 2015-04-12
2015-04-12 675
675Идея этого алгоритма в следующем. Разобьем элементы сортируемого массива на h цепочек, каждая из которых состоит из элементов, отстоящих друг от друга на расстояние h (здесь h – произвольное натуральное число). Первая цепочка будет содержать элементы a1, ah+1, a2h+1, a3h+1 и т.д., вторая – a2, ah+2, a2h+2 и т.д., последняя цепочка – ah, a2h, a3h и т.д. Отсортируем каждую цепочку как отдельный массив, используя для этого метод простых или бинарных вставок. Затем выполним все вышеописанное для ряда убывающих значений h, причем последний раз – для h = 1.
Очевидно, массив после этого окажется сортированным. Неочевидно, что все проходы при h > 1 не были пустой тратой времени. Тем не менее, оказывается, что дальние переносы элементов при больших h настолько приближают массив к сортированному состоянию, что на последний проход остается очень мало работы.
Большое значение для эффективности алгоритма Шелла имеет удачный выбор убывающей последовательности значений h. Казалось бы, самая естественная убывающая последовательность чисел это степени двойки: …, 64, 32, 16, 8, 4, 2, 1. Сам автор алгоритма Дональд Шелл первоначально предложил использовать именно эти числа. На самом же деле выбор этой последовательности – один из самых неудачных! Пусть, например, в исходном массиве все нечетные по номеру элементы отрицательны, а четные – положительны. Как будет выглядеть такой массив после выполнения всех проходов, кроме последнего (с h = 1)? Поскольку все использованные h были четными, ни один элемент не мог переместиться с четного места на нечетное и наоборот. Таким образом, все нечетные элементы по-прежнему будут отрицательны (хотя и отсортированы между собой), а четные – положительны. Подобный массив трудно назвать «почти сортированным»! На последний проход алгоритма вставки остается слишком много работы.
Чтобы избежать подобной неприятности, желательно, чтобы при соседних значениях k значения hk не были кратны друг другу. В литературе обычно рекомендуется использовать одну из двух последовательностей: hk+1 = 3hk+1 или hk+1 = 2hk+1. В обоих случаях в качестве начального hk выбирается такое значение из последовательности, при котором все сортируемые цепочки имеют длину не меньше 2. Чтобы воспользоваться, например, первой из этих формул, надо сначала положить h1:=1, а затем в цикле увеличивать значение h по формуле hk+1:= 3*hk+1, пока для очередного hk не будет выполнено неравенство hk ³ (n–1) div 3. Это значение hk следует использовать на первом проходе алгоритма, а затем можно получать следующие значения по обратной формуле: hk–1:= (hk–1) div 3, вплоть до h1=1.
Для каждой из этих двух последовательностей время работы в худшем случае оценивается как Tмакс(n) = O(n3/2). Это значительно лучше, чем O(n2) для простых алгоритмов. Для среднего времени работы известны только эмпирические оценки, показывающие, что время растет примерно как O(n1.25) или O(n1.3).
Ряд авторов на основе теоретического анализа сортировки Шелла предложили использовать более сложные последовательности, повышающие эффективность алгоритма. Одной из лучших считается последовательность, предложенная Р.Седжвиком:
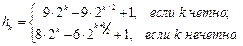
Доказано, что при выборе hk по Седжвику максимальное время работы алгоритма есть O(n4/3). Среднее время по эмпирическим оценкам равно примерно O(n7/6).
На практике удобно раз и навсегда вычислить достаточное количество членов последовательности Седжвика (вот они: 1, 5, 19, 41, 109, 209, 505, 929, 2 161, 3 905, 8 929, 16 001, 36 289, 64 769, 14 6305, 260 609, 587 521, 1 045 505,...), затем по заданному n выбрать такое k, при котором hk >= (n–1) div 3, а далее в цикле выбирать значения последовательности hk по убыванию k.








