 2015-04-01
2015-04-01 12584
12584Статистическая значимость результата (p-значение) представляет собой оцененную меру уверенности в его «истинности» (в смысле «репрезентативности выборки»). Выражаясь более технически, p-значение ‑ это показатель, находящийся в убывающей зависимости от надежности результата. Более высокое p-значение соответствует более низкому уровню доверия к найденной в выборке зависимости между переменными. Именно, p-значение представляет собой вероятность ошибки, связанной с распространением наблюдаемого результата на всю популяцию. Например, p-значение=0.05 (т.е. 1/20) показывает, что имеется 5% вероятность, что найденная в выборке связь между переменными является лишь случайной особенностью данной выборки. Иными словами, если данная зависимость в популяции отсутствует, а вы многократно проводили бы подобные эксперименты, то примерно в одном из двадцати повторений эксперимента можно было бы ожидать такой же или более сильной зависимости между переменными.
Во многих исследованиях p-значение=0.05 рассматривается как «приемлемая граница» уровня ошибки.
Не существует никакого способа избежать произвола при принятии решения о том, какой уровень значимости следует действительно считать «значимым». Выбор определенного уровня значимости, выше которого результаты отвергаются как ложные, является достаточно произвольным. На практике окончательное решение обычно зависит от того, был ли результат предсказан априори (т.е. до проведения опыта) или обнаружен апостериорно в результате многих анализов и сравнений, выполненных с множеством данных, а также на традиции, имеющейся в данной области исследований. Обычно во многих областях результат p 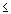 0.05 является приемлемой границей статистической значимости, однако следует помнить, что этот уровень все еще включает довольно большую вероятность ошибки (5%). Результаты, значимые на уровне p 0.01 обычно рассматриваются как статистически значимые, а результаты с уровнем p 0.005 или p 0.001 как высоко значимые. Однако следует понимать, что данная классификация уровней значимости достаточно произвольна и является всего лишь неформальным соглашением, принятым на основе практического опыта в той или иной области исследования.
0.05 является приемлемой границей статистической значимости, однако следует помнить, что этот уровень все еще включает довольно большую вероятность ошибки (5%). Результаты, значимые на уровне p 0.01 обычно рассматриваются как статистически значимые, а результаты с уровнем p 0.005 или p 0.001 как высоко значимые. Однако следует понимать, что данная классификация уровней значимости достаточно произвольна и является всего лишь неформальным соглашением, принятым на основе практического опыта в той или иной области исследования.
Как было уже сказано, величина зависимости и надежность представляют две различные характеристики зависимостей между переменными. Тем не менее, нельзя сказать, что они совершенно независимы. Говоря общим языком, чем больше величина зависимости (связи) между переменными в выборке обычного объема, тем более она надежна.
Если предполагать отсутствие зависимости между соответствующими переменными в популяции, то наиболее вероятно ожидать, что в исследуемой выборке связь между этими переменными также будет отсутствовать. Таким образом, чем более сильная зависимость обнаружена в выборке, тем менее вероятно, что этой зависимости нет в популяции, из которой она извлечена.
Объем выборки влияет на значимость зависимости. Если наблюдений мало, то соответственно имеется мало возможных комбинаций значений этих переменных и таким образом, вероятность случайного обнаружения комбинации значений, показывающих сильную зависимость, относительно велика.
Как вычисляется уровень статистической значимости. Предположим, вы уже вычислили меру зависимости между двумя переменными (как объяснялось выше). Следующий вопрос, стоящий перед вами: «насколько значима эта зависимость?» Например, является ли 40% объясненной дисперсии между двумя переменными достаточным, чтобы считать зависимость значимой? Ответ: «в зависимости от обстоятельств». Именно, значимость зависит в основном от объема выборки. Как уже объяснялось, в очень больших выборках даже очень слабые зависимости между переменными будут значимыми, в то время как в малых выборках даже очень сильные зависимости не являются надежными. Таким образом, для того чтобы определить уровень статистической значимости, вам нужна функция, которая представляла бы зависимость между «величиной» и «значимостью» зависимости между переменными для каждого объема выборки. Данная функция указала бы вам точно «насколько вероятно получить зависимость данной величины (или больше) в выборке данного объема, в предположении, что в популяции такой зависимости нет». Другими словами, эта функция давала бы уровень значимости (p-значение), и, следовательно, вероятность ошибочно отклонить предположение об отсутствии данной зависимости в популяции. Эта «альтернативная» гипотеза (состоящая в том, что нет зависимости в популяции) обычно называется нулевой гипотезой. Было бы идеально, если бы функция, вычисляющая вероятность ошибки, была линейной и имела только различные наклоны для разных объемов выборки. К сожалению, эта функция существенно более сложная и не всегда точно одна и та же. Тем не менее, в большинстве случаев ее форма известна, и ее можно использовать для определения уровней значимости при исследовании выборок заданного размера. Большинство этих функций связано с очень важным классом распределений, называемым нормальным.

