 2015-03-22
2015-03-22 1510
15104.1. Для проведения компонентного анализа в качестве примера необходимо выполнить следующие действия.
4.1.1. Открыть файл «Tabl.2.7_исх_комп.xls» с данными о состоянии рынка автомобилей. В файле приводятся выборочные сведения о фирме-изготовителе (manufacturer), названии модели (automobile model), а также параметры автомобиля: вес (weight), число цилиндров (cylinders), ускорение (accel), объем двигателя (displace) и мощность (horspower).
4.1.2. Запустить STATGRAPHICS. Подготовить данные для анализа. Для этого скопировать данные из файла «Tabl.2.7_исх_комп.xls», вставить их в электронную таблицу STATGRAPHICS. Каждому столбцу с данными присвоить уникальное имя. Для этого необходимо дважды щелкнуть левой клавишей мыши на заголовок поля, появится окно «Modify Column». В этом окне в поле «Name» ввести имя поля и указать тип поля. Заметим, что поля, участвующие в анализе, должны иметь тип поля «Numeric».
4.1.3. Выполнить построение главных компонент.
Для этого вызвать пункты из главного меню Special, Multivariate Methods, Principal Components. В появившемся окне диалога «Principal Components» задать переменные, которые должны учасвовать в анализе. Для этого надо выделить признаки accel, cylinders, displace, horspower, weight и нажать на стрелку «Data» (рис.4). Нажать кнопку «ОК».
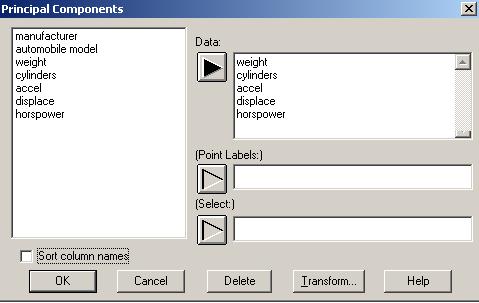
Рис.4. Окно диалога для задания анализируемых переменных при выполнении компонентного анализа
4.1.4. Просмотреть сводку результатов анализа данных методом главных компонент.
Сводка результатов анализа методом главных компонент, приведена на рисунке 5.
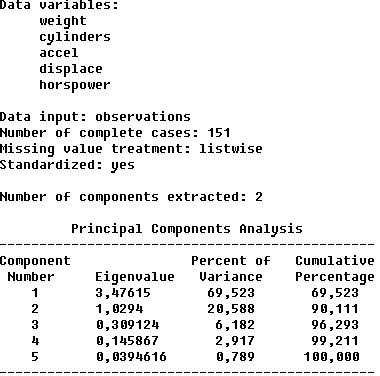
Рис.5. Сводка результатов анализа методом главных компонент
Здесь перечислены переменные, участвующих в анализе; указано количество объектов анализа – 151. Далее представлена информация о: собственных значениях главных компонент (eigenvalue), упорядоченных по величине; проценте дисперсии (percent of variance), приходящейся на каждую выделенную главную компоненту; накопленном проценте дисперсии (cumulative percentage).
Приведенные цифры говорят о том, что уже первые две главные компоненты описывают 90,11% дисперсии исходных данных. Третья главная компонента добавляет еще приблизительно 6,1% дисперсии, так, что в сумме получается 96,3% дисперсии.
Далее необходимо выдать таблицу весов признаков в главных компонентах.
Для этого нажать на правую клавишу мыши, выбрать пункт Analysis Options. В появившемся окне «Principal Components Options» в поле «Number of Components» установить количество компонент, равное трем (рис.6). Это необходимо также для дальнейшего построения 3-D диаграммы рассеивания в пространстве трех главных компонент.
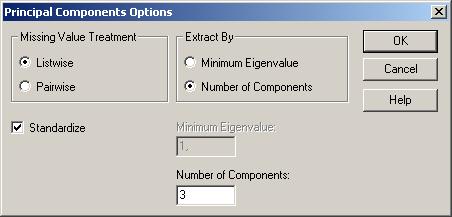
Рис.6. Окно «Principal Components Options»
Нажать кнопку табличных опций «Tabular Options» меню окна «Principal Components Analysis» и в соответствующем окне диалога установить флажок компонентных весов Component Weights. На рисунке 7 представлена получившаяся таблица весов признаков в главных компонентах.
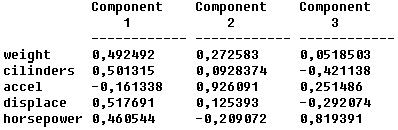
Рис.7. Таблица весов признаков в главных компонентах
Как следует из полученных данных о весовых коэффициентах, в 1-й главной компоненте признаки «вес», «количество цилиндров», «объем двигателя» и «мощность» имеют достаточно большие и приблизительно одинаковые по величине положительные коэффициенты. Во 2-й главной компоненте только признак «ускорение» имеет высокий весовой коэффициент. В 3-й главной компоненте наблюдаются большие по модулю весовые коэффициенты у признаков «вес», «мощность автомобиля», «количество цилиндров», причем последний признак имеет коэффициент с отрицательным знаком. Эти признаки, следовательно, являются значимыми и могут участвовать в формировании закономерностей типа «классификация».
4.1.5. Построить 3-D диаграмму рассеивания всей совокупности автомашин в пространстве выделенных трех первых главных компонент. Для этого нажать на кнопку меню «Graphical options» в окне «Principal Components Analysis» и выбрать трехмерное отображение «3-D Scatterplot» (рис. 8). Для максимального раскрытия окна можно дважды щелкнуть по диаграмме.
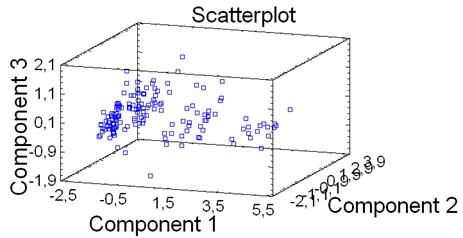
Рис.8. Проекция исследуемых автомобилей в пространство трех главных компонент
На представленном рисунке видно, что вся исследуемая совокупность автомашин разделилась на три достаточно четко выраженные группы.
В меню 3-D диаграммы рассеивания выполнить следующие действия:
1) идентификацию объекта по щелчку мыши. Для этого нажать на кнопку «Identify» меню окна «Principal Components Analysis» (рис.9) и в окне «Point Identification» выбрать атрибут (поле), по которому будет осуществляться идентификация объекта. Например, при выборе поля «name» при выделении интересующей точки на диаграмме рассеивания в строке Lbl будет отображено название фирмы-изготовителя автомобилей;
 Рис.9. Меню окна «Principal Components Analysis»
Рис.9. Меню окна «Principal Components Analysis»
2) поиск объекта по заданию одного из его признаков. Для этого нужно нажать на кнопку «Identify» и в появившемся окне выбрать признак, по которому будет производиться поиск. В строку Lbl ввести данные и нажать кнопку «Locate by name»; результатом поиска будут маркированные красным цветом объекты на диаграмме рассеивания;
3) идентификацию объекта по заданию номера строки в таблице. Для этого необходимо ввести в строку Row нужный номер и нажать кнопку «Locate by row»; требуемый объект будет маркирован красным цветом на диаграмме рассеивания;
4) вращение в разных плоскостях. Для этого необходимо нажать на кнопку «Smooth/Rotate» меню окна «Principal Components Analysis». В верхней части окна появятся ползунки для вращения диаграммы рассеивания вручную – по горизонтали и по вертикали, а также кнопки для автоматического вращения «Spin horizontally» и «Spin vertically».
4) анализ распределения объектов в построенном пространстве по заданному интервалу значений анализируемого признака. Для этого необходимо нажать на кнопку Brush меню окна «Principal Components Analysis» и ввести диапазон значений признака. Объекты, соответствующие этому диапазону, будут маркированы красным цветом.
4.1.6. Выбрать в процессе вращения наилучшее расположение трехмерной диаграммы рассеивания. Выделить предполагаемые кластеры.
Рекомендация к выполнению. Как правило, для выделения кластеров для выданного варианта задания требуется только первая главная компонента. Поэтому при вращении пространства нужно расположить ось первой главной компоненты в направлении оси ОХ. Проекции на нее предполагаемых кластеров должны быть наилучшим образом разделены. Отметим, что желательно традиционное расположение шкалы – по возрастанию значений компоненты.
Для выполняемого примера анализа рынка автомашин наилучшее расположение ЗD-диаграммы представлено на рисунке 8.
4.1.7. Выписать на бумаге списки номеров объектов по всем выделенным кластерам.
4.1.8. Сформулировать правила, характеризующие предполагаемые группы. Это выполнятся в два шага.
На первом шаге формулируются правила на основе ЗD-диаграммы, то есть в пространстве главных компонент.
Для примера по рынку автомашин (рисунок 8) для выделенных трех групп автомобилей можно сформулировать три правила, используя, например, проекции только на первую главную компоненту:
1) если значение F1=малое, то класс=1;
2) если значение F1=среднее, то класс=2;
3) если значение F1=большое, то класс=3.
На втором шаге формулируются правила в пространстве элементарных признаков на основе анализа весовых коэффициентов в главных компонентах.
Для этого необходимо: рассчитать коэффициент информативности для участвующих в анализе главных компонент (п.2.2); далее сформировать для каждой компонентысписок наиболее значимых признаков.
Для рассматриваемого примера сформулируем правила в пространстве элементарных признаков только для одной группы – первой, наиболее многочисленной. На основе расчета коэффициента информативности (п.2.2) для первой ГК делаются выводы о том, что она имеет следующие наиболее важные характеристики: вес, количество цилиндров, мощность и объем двигателя, то есть эти признаки вносят существенный вклад в формирование первой главной компоненты. В соответствии с правилом 1) для этой группы характерны малые значения компоненты F1. Чтобы обеспечить малые значения компоненты F1 необходимо, чтобы ее значимые признаки тоже принимали малые значения, поскольку весовые коэффициенты положительны. Это значит, что вес, количество цилиндров, мощность и объем двигателя должны быть сравнительно небольшими. Для отрицательных весовых коэффициентов - справедлива обратная пропорциональная зависимость.
Таким образом, правило 1) преобразуется к виду:
если вес=малый и количество цилиндров=малое и мощность =малая и объем двигателя=малый, то класс=1.
Аналогично преобразуются правила 2) и 3).
4.2. Для созданной согласно варианту задания выборки провести компонентный анализ по схеме, описанной в п.4.1.
Дополнительно к указанным в п.4.1 шагам выполнить следующие действия.
4.2.1. После выполнения п.4.1.6 и построения ЗD -диаграммы согласовать с преподавателем предполагаемое разбиение на группы.
Обычно можно выделить два хорошо сгруппированных множества объектов. Возможно, один объект будет удаленным от этих двух групп.
4.2.2. Дополнить выборку искусственно созданными объектами (предприятиями), которые должны быть расположены рядом с одиночным удаленным объектом. Вместе с ним эти объекты должны образовать третий кластер. При искусственном создании объектов нужно пользоваться уже извлеченными правилами, при этом нужно незначительно варьировать значимые признаки и можно существенно изменять незначимые признаки.
Согласовать с преподавателем разбиение на группы для расширенной выборки.
4.2.3. Выполнить компонентный анализ для расширенной выборки в соответствии с п.4.1.
Сформулировать результаты в виде:
а) списков номеров объектов по каждому выделенному кластеру;
б) выявленных правил классификации в пространстве главных компонент и в пространстве элементарных признаков для каждого выделенного кластера.
4.3 Выполнить кластерный анализ для расширенной выборки.
4.3.1. Выбрать из главного меню опцию Special > Multivariate Methods > Cluster Analysis. В появившемся окне задать переменные для анализа, для этого надо дважды щелкнуть левой кнопкой мыши на переменных accel, cylinders, displace, horspower, weight и нажать на стрелку «Data» (рис.10). Нажать ОК.
Рис.10. Окно диалога «Cluster Analysis» для задания анализируемых
переменных
4.3.2. Просмотреть первичную сводку кластерного анализа.
Окно с первичной сводкой кластерного анализа представлено на рисунке 11. В нем перечислены анализируемые переменные, указано число объектов анализа – 151. Ниже представлена информация: об используемом методе кластеризации «Clustering Method», о выбранной метрике «Distance Metric», количестве объектов в каждом кластере, соответствующем проценте населенности, а также приведены координаты центроидов («Centroids») для каждого кластера.
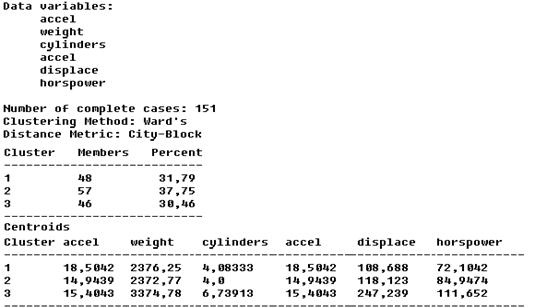
Рис.11. Окно с первичной сводкой кластерного анализа
Отметим, что первоначально количество кластеров равно единице.
4.3.3. Изменить параметры кластерного анализа. Для этого щелкнуть на окне правой клавишей мыши и на экране появляется окно диалога «Cluster Analysis Options» (рис.12).
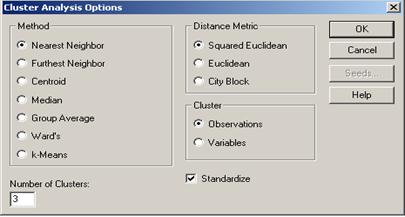
Рис.12. Окно диалога для выбора параметров кластерного анализа
Назначить необходимое количество кластеров (как правило, по количеству выделенных при проведении компонентного анализа групп).
Выбрать в качестве метода кластеризации метод Варда (установить флажок Ward’s), так как в рассматриваемом случае желательно, чтобы алгоритм кластеризации хорошо работал с небольшим количеством наблюдений и был нацелен на выделение кластеров с приблизительно равным количеством элементов.
Выбрать метрику City Block. Все остальные параметры оставить в прежнем положении.
4.3.4. Построить дендрограмму. Для этого нажать на кнопку «Graphical options» меню окна «Cluster Analysis», выбрать отображение в виде дендрограммы (Dendrogram) и нажать ОК. Результат построения дендрограммы, отображающей иерархическую структуру группирования объектов, представлен на рисунке 13.
На дендрограмме представлены три дерева. По вертикальной оси отложены расстояния, при которых происходят объединения кластеров для каждого шага работы агломеративного иерархического алгоритма. На горизонтальной оси расположены номера объектов наблюдения, скомбинированные в соответствии с последовательностью объединения.
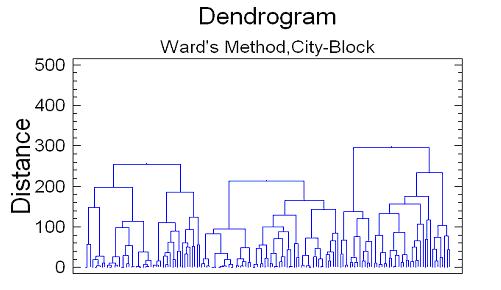
Рис.13. Дендрограмма
4.3.5. Просмотреть полный список всех объектов, их имена и номера кластеров, в которые входят указанные объекты. Для этого нажать кнопку табличных опций «Tabular Options» меню окна «Cluster Analysis» и в соответствующем окне диалога установить флажок таблицы «Membership Table» (рис.14).
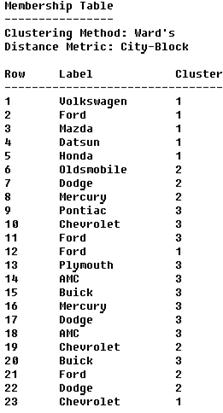
Рис.14. Таблица «Membership Table»
4.3.6. Создать двухмерную диаграмму рассеивания – для этого нажать на кнопку «Graphical options» и установить флажок 2D Scatterplot. Диаграмма рассеивания (рис.15) показывает, как группируются исследуемые наблюдения на плоскости двух переменных weight и horspower. Каждый кластер представлен на диаграмме собственным символом и цветом.
Первый кластер – самая многочисленная группа автомобилей, которая характеризуется сравнительно небольшим весом, и мощностью. Второй кластер включает в себя автомобили, которые имеют вес, несколько больший, чем в первой группе, но такую же мощность. В третий кластер входит намного меньше автомобилей, чем в первых двух кластерах, эти автомобили имеют большие вес и мощность.
Для того, чтобы построить диаграммы рассеивания на плоскости других признаков, достаточно щелкнуть правой кнопкой мыши и, выбрав пункт «Pane Options», выбрать интересующие пары переменных.
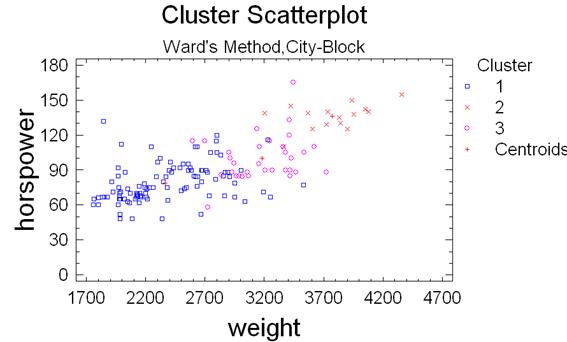
Рис.15. Диаграмма рассеивания, полученная в результате кластерного анализа
4.3.7. Выписать на бумаге списки номеров объектов по всем выделенным кластерам.
4.3.8. Сформулировать правила, характеризующие предполагаемые группы.
Для этого открыть еще раз сводку кластерного анализа (рис.11). На основе значений координат центроидов можно судить о том, какие переменные играют наиболее важную роль (обладают наибольшей классифицирующей силой).
Сформулировать предварительно правила классификации вида «если-то». Проверить их соответствие правилам классификации, построенным в компонентном анализе (п.4.2.3) для пространства элементарных признаков.
Построить диаграмму рассеивания на плоскости выбранных признаков, имеющих наибольшей классифицирующей силой.
Уточнить правила классификации, полученные в результате кластерного анализа.
4.4. Для анализа результатов, полученных на основе проведения компонентного и кластерного анализов, необходимо сравнить их по двум показателям:
1) по составу объектов в выделенных группах;
2) по сформированным правилам.
Варианты заданий
Предприятия характеризуются пятью показателями:
Y1 - производительность труда;
X5 - удельный вес рабочих в составе промышленно-производственного персонала;
X7 - коэффициент сменности оборудования (смен);
X9 - удельный вес потерь от брака (%);
X10 - фондоотдача активной части основных производственных фондов.
Значения этих показателей для предприятий представлены в файле Вар_задан_Дубров.xls.
Варианты заданий
Таблица 1
| № варианта | Номер предприятия (объекта) |
| 1. | 1,2,3,4,5,6,8,24,29,12,14,15,16,21,23,27,28 |
| 2. | 1,2,3,4,5,6,8,24,43,12,14,15,16,21,23,27,41 |
| 3. | 1,2,3,4,5,6,8,29,43,12,14,15,16,21,23,28,41 |
| 4. | 1,2,3,4,5,6,24,29,43,12,14,15,16,21,27,28,41 |
| 5. | 1,2,3,4,5,8,24,29,43,12,14,15,16,23,27,28,41 |
| 6. | 1,2,3,4,6,8,24,29,43,12,14,15,21,23,27,28,41 |
| 7. | 1,2,3,5,6,8,24,29,43,12,14,16,21,23,27,28,41 |
| 8. | 1,2,4,5,6,8,24,29,43,12,15,16,21,23,27,28,41 |
| 9. | 1,3,4,5,6,8,24,29,43,14,15,16,21,23,27,28,41 |
| 10. | 2,3,4,5,6,8,24,29,43,12,14,15,16,21,23,27,28 |
| 11. | 1,2,3,4,5,6,8,24,29,12,14,15,16,21,23,27,41 |
| 12. | 1,2,3,4,5,6,8,24,43,12,14,15,16,21,23,28,41 |
| 13. | 1,2,3,4,5,6,8,29,43,12,14,15,16,21,27,28,41 |
| 14. | 1,2,3,4,5,6,24,29,43,12,14,15,16,23,27,28,41 |
| 15. | 1,2,3,4,5,8,24,29,43,12,14,15,21,23,27,28,41 |
| 16. | 1,2,3,4,6,8,24,29,43,12,14,16,21,23,27,28,41 |
| 17. | 1,2,3,5,6,8,24,29,43,12,15,16,21,23,27,28,41 |
| 18. | 1,2,4,5,6,8,24,29,43,14,15,16,21,23,27,28,41 |
| 19. | 1,3,4,5,6,8,24,29,43,12,14,15,16,21,23,27,28 |
| 20. | 2,3,4,5,6,8,24,29,43,12,14,15,16,21,23,27,41 |
| 21. | 1,2,3,4,5,6,8,24,29,12,14,15,16,21,23,28,41 |
| 22. | 1,2,3,4,5,6,8,24,43,12,14,15,16,21,27,28,41 |
| 23. | 1,2,3,4,5,6,8,29,43,12,14,15,16,23,27,28,41 |
| 24. | 1,2,3,4,5,6,24,29,43,12,14,15,21,23,27,28,41 |
| 25. | 1,2,3,4,5,8,24,29,43,12,14,16,21,23,27,28,41 |

