 2015-03-07
2015-03-07 1477
1477При решении некоторых гидрологических задач необходимо иметь ряды продолжительностью в несколько сотен и даже тысяч лет. Поскольку ряды такой продолжительности отсутствуют, были разработаны методы моделирования искусственных гидрологических рядов. При использовании этих методов вначале производится оценка параметров распределения имеющегося эмпирического ряда, а затем моделируется искусственный ряд с такой же статистической структурой, но гораздо большей продолжительности.
В основе моделирования искусственных гидрологических рядов лежит метод Монте-Карло. Метод Монте-Карло – это метод решения математических задач при помощи моделирования случайных величин.
Процесс моделирования включает несколько этапов. На первом этапе требуется получить последовательность случайных чисел равномерно распределенных на интервале [0 –1] (см. п. 2.2).
Различают три способа получения случайных чисел: таблицы случайных чисел, генераторы случайных чисел и метод псевдослучайных чисел.
Простейшим генератором случайных чисел является рулетка. С помощью устройств типа рулетки легко сгенерировать случайные последовательности любой продолжительности. Полученные таким образом случайные последовательности можно оформить в виде таблиц. Самая большая из опубликованных таблиц случайных чисел содержит один миллион цифр. Однако при работе на компьютере удобнее пользоваться так называемыми псевдослучайными числами.
Первый алгоритм для получения псевдослучайных чисел был предложен Дж. Нейманом. Он называется методом середины квадратов. Поясним его на примере.
Пусть задано 4-значное число 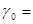 0,9876. Возведем его в квадрат. Получим 8-значное число (
0,9876. Возведем его в квадрат. Получим 8-значное число (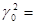 0,97535376). Выберем четыре средние цифры этого числа и положим
0,97535376). Выберем четыре средние цифры этого числа и положим 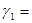 0,5353. Затем возведем
0,5353. Затем возведем 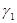 в квадрат (
в квадрат (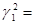 0,28654609) и снова извлечем четыре средние цифры. Получим
0,28654609) и снова извлечем четыре средние цифры. Получим 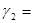 0,6546. Далее,
0,6546. Далее, 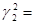 0,42850116,
0,42850116, 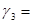 0,8501;
0,8501; 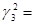 0,72267001,
0,72267001, 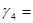 2670;
2670; 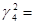 0,07128900,
0,07128900, 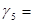 0,1289 и т. д.
0,1289 и т. д.
Но этот алгоритм не оправдал себя: получалось больше чем нужно малых значений. Позже разными исследователями были разработаны другие, более совершенные алгоритмы.
В настоящее время на любом персональном компьютере имеется возможность генерации случайных чисел равномерно распределенных в интервале [0 – k], где k – положительное целое число.
В качестве примера рассмотрим программу на языке Pascal, которая генерирует 20 значений случайной величины, равномерно распределенных на интервале [1 –50]:
var i: integer;
begin
Randomize; {смена базы генератора псевдослучайных чисел}
For i:= 1 to 20 do
begin
writeln(Random(50)) {генерация случайного числа}
end
end.
Процедура Randomize устанавливает начальное значение датчика случайных чисел в зависимости от показания системного таймера. Поэтому при каждом запуске программы будет генерироваться новая выборка.
Вместо процедуры Randomize можно использовать системную переменную RandSeed, которая позволяет загрузить конкретную базу для датчика случайных чисел. Если переменной RandSeed присваивать одно и тоже значение, то будут генерироваться одинаковые выборки. RandSeed может принимать любые целые значения из диапазона –2147483648..2147483647. То есть имеется возможность сгенерировать более 4 миллиардов различных выборок.
На следующем этапе моделирования каждое значение случайной величины равномерно распределенной на интервале [0 – 1] рассматривается как вероятность непревышения и по нему рассчитывается соответствующий квантиль заданного закона распределения (рис.6.16).
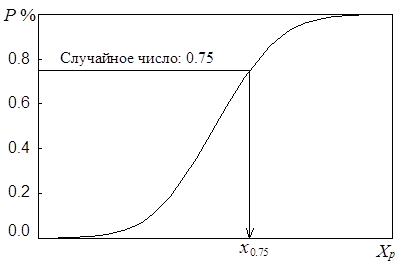
Рис.6.16. Схема моделирования случайной величины с заданным законом распределения.
Переход от случайных чисел равномерно распределенных на отрезке [0 – 1] к случайным числам с заданным законом распределения выполняется аналитически с использованием обратной функции от интегрального закона распределения. Если аналитического решения обратной задачи не существует, то задача решается с использованием численных методов.
Применяя изложенную схему можно написать компьютерную программу на любом языке программирования. Однако довольно часто достаточно воспользоваться уже готовыми программами. Например, "Пакет анализа", который входит в состав Microsoft Excel, позволяет моделировать ряды для 7 законов распределения. Еще большими возможностями обладают специальные статистические пакеты.
Если вероятностная структура ряда соответствует модели случайного процесса, то алгоритм несколько сложнее.
Так для моделирования ряда соответствующего модели авторегрессии первого порядка (см. п. 6.13) можно воспользоваться рекурентной формулой:
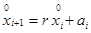 , (6.138)
, (6.138)
где 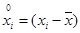 – центрированный случайный процесс; r – коэффициент автокорреляции; ai – случайная составляющая (белый шум).
– центрированный случайный процесс; r – коэффициент автокорреляции; ai – случайная составляющая (белый шум).
Соответствующая блок-схема представлена на рис.6.17.
Для моделирования необходимо иметь следующие параметры: среднее значение 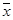 , среднеквадратическое отклонение
, среднеквадратическое отклонение 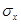 , отношение Сs / Cv, коэффициент автокорреляции r и начальное значение моделируемой гидрологической характеристики x 1. В качестве начального значения можно в большинстве случаев принять среднее значение (в этом случае
, отношение Сs / Cv, коэффициент автокорреляции r и начальное значение моделируемой гидрологической характеристики x 1. В качестве начального значения можно в большинстве случаев принять среднее значение (в этом случае 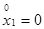 ). Кроме того, требуется указать тип распределения, например – Крицкого-Менкеля или Пирсона III типа.
). Кроме того, требуется указать тип распределения, например – Крицкого-Менкеля или Пирсона III типа.
При моделировании по формуле (6.138) на каждом шаге генерируется значение случайной величины ai по ранее изложенной схеме.
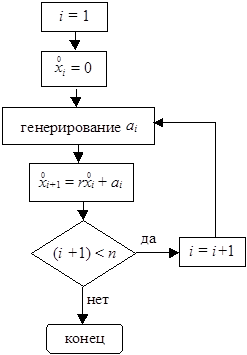
Рис.6.17. Блок-схема для генерации рядов по модели авторегрессии первого порядка.
Тип распределения для шумовой составляющей ai и отношение Сs / Cv принимаются такими же, как для исходного ряда, среднее значение может быть принято равным нулю, а СКО в соответствии с формулой (6.86) определяется выражением:
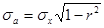 . (6.139)
. (6.139)
Для моделирования рядов соответствующих модели авторегресии второго порядка используется формула (6.80).
В п.6.13 приводятся также формулы для моделирования по моделям скользящего среднего (CC) и АРСС.

