2015-04-01
2015-04-01 782
782Применяя стемминг, исследователи обычно добивались увеличения полноты поиска, но при этом часто ухудшалась, либо не изменялась точность. Известно, что хотя общий словарь термов при стемминге алгоритмом porter уменьшается на величину порядка 20%, точность поиска от этого не меняется. Алгоритмы удаления суффиксов, наиболее известными из которых являются алгоритмы porter, lovins, s-stemmer и другие, дают небольшой эффект применительно к текстам на английском языке, однако показывают высокие результаты например на словенском языке. Можно сделать предположение, что данный класс алгоритмов эффективен в языках с развитой морфологией.
Ошибки алгоритма porter можно отнести к нескольким видам:
Выделение лингвистически неверных основ. Данный вид ошибок ведет к тому, что некоторые несвязанные слова могут быть ассоциированы с одной основой.
Ошибки, связанные с омонимией. Слова, имеющие одинаковое написание считаются идентичными, так как не используется никакой дополнительной морфологической и синтаксической информации.
Нестандартное словоизменение. Словоформы лексемы с нестандартным словоизменением будут отнесены к разным основам.
Обобщая эти и другие ошибки можно выделить два принципиально важных класса ошибок стеммеров:
Ошибки слияния (over-stemming). Это ошибки, в результате которых семантически несвязанные словоформы были отнесены к одной основе.
Ошибки разделения (under-stemming). Это ошибки, в результате которых семантически связанные словоформы были отнесены к разным основам.
Для сравнения различных алгоритмов традиционных для информационного поиска мер полноты и точности недостаточно. С помощью двух классов ошибок определяются новые качественные характеристики стеммеров, позволяющие сравнивать их между собой.
Предпосылками метода сравнения являются группы семантически связанных слов. Идеальный алгоритм стемминга должен привести все слова в группе к одной уникальной основе. Если таких основ будет больше одной, значит стеммер допускает ошибки разделения. Это негативно отражается на точности поиска. Если основа не является уникальной, то есть принадлежит более чем одной группе, значит стеммер допускает ошибки слияния, что негативно отражается на точности поиска. Качественный стеммер допускает минимум ошибок обоих классов.
Индексы io – индекс ошибок слияния и iu индекс ошибок разделения могут быть вычислены при помощи четырех вспомогательных величин:
общее число ожидаемых слияний (очос),
общее число ожидаемых длений (очод),
общее число пропущенных слияний (очпс),
общее число неверных слияний (очнс).
Для каждой группы g число ожидаемых сияний (чос) эквивалентно общему числу различных пар словоформ в группе. В свою очередь, число ожидаемых делений (чод) вычисляется как число возможных пар словоформ, состоящих из одной словоформы принадлежащей группе и одной словоформы не принадлежащей группе. Если ng – число слов в группе, а w – общее число слов, то:
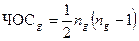 ,
,
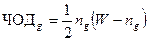 .
.
Для каждой группы число пропущенных слияний (чпс) может быть вычислено как число отсутствующих слияний между отдельными словами.
Предположим, что группа из ng словоформ содержит s основ после стемминга и число словоформ отнесенных к каждой основе равно u1, u2,..., ui соответственно. Тогда число ошибок разделения для группы определяется как:
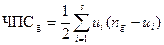 .
.
Для вычисления числа неверных слияний (чнс) потребуется дополнительная операция. Создадим инвертированный файл групп, где в каждой группе будут собраны идентичные основы, помеченные индексом своей первоначальной группы, откуда они были получены. Теперь можно вычислить чнс для каждой инвертированной группы путем сравнения индексов.
Если инвертированная группа содержит только одинаковые индексы, то ошибок слияния не было и чнс для группы равен 0.
Если же инвертированная группа содержит различные индексы, то семантически несвязанные слова были приведены к одной основе. В этом случае чнс вычисляется как число возможных комбинаций двух слов с различными индексами в пределах инвертированной группы.
Пусть группа основ с числом элементов ns содержит t различных индексов, это означает что основы группы принадлежат t различным смысловым группам. Количество элементов из этих первоначальных смысловых групп, представленных в инвертированной группе основ, обозначим как v1, v2,..., vt соответственно. Число ошибок слияния для этой группы чнс определяется как:
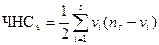 .
.
"общие" значения величин чос, чод, чпс и чнс – получаются простым суммированием по группам. Величины очос и очод используются для нормализации числа ошибок слияния и разделения в дробях:
Iu = очпс / очос
Io = oчнс / очод
Вес стеммера (sw) определяется как:
Sw = oi / ui,
Если величина sw велика, значит алгоритм сильный, в противном случае алгоритм слабый.
Замечание: необходимо помнить, что в данном случае сила или слабость алгоритма оценивается лишь как его способность правильно выделять основы слов. Из этого не следует, что сильный алгоритм обеспечит лучшие показатели точности и поиска, чем слабый. Скорее мы можем оценить точность составления словаря основ, но чтобы определить ценность стеммера для информационного поиска, необходимы последующие эксперименты.
Исследования стемминга, проведенные датскими учеными, использовали нескольких различных стеммеров, структура которых колебалась от нелингвистических алгоритмов, до алгоритмов с полным морфологическим анализом. Наибольшую эффективность показал алгоритм с лингвистическими знаниями, ограниченными изменением флективной части словоформы, то есть суффиксом и окончанием. Кроме того, имеются данные об использовании модифицированного алгоритма porter, то есть основанного на удалении суффиксов, для словенского языка. Алгоритм признан достаточно эффективным.