые критерии качества кластеризации перечислены ниже.
1. Сумма квадратов расстояний до центров классов:
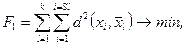
где l – номер кластера, l=1,k; xi – вектор признаков i -го объекта в l -м кластере; 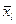 - центр l-го кластера; Sl – количество объектов в l -м кластере.
- центр l-го кластера; Sl – количество объектов в l -м кластере.
2. Сумма внутриклассовых расстояний между объектами:
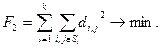
Здесь получаются кластеры большой плотности (населенности)
3. Суммарная внутриклассовая дисперсия:
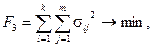
где  – дисперсия j -й переменной в кластере Sl.
– дисперсия j -й переменной в кластере Sl.
Алгоритмы иерархического группирования.
Иерархические методы кластерного анализа предназначены для получения наглядного представления о стратификационной структуре всей исследуемой совокупности объектов; они используются при небольших объемах наборов данных и различаются правилами построения кластеров. В качестве правил выступают критерии, которые используются при решении вопроса о «схожести» объектов при их объединении в группу (агломеративные методы), либо разделения на группы (дивизимные методы).
Агломеративные (объединяющие) методы построены на основе последовательного объединения объектов в группы и соответствующим уменьшением числа кластеров. В начале работы алгоритма все объекты являются отдельными кластерами. На первом шаге наиболее похожие объекты объединяются в кластер. На последующих шагах объединение продолжается до тех пор, пока все объекты не будут составлять один кластер.
Дивизимные (разделяющие) методы построены на основе расчленения группы на отдельные объекты. Эти методы являются логической противоположностью агломеративным методам. В начале работы алгоритма все объекты принадлежат одному кластеру, который на последующих шагах делится на меньшие кластеры, в результате образуется множество кластеров, каждый из которых состоит из одного объекта.
Результатом иерархических методов кластеризации является дендрограмма - древовидная диаграмма, содержащая n уровней, каждый из которых соответствует одному из шагов процесса последовательного укрупнения кластеров. Дендрограмма в графическом виде представляет последовательность объединения (разделения) кластеров и описывает близость отдельных точек и кластеров друг к другу.
Существует много способов построения дендограмм. В дендограмме объекты могут располагаться вертикально или горизонтально. Пример вертикальной дендрограммы, построенной агломеративным методом, приведен на рис. 3.
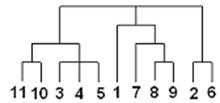
Рис. 3. Пример вертикальной дендрограммы,
построенной агломеративным методом
По горизонтали расположены объекты с номерами 11, 10, 3 и т.д. На первом шаге каждое наблюдение представляет один кластер (вертикальная линия), на втором шаге наблюдаем объединение таких объектов: 11 и 10; 3, 4 и 5; 8 и 9; 2 и 6. На втором шаге продолжается объединение в кластеры: объекты 11, 10, 3, 4, 5 и 7, 8, 9. Данный процесс продолжается до тех пор, пока все наблюдения не объединятся в один кластер.
Различные варианты определения расстояния между кластерами дают различные варианты иерархических процедур. Учитывая их специфику, для задания расстояния между кластерами оказывается достаточным указать порядок пересчета расстояний между кластером k и кластером (i, j), являющимся объединением двух других кластеров i и j по расстояниям dki, dkj и dij. Для этого используется формула
dki = aidki + aj×dkj + bdij+c|dki-dkj|,
где ai, aj, b, c – параметры, которыми определяется тот или иной вид расстояния между кластерами. Например, при ai = aj =1/2, b =0, c=-1/2 приходим к расстоянию, измеряемому по принципу ближайших соседей; ai = aj =1/2, b =0, c=1/2 дает расстояние, измеряемое по принципу дальнего соседа и т.д.
Наиболее распространенными агломеративными алгоритмами являются: метод одиночной связи, метод полной связи, метод средней связи, метод Варда [2,3].
В отличие от оптимизационных кластерных алгоритмов, предоставляющих исследователю конечный результат группирования объектов, иерархические процедуры позволяют проследить процесс выделения кластеров, образующихся на разных шагах агломеративного или дивизимного алгоритмы. Это стимулирует воображение исследователя и помогает ему привлекать для оценки структуры данных дополнительные формальные и неформальные представления.
Необходимо отметить, что при большом количестве наблюдений иерархические методы кластерного анализа не пригодны.