 2015-04-17
2015-04-17 2933
2933Спиральная модель (англ. spiral model) была разработана в середине 1980-х годов Барри Боэмом. Она основана на классическом цикле Деминга PDCA (plan-do-check-act). При использовании этой модели ПО создается в несколько итераций (витков спирали) методом прототипирования.
Каждая итерация соответствует созданию фрагмента или версии ПО, на ней уточняются цели и характеристики проекта, оценивается качество полученных результатов и планируются работы следующей итерации.
На каждой итерации оцениваются:
· риск превышения сроков и стоимости проекта;
· необходимость выполнения ещё одной итерации;
· степень полноты и точности понимания требований к системе;
· целесообразность прекращения проекта.
Важно понимать, что спиральная модель является не альтернативой эволюционной модели (модели IID), а специально проработанным вариантом. К сожалению, нередко спиральную модель либо ошибочно используют как синоним эволюционной модели вообще, либо (не менее ошибочно) упоминают как совершенно самостоятельную модель наряду с IID.
Отличительной особенностью спиральной модели является специальное внимание, уделяемое рискам, влияющим на организацию жизненного цикла, и контрольным точкам. Боэм формулирует 10 наиболее распространённых (по приоритетам) рисков:
1. Дефицит специалистов.
2. Нереалистичные сроки и бюджет.
3. Реализация несоответствующей функциональности.
4. Разработка неправильного пользовательского интерфейса.
5. Перфекционизм, ненужная оптимизация и оттачивание деталей.
6. Непрекращающийся поток изменений.
7. Нехватка информации о внешних компонентах, определяющих окружение системы или вовлеченных в интеграцию.
8. Недостатки в работах, выполняемых внешними (по отношению к проекту) ресурсами.
9. Недостаточная производительность получаемой системы.
10. Разрыв в квалификации специалистов разных областей.
В сегодняшней спиральной модели определён следующий общий набор контрольных точек:
1. Concept of Operations (COO) — концепция (использования) системы;
2. Life Cycle Objectives (LCO) — цели и содержание жизненного цикла;
3. Life Cycle Architecture (LCA) — архитектура жизненного цикла; здесь же возможно говорить о готовности концептуальной архитектуры целевой программной системы;
4. Initial Operational Capability (IOC) — первая версия создаваемого продукта, пригодная для опытной эксплуатации;
5. Final Operational Capability (FOC) –— готовый продукт, развернутый (установленный и настроенный) для реальной эксплуатации.
Реализация процесса ЖЦ ПО.
Стандарт группирует различные виды деятельности, которые могут выполняться в течение жизненного цикла программных систем, в семь групп процессов. Каждый из процессов жизненного цикла в пределах этих групп описывается в терминах цели и желаемых выходов, списков действий и задач, которые необходимо выполнять для достижения этих результатов.
· процессы соглашения — два процесса;
· процессы организационного обеспечения проекта — пять процессов;
· процессы проекта — семь процессов;
· технические процессы — одиннадцать процессов;
· процессы реализации программных средств — семь процессов;
· процессы поддержки программных средств — восемь процессов;
· процессы повторного применения программных средств — три процесса.
Каждый процесс включает ряд действий. Например, процесс приобретения охватывает следующие действия:
1. Инициирование приобретения
2. Подготовка заявочных предложений
3. Подготовка и корректировка договора
4. Надзор за деятельностью поставщика
5. Приемка и завершение работ
Основные модели ЖЦ разработки ПО. (Современные методы разработки ПО)
Метод нисходящего проектирования (метод пошаговой детализации, метод иерархического проектирования, top-down-подход)
Суть метода заключается в определении спецификаций компонентов системы путем последовательного выделения в ее составе отдельных составляющих и их постепенной детализации до уровня, обеспечивающего однозначное понимание того, что и как необходимо разрабатывать и реализовывать.
Реализация метода нисходящего проектирования тесно связана с другим понятием программирования - модульным проектированием, так как на практике при декомпозиции сложной программы возникает вопрос о разумном пределе ее дробления на составные части. Вместе с тем понятие модульности нельзя сводить только к представлению сложных программных комплексов в виде набора отдельных функциональных блоков.
Актуальная для начального периода развития и использования ЭВМ проблема разработки программ, занимающих минимум основной памяти и выполняющихся за кратчайшее время, в последующем в связи резким падением стоимости аппаратной части ЭВМ, значительным возрастанием их быстродействия и объемов памяти сменилась необходимостью разработки и применения принципиально новых методов составления программ. Все это нашло свое воплощение в разработке принципа структурного программирования. Одной из целей структурного программирования было стремление облегчить разработку и отладку программных модулей, а главное - их последующее сопровождение и модификацию.
CASE-технология представляет собой совокупность средств системного анализа, проектирования, разработки и сопровождения сложных программных систем, поддерживаемых комплексом взаимоувязанных инструментальных средств автоматизации всех этапов разработки программ. Благодаря структурным методам CASE-технология на стадиях анализа и проектирования обеспечивает разработчиков широкими возможностями для различного рода моделирования, а централизованное хранение всей необходимой для проектирования информации и контроль за целостностью данных гарантируют согласованность взаимодействия всех специалистов, занятых в разработке ПО.
Система OLAP (On-Line Analytical Process) предоставляет возможность разработки информационных систем, ориентированных на yна организацию многомерных баз данных и создание корпоративных сетей, а также обеспечивает поддержку Web-технологий в сетях Internet/Intranet.
Успешное применение инструментальных средств OLAP-систем объясняется быстротой разработки приложений, гибкостью и широкими возможностями в области доступа к данным и их преобразования. В настоящее время на рынке ПО предлагается большое число OLAP-стем, разработчиками которых являются различные фирмы, например IBM, Informix, Microsoft, Oracle, Sybase и др.
13) Сетевая модель. Графическое представление сетевой структуры.
Сетевая модель данных — логическая модель данных, являющаяся расширением иерархического подхода, строгая математическая теория, описывающая структурный аспект, аспект целостности и аспект обработки данных в сетевых базах данных.
Разница между иерархической моделью данных и сетевой состоит в том, что в иерархических структурах запись-потомок должна иметь в точности одного предка, а в сетевой структуре данных у потомка может иметься любое число предков.
Сетевая БД состоит из набора экземпляров определенного типа записи и набора экземпляров определенного типа связей между этими записями.
Тип связи определяется для двух типов записи: предка и потомка. Экземпляр типа связи состоит из одного экземпляра типа записи предка и упорядоченного набора экземпляров типа записи потомка. Для данного типа связи L с типом записи предка P и типом записи потомка C должны выполняться следующие два условия:
· каждый экземпляр типа записи P является предком только в одном экземпляре типа связи L;
· каждый экземпляр типа записи C является потомком не более чем в одном экземпляре типа связи L.
Сетевая модель данных основана на тех же основных понятиях (уровень,
узел, связь), что и иерархическая модель, но в сетевой модели каждый узел
может быть связан с любым другим узлом.
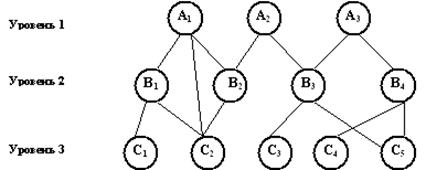
Рис. 3. Графическое изображение сетевой структуры данных
Иерархическая модель
Иерархическая модель данных представляет собой совокупность элементов данных, расположенных в порядке их подчинения и образующих по структуре перевернутое дерево (рис. 1). К основным понятиям иерархической структуры относятся: уровень, узел и связь. Узел – это совокупность реквизитов данных, описывающих информационный объект.
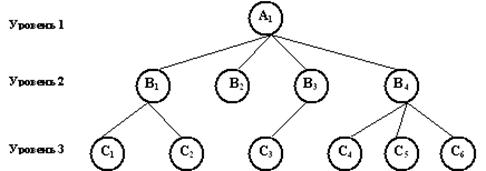
Рис. 1. Графическое изображение иерархической структуры данных.
Иерархическая структура должна удовлетворять следующим требованиям:
- каждый узел на более низком уровне связан только с одним узлом, находящимся на более высоком уровне;
- иерархическое дерево имеет только один корневой узел, не подчиненный никакому другому узлу и находящийся на самом верхнем уровне;
- к каждому узлу существует только один путь от корневого узла;
Реляционная модель. Пример реляционной таблицы.
Реляционная модель данных (РМД) — логическая модель данных, прикладная теория построения баз данных, которая является приложением к задачам обработки данных таких разделов математики как теории множеств и логика первого порядка.
На реляционной модели данных строятся реляционные базы данных.
Реляционная модель данных включает следующие компоненты:
· Структурный аспект (составляющая) — данные в базе данных представляют собой набор отношений.
· Аспект (составляющая) целостности — отношения (таблицы) отвечают определенным условиям целостности. РМД поддерживает декларативные ограничения целостности уровнядомена (типа данных), уровня отношения и уровня базы данных.
· Аспект (составляющая) обработки (манипулирования) — РМД поддерживает операторы манипулирования отношениями (реляционная алгебра, реляционное исчисление).
Кроме того, в состав реляционной модели данных включают теорию нормализации.
Части реляционной модели данных:
§ структурная
§ манипуляционная
§ целостная
Структурная часть модели определяет, что единственной структурой данных является нормализованное n-арное отношение. Отношения удобно представлять в форме таблиц, где каждая строка есть кортеж, а каждый столбец – атрибут, определенный на некотором домене..
Манипуляционная часть модели определяет два фундаментальных механизма манипулирования данными – реляционная алгебра и реляционное исчисление.
Целостная часть модели определяет требования целостности сущностей и целостности ссылок. Первое требование состоит в том, что любой кортеж любого отношения отличим от любого другого кортежа этого отношения, т.е. другими словами, любое отношение должно обладать первичным ключом.
Можно провести аналогию между элементами реляционной модели данных и элементами модели "сущность-связь". Реляционные отношения соответствуют наборам сущностей, а кортежи – сущностям. Поэтому, также как и в модели "сущность-связь" столбцы в таблице, представляющей реляционное отношение, называют атрибутами.

Основные компоненты реляционного отношения
Каждый атрибут определен на домене, поэтому домен можно рассматривать как множество допустимых значений данного атрибута. Несколько атрибутов одного отношения и даже атрибуты разных отношений могут быть определены на одном и том же домене.
В примере, показанном на рисунке, атрибуты "Оклад" и "Премия" определены на домене "Деньги". Поэтому, понятие домена имеет семантическую нагрузку: данные можно считать сравнимыми только тогда, когда они относятся к одному домену. Таким образом, в рассматриваемом нами примере сравнение атрибутов "Табельный номер" и "Оклад" является семантически некорректным, хотя они и содержат данные одного типа.
Именованное множество пар "имя атрибута – имя домена" называется схемой отношения. Мощность этого множества - называют степенью или "арностью" отношения. Набор именованных схем отношений представляет из себя схему базы данных.
Атрибут, значение которого однозначно идентифицирует кортежи, называется ключевым (или просто ключом). В нашем случае ключом является атрибут "Табельный номер", поскольку его значение уникально для каждого работника предприятия. Если кортежи идентифицируются только сцеплением значений нескольких атрибутов, то говорят, что отношение имеет составной ключ. Отношение может содержать несколько ключей. Всегда один из ключей объявляется первичным, его значения не могут обновляться. Все остальные ключи отношения называются возможными ключами.

