2015-04-01
2015-04-01 728
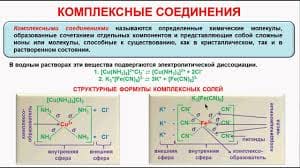
728Стеммер — это любой алгоритм выделения словарных основ. Стеммер призван уменьшить количество термов для индексации и увеличить полноту поиска информации.
Основным предположением, позволяющим использовать стемминг, является то, что морфологические варианты одного слова семантически связаны. Очевидно, что данное предположение не всегда верно. В информационном поиске использование стемминга является предметом дискуссии, тем не менее большинство исследователей добиваются хороших результатов, используя различные способы выделения основ.
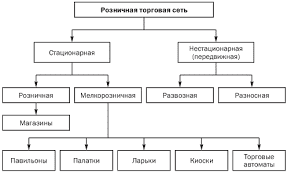
Можно выделить два основных класса стеммеров:
Основанные на удалении суффиксов,
Основанные на морфологическом анализе.
Первый класс алгоритмов отличается простотой и высокой скоростью работы. В системах информационного поиска скорость играет подчас решающую роль, поэтому данные алгоритмы являются очень распространенными. Они почти не используют специальных лингвистических знаний, ограничиваясь лишь словарями суффиксов и окончаний. Цепочки слов анализируются на наличие заданных в словаре флексий, и в случае нахождения суффиксы и окончания удаляются. Таким образом формируется список основ.
Некоторые алгоритмы не просто удаляют флексию, но заменяют ее на более короткую или изменяют основу. Точность анализа подобных алгоритмов зависит от морфологической сложности языка и конкретной реализации, а также характера текстов. В целом, они подвержены ошибкам, что закономерно вытекает из простоты их конструкции.
Второй класс алгоритмов отличается высокой точностью, так как базируется на глубоком морфологическом анализе. Скорость подобных алгоритмов значительно хуже чем у первого типа, для них требуется сложное лингвистическое обеспечение в виде словарей основ, правил словоизменения и т.д.