 2015-04-01
2015-04-01 757
757С учетом всего вышесказанного можно предложить следующую модель организации выделения основ из обрабатываемых текстов:
В системе используется настраиваемая модель стемминга, по аналогии с моделью Интеллектуального Информационного Процессора фирмы "НИС".
1) Индексация без стемминга. Данный режим является наиболее грубым приближением, он не учитывает словоизменения и является самым быстрым методом индексирования. При этом количество термов не изменяется, пространство документов имеет наибольшую размерность.
2) Стемминг по классу алгоритмов TRUNC(n), где n изменяется в пределах (3≤n≤7). Данный алгоритм удаляет из словоформ все символы, после n-го знака. Выделение наиболее приемлемого значения n является задачей будущих исследований и тестов системы.
3)
 |
Стемминг с использованием словаря флексий, с минимальным лингвистическим обеспечением. Данный способ индексирования основывается на ранее упомянутых алгоритмах удаления суффиксов (напр. Porter), а также модели описанной в работе И. Ножова.
Схема индексирования с точки зрения процесса выделения основ представлена на рис.4. На вход процесса индексации поступают все множество документов, на выходе формируется словарь основ и таблица соответствий (текст основа), которая соответствует потоку индексированных текстов. Блоки, которые осуществляют процесс индексации представлены на рис.5.
Выделяются следующие потоки данных рис.6:
1) Тексты;
2) Полные словоформы;
3) Аббревиатуры;
4)
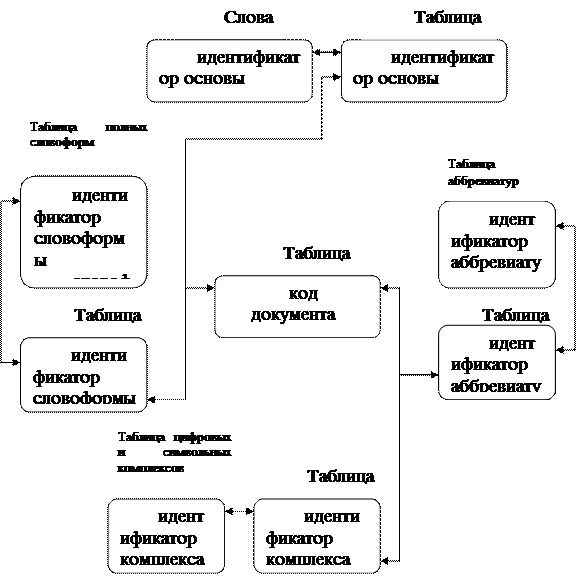 |
Цифровые и символьные комплексы;
 |
5) Основы.
Полные словоформы поступают на вход стеммера, цель которого разбить все множество словоформ на подмножества по признаку принадлежности к той или иной лексеме, привести все элементы каждого такого подмножества к уникальной основе и проиндексировать тексты по встретившимся в них основам. На выходе формируется словарь основ данных документов и заполняется структура данных, представленная на рис.13. Модуль содержит статический массив флексий, построенный на основе работ зализняка а.а. [7] и мальковского м. Г. [14]. Более подробно структуру модуля см. В [17].
Для решения вопроса о целесообразности применения полного морфологического анализа при выделении словарных основ необходимо определить степень семантической связности однокоренных словоформ.
Если взять за исходную точку классификации наиболее вариантную лексическую единицу языка — словоформу лексемы в одном из ее значений, то при последовательном снятии признаков ее семантического и формального, в том числе флективного варьирования мы последовательно можем получить серии лексических единиц все более и более обобщенных в том или ином отношении. Получаемые серии включают в себя, например, следующие единицы:
1) Словоформу лексемы. Достигается снятием лексико-семантического варьирования исходной единицы.
2) Лексико-семантический вариант (ЛСВ) лексемы. Может быть получена путем одновременного снятие в плане выражения флективного варьирования, а в плане содержания — реляционно-грамматического.
3) Лексему. Выделяется в результате снятия как формального варьирования словоформы, так и семантического варьирования ЛСВ лексемы.
4) Гиперлексему, которая получается путем одновременного снятия варьирования некоторых словообразовательных связанных лексем по различавшим их некоторым словообразовательным аффиксам в плане выражения и по соответствующим категориально грамматическим признакам в плане содержания.
5) Словообразовательное гнездо образуется через снятие признака категориально-грамматического варьирования и отождествление словообразовательно связанных слов с точностью до совпадения только корневой части плана выражения и корневой семантики в плане содержания.
6) Синонимическая группа ЛСВ. Может быть получена снятием для ряда ЛСВ слов, принадлежащих к одной части речи, варьирования по основной части плана выражения, а также варьирования по определенному семантическому признаку, которым попарно различаются в остальном тождественные ЛСВ.
По мнению поликарпова а.а., система программных средств автоматического морфологического анализа слов (включая и лемматизацию словоформ) и представления полученного материала в конкордансном виде, семантизация словоупотреблений, включения полученной таким образом семантической информации в машинную память и обработки этих данных на предмет дальнейшей фильтрации лексем и лсв через заготовленные автоматические словари гиперлексем, синонимов и антонимов и, наконец, система программ статического анализа характеристик потребления лексических единиц текста по любому из выделенных уровней, а также характеристик их формального и семантического варьирования — все это в целом может быть определено как комплексная система автоматизированного анализа частотных и вариационных единиц лексики.
Подобные системы, реализующие большее или меньшее количество вышеперечисленных функций, во множестве представлены системами искусственного интеллекта, автоматического анализа текста, машинного перевода, информационного поиска и др.
Как было сказано ранее, полноценный учет морфологии, то есть индексирование с использованием разработанного в прикладной лингвистике аппарата автоматического морфологического анализа, не всегда повышает качество поиска. Так, при улучшении полноты, может ухудшаться точность поиска. Набор требований предъявляемых к полнофункциональному парсеру для ИПС приведен в работе.
Без его использования нельзя обойтись, когда база индексирования содержит документы на многих языках. В нашей работе на данный момент не ставится задача использования системы на многоязычных корпусах, хотя принципиальных ограничений для этого нет. В перспективе планируется применение системы к англоязычному корпусу текстов. С другой стороны, в рамках данной работы не предполагалось создание отдельного морфологического анализатора по следующим причинам.
Разработка автоматического морфологического анализатора, а полуавтоматический анализ в данном случае неприемлем, из-за непомерного увеличения сложности общения с системой, сама по себе является достаточно сложной задачей.
Программы автоматического морфологического анализа достигли результатов, приблизительно равных соответствующим показателям специалистов-филологов, таким образом, сама по себе данная задача не является актуальной.
Существуют встраиваемые средства морфологического анализа для поисковых систем, выпускаемые многими крупными фирмами, работающими на российском рынке. Стоимость подобных программ колеблется от 300 до 1000 долларов США, это TextAnalyst SDK, ABBYY RETRIEVAL & MORPHOLOGY ENGINE, Яndex.Site и др.
Можно сделать вывод, что разработка отдельного морфологического анализатора будет экономически невыгодна и неоправданна с точки зрения актуальной исследовательской задачи. Все другие методы автоматического выделения основ признаны удовлетворительными, для реализации в модели индексирования. Их эффективность для подобных задач доказана их широким коммерческим использованием, и результатами исследований. Допускается расширение системы дополнительными средствами морфологического анализа, после получения тестовых результатов работы и доопределения постановки задачи.








