 2015-04-17
2015-04-17 505
505| №/№ | y | x1 | x2 | №/№ | y | x1 | x2 |
| 48,01 | 0,91 | 46,08 | 36,26 | 0,90 | 40,06 | ||
| 38,18 | 0,76 | 45,18 | 32,07 | 0,52 | 57,91 | ||
| 38,7 | 0,82 | 41,76 | 32,83 | 0,66 | 43,86 | ||
| 46,72 | 0,88 | 50,94 | 35,16 | 0,58 | 58,62 | ||
| 41,58 | 0,88 | 43,54 | 44,56 | 0,99 | 44,39 | ||
| 36,89 | 0,89 | 38,8 | 59,16 | 1,63 | 35,77 | ||
| 34,54 | 0,87 | 39,22 | 67,99 | 1,95 | 35,96 | ||
| 42,86 | 0,94 | 42,74 | 53,73 | 1,27 | 40,99 | ||
| 38,97 | 0,91 | 41,2 | 52,39 | 1,55 | 33,05 | ||
| 43,22 | 1,07 | 39,35 | 36,1 | 1,15 | 30,68 | ||
| 28,19 | 0,69 | 34,38 | 32,67 | 0,94 | 34,26 | ||
| 38,65 | 0,74 | 48,98 | Σ | 959,43 | 22,5 | 967,72 |
Можно попробовать включить в уравнение регрессии второй фактор x2 и проанализировать получившийся результат. При построении уравнений множественной регрессии возникает много дополнительных сложностей по сравнению с процессом построения уравнений парной регрессии. Сами системы нормальных уравнений для вычисления параметров регрессии включают больше уравнений и неизвестных, но кроме того, возникает дополнительная проблема отбора тех факторных переменных, которые целесообразно включить в уравнений множественной регрессии.
На лекции №1 мы уже говорили о проблеме мультиколлинеарности и о том, что в уравнение множественной регрессии нельзя включать факторы, между которыми существует линейная статистическая зависимость (корреляционная связь), измеряемая с помощью коэффициента парной корреляции. Но, может быть, в уравнение регрессии достаточно включить только единственный фактор, а включение дополнительного фактора будет лишним? Попытаемся оценить это с помощью расчета коэффициента детерминации.
Этот показатель рассчитывается как отношение двух дисперсий (дисперсии расчетных значений и дисперсии фактических значений результативной переменной y) и показывает, какая часть вариации результативного признака может быть объяснена влиянием факторного признака.
Проведя расчеты, основанные на одних и тех же исходных данных, для нескольких типов функций, мы можем из них выбрать такую, которая дает наибольшее значение R2 и, следовательно, в большей степени, чем другие функции, объясняет вариацию результативного признака. Коэффициент детерминации рассчитывается по формуле:
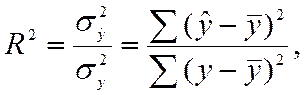 (3.1)
(3.1)
где в числителе- дисперсия расчетных, а в знаменателе – дисперсия фактических значений изучаемого признака.
Действительно, при расчете R2 для одних и тех же данных, но разных функций знаменатель выражения (3.1) остается неизменным, а числитель показывает ту часть вариации результативного признака, которая учитывается выбранной функцией. Чем больше R2, т. е. чем больше числитель, тем больше изменение факторного признака объясняет изменение результативного признака и тем, следовательно, лучше уравнение регрессии, лучше выбор функции.
Рассчитаем коэффициент детерминации для уравнения у = 17,8 + 24,5x, полученного в примере, рассмотренном на предыдущей лекции. Вычисляем R2, воспользовавшись формулой (3.1) и данными табл. 3.1.
Вначале построим вспомогательную таблицу для определения ошибки аппроксимации и дисперсий фактических и расчетных значений признака (табл. 3.2).
Таблица 3.2
Вспомогательная таблица для расчета ошибки аппроксимации и индекса детерминации для уравнения у = 17,8 + 24,5x
| y | yx | y-yx | (y-yx)2 | (y-yср)2 | (yx-yср )2 |
| 48,01 | 40,04 | 7,97 | 63,48 | 39,64 | 2,79 |
| 38,18 | 36,37 | 1,81 | 3,28 | 12,49 | 28,57 |
| 38,70 | 37,84 | 0,86 | 0,74 | 9,09 | 15,02 |
| 46,72 | 39,31 | 7,41 | 54,94 | 25,06 | 5,79 |
| 41,58 | 39,31 | 2,27 | 5,16 | 0,02 | 5,79 |
| 36,89 | 39,55 | -2,66 | 7,09 | 23,27 | 4,67 |
| 34,54 | 39,06 | -4,52 | 20,46 | 51,47 | 7,03 |
| 42,86 | 40,78 | 2,08 | 4,34 | 1,31 | 0,88 |
| 38,97 | 40,04 | -1,07 | 1,15 | 7,53 | 2,79 |
| 43,22 | 43,96 | -0,74 | 0,55 | 2,27 | 5,05 |
| 28,19 | 34,65 | -6,46 | 41,79 | 182,91 | 49,84 |
| 38,65 | 35,88 | 2,77 | 7,68 | 9,39 | 34,05 |
| 36,26 | 39,80 | -3,54 | 12,52 | 29,75 | 3,67 |
| 32,07 | 30,49 | 1,58 | 2,49 | 93,01 | 125,96 |
| 32,83 | 33,92 | -1,09 | 1,19 | 78,93 | 60,75 |
| 35,16 | 31,96 | 3,20 | 10,24 | 42,96 | 95,13 |
| 44,56 | 42,00 | 2,56 | 6,54 | 8,10 | 0,08 |
| 59,16 | 57,68 | 1,48 | 2,20 | 304,35 | 254,77 |
| 67,99 | 65,51 | 2,48 | 6,14 | 690,41 | 566,36 |
| 53,73 | 48,86 | 4,87 | 23,72 | 144,38 | 51,05 |
| 52,39 | 55,72 | -3,33 | 11,07 | 113,97 | 196,06 |
| 36,10 | 45,92 | -9,82 | 96,44 | 31,52 | 17,69 |
| 32,67 | 40,78 | -8,11 | 65,73 | 81,80 | 0,88 |
| 959,43 | 959,43 | 0,00 | 448,93 | 1983,62 | 1534,69 |
Используя суммы, рассчитанные в последней (итоговой) строке таблицы 3.2, для расчета ошибки аппроксимации и индекса детерминации, получаем:
R 2 = 0,774 = 77,4% (3.2)
σ2 = 4,42 (3.3)
Итак, уравнение регрессии примерно на 77 % объясняет колебания сбора хлеба на душу. Это немало, но, по-видимому, можно улучшить модель введением в нее еще одного фактора.
Одной из дополнительных проблем, возникающих при построении уравнений множественной регрессии, является проблема отбора факторов, которые целесообразно включать в модель. Если известны данные о множестве самых различных факторов, каждый из которых может оказать то или иное влияние на результирующий показатель, обычно отбирают 2-3 фактора по результатам анализа мультиколлинеарности.
В рассмотренном ранее примере известны данные только о двух факторах, которые могут быть включены в модель. Поэтому далее мы рассмотрим построение уравнения двухфакторной линейной регрессии, включив в уравнение, кроме фактора x1 дополнительный фактор x2 – урожайность зерна.








