 2015-03-08
2015-03-08 5446
5446Компилятор – это транслятор, который осуществляет перевод исходной программы в эквивалентную ей объектную программу на языке машинных команд или на языке ассемблера [10].
Компилятор отличается от транслятора лишь тем, что его результирующая программа всегда должна быть написана на языке машинных кодов или на языке ассемблера. Результирующая программа транслятора, в общем случае, может быть синтезирована на любом языке – возможен, например, транслятор программ с языка Pascal на язык С. Соответственно, всякий компилятор является транслятором, но не наоборот – не всякий транслятор будет компилятором. Например, упомянутый выше транслятор с языка Pascal на С компилятором являться не будет.
Результирующая программа компилятора называется «объектной программой» или «объектным кодом». Файл, в который она записана, обычно называется «объектным файлом». Даже в том случае, когда результирующая программа порождается на языке машинных команд, между объектной программой (объектным файлом) и исполняемой программой (исполняемым файлом) есть существенная разница. Порожденная компилятором программа не может непосредственно выполняться на компьютере, так как она не привязана к конкретной области памяти где должны располагаться ее код и данные.
Компиляторы, безусловно, самый распространенный вид трансляторов (многие считают их вообще единственным видом трансляторов, хотя это не так). Они имеют самое широкое практическое применение, которым обязаны широкому распространению всевозможных языков программирования.
Схема работы компилятора представлена на рисунке 17.
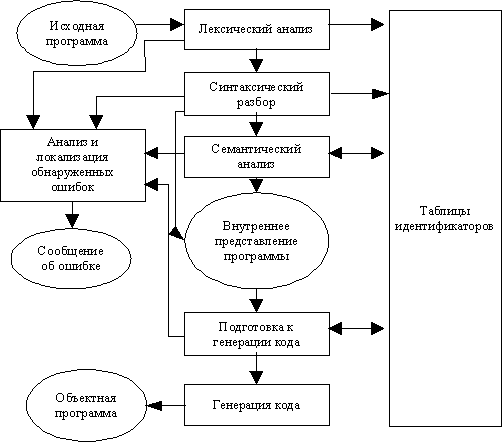 Рисунок 17 - Общая схема работы компилятора Рисунок 17 - Общая схема работы компилятора |
Условно все этапы работы компилятора можно разбить на 2 группы[10]: этапы анализа исходной программы и этапы синтеза объектной программы на машинном языке.
Этапы анализа исходной программы включают в себя: лексический анализ, синтаксический разбор и семантический анализ. Этапы синтеза — подготовка к генерации кода и, собственно, генерация кода.
На этапе анализа выполняется распознавание текста исходной программы, создание и заполнение таблиц идентификаторов. Результатом его работы служит некое внутреннее представление программы, понятное компилятору.
На этапе синтеза на основании внутреннего представления программы и информации, содержащейся в таблице (таблицах) идентификаторов, порождается текст результирующей программы. Результатом этого этапа является объектный код
Кроме того, в составе компилятора присутствует часть, ответственная за анализ и исправление ошибок, которая при наличии ошибки в тексте исходной программы должна максимально полно информировать пользователя о типе ошибки и месте ее возникновения. В лучшем случае компилятор может предложить пользователю вариант исправления ошибки
Эти этапы, в свою очередь, состоят из более мелких этапов, называемых фазами компиляции. Состав фаз компиляции приведен в самом общем виде, их конкретная реализация и процесс взаимодействия могут, конечно, различаться в зависимости от версии компилятора. Однако в том или ином виде все представленные фазы практически всегда присутствуют в каждом конкретном компиляторе.
Компилятор в целом с точки зрения теории формальных языков выполняет две основные функции:
1) Он является распознавателем для языка исходной программы. То есть он должен получить на вход цепочку символов входного языка, проверить ее принадлежность языку и, более того, выявить правила, по которым эта цепочка была построена (поскольку сам ответ на вопрос о принадлежности «да» или «нет» представляет мало интереса). Интересно, что генератором цепочек входного языка выступает пользователь — автор входной программы;
2) Компилятор является генератором для языка результирующей программы. Он должен построить на выходе цепочку выходного языка по определенным правилам, предполагаемым языком машинных команд или языком ассемблера. Распознавателем этой цепочки будет выступать уже вычислительная система, под которую создается результирующая программа.
Существует несколько основных фаз (этапов) компиляции, каждая из которых выполняет определенную функцию.
Лексический анализ (сканер) - это часть компилятора, которая читает литеры программы на исходном языке и строит из них слова (лексемы[2]) исходного языка. На вход лексического анализатора поступает текст исходной программы, а выходная информация передается для дальнейшей обработки компилятором на этапе синтаксического разбора. С теоретической точки зрения лексический анализатор не является обязательной, необходимой частью компилятора. Однако существует причины, которые определяют его присутствие практически во всех компиляторах.
Синтаксический разбор — это основная часть работы компилятора на этапе анализа. Она выполняет выделение синтаксических конструкций в тексте исходной программы, обработанном лексическим анализатором. На этой же фазе компиляции проверяется синтаксическая правильность программы. Синтаксический разбор играет главную роль - роль распознавателя текста входного языка программирования.
Семантический анализ – это часть работы компилятора, проверяющая правильность текста исходной программы с точки зрения семантики входного языка. Кроме непосредственно проверки, семантический анализ должен выполнять преобразования текста, требуемые семантикой входного языка (такие, как добавление функций неявного преобразования типов). В различных реализациях компиляторов семантический анализ может частично входить в фазу синтаксического разбора, частично - в фазу подготовки к генерации кода.
Подготовка к генерации кода – это этап, на котором компилятором выполняются предварительные действия, непосредственно связанные с синтезом текста результирующей программы, но еще не ведущие к порождению текста на выходном языке. Обычно в эту фазу входят действия, связанные с идентификацией элементов языка, распределением памяти и т. п.
Генерация кода – это фаза непосредственно связанна с порождением команд, составляющих предложения выходного языка и в целом текст результирующей программы. Это основная фаза на этапе синтеза результирующей программы. Кроме непосредственного порождения текста результирующей программы, генерация обычно включает в себя также оптимизацию – процесс, связанный с обработкой уже порожденного текста. Иногда оптимизацию выделяют в отдельную фазу компиляции, так как она оказывает существенное влияние на качество и эффективность результирующей программы.
Таблицы идентификаторов (иногда – «таблицы символов») – это специальным образом организованные наборы данных, служащие для хранения информации об элементах исходной программы, которые затем используются для порождения текста результирующей программы. Таблица идентификаторов в конкретной реализации компилятора может быть одна, или же таких таблиц может быть несколько. Элементами исходной программы, информацию о которых нужно хранить в процессе компиляции, являются имена переменных, константы, функции и т. п. – конкретный состав набора элементов зависит от используемого входного языка программирования. Понятие «таблицы» вовсе не предполагает, что это хранилище данных должно быть организовано именно в виде таблиц или других массивов информации.
Интерпретатор – это программа, которая воспринимает входную программу на исходном языке и выполняет ее.
В отличие от трансляторов интерпретаторы не порождают результирующую программу (и вообще какого-либо результирующего кода) – и в этом принципиальная разница между ними. Интерпретатор, так же как и транслятор, анализирует текст исходной программы. Однако он не порождает результирующей программы, а сразу же выполняет исходную, в соответствии с ее смыслом, заданным семантикой входного языка. Таким образом, результатом работы интерпретатора будет результат, заданный смыслом исходной программы, в том случае, если эта программа правильная, или сообщение об ошибке, если исходная программа неверна.
Конечно, чтобы исполнить исходную программу, интерпретатор так или иначе должен преобразовать ее в язык машинных кодов, поскольку иначе выполнение программ на компьютере невозможно. Он и делает это, однако полученные машинные коды не являются доступными – их не видит пользователь интерпретатора. Эти машинные коды порождаются интерпретатором, исполняются и уничтожаются по мере надобности – так, как того требует конкретная реализация интерпретатора. Пользователь же видит результат выполнения этих кодов – то есть результат выполнения исходной программы (требование об эквивалентности исходной программы и порожденных машинных кодов и в этом случае, безусловно, должно выполняться).
Компиляторы обычно несколько проще в реализации, чем интерпретаторы. По эффективности они также превосходят их — очевидно, что откомпилированный код будет исполняться всегда быстрее, чем происходит интерпретация аналогичной исходной программы. Кроме того, не каждый язык программирования допускает построение простого интерпретатора. Однако интерпретаторы имеют одно существенное преимущество — откомпилированный код всегда привязан к архитектуре вычислительной системы, на которую он ориентирован, а исходная программа — только к семантике языка программирования, которая гораздо легче поддается стандартизации.
История интерпретаторов не столь богата. Изначально им не предавали существенного значения, поскольку почти по всем параметрам они уступают компиляторам. Из известных языков, предполагавших интерпретацию, можно упомянуть разве что Basic, хотя большинству сейчас известна его компилируемая реализация Visual Basic, сделанная фирмой Microsoft.Тем не менее сейчас ситуация несколько изменилась, поскольку вопрос о переносимости программ и их аппаратно-платформенной независимости приобретает все большую актуальность с развитием сети Интернет. Самый известный сейчас пример — это язык Java (сам по себе он сочетает компиляцию и интерпретацию), а также связанный с ним JavaScript. В конце концов, язык HTML, на котором зиждется протокол HTTP, давший толчок столь бурному развитию Всемирной сети, — это тоже интерпретируемый язык.
Различие между интерпретатором и компилятором обуславливает и различие в структуре компиляторов и интерпретаторов: интерпретатор не формирует объектную программу, поэтому сгенерированный код сразу выполняется на целевой ЭВМ.

