 2015-04-01
2015-04-01 975
975Кластерный анализ (КА) - совокупность математических методов, предназначенных для формирования относительно "отдаленных" друг от друга групп "близких" между собой объектов по информации о расстояниях или связях (мерах близости) между ними. По смыслу КА аналогичен терминам: автоматическая классификация, таксономия, распознавание образов без учителя. Фактически "кластерный анализ" - это обобщенное название достаточно большого набора алгоритмов, используемых в автоматической классификации.
Пусть множество 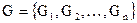 обозначает объекты, принадлежащие некоторой предметной области, каждый из которых характеризуется некоторым набором параметров x, представляющим вектор измерений
обозначает объекты, принадлежащие некоторой предметной области, каждый из которых характеризуется некоторым набором параметров x, представляющим вектор измерений 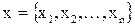 .
.
Задача кластерного анализа заключается в том, чтобы на основании данных, содержащихся во множестве x, разбить множество объектов G на m (m – целое число) кластеров (подмножеств) C1, C2, …, Cm, так, чтобы каждый объект Gj принадлежал одному и только одному подмножеству разбиения и чтобы объекты, принадлежащие одному и тому же кластеру, были сходными, в то время, как объекты, принадлежащие разным кластерам были разнородными [25].
Вообще, для термина «кластер» не существует четкого определения. Анализ источников по кластерному анализу позволил выделить основные подходы к определению этого понятия:
Кластер – это набор объектов, обладающий свойством: каждый объект из набора ближе к любому объекту из своего набора, чем к любому объекту, не принадлежащему этому набору.
Кластер – это набор объектов, обладающий свойством: каждый объект из набора ближе к одному или нескольким объектам из своего набора, чем к любому объекту, не принадлежащему набору.
Кластер – это набор объектов, обладающий свойством: каждый объект из набора ближе к центру, средней точке (объекту) этого набора, чем к центру другого набора.
Кластер – это участок повышенной плотности в пространстве, отделенный от других участками низкой плотности.
В приближении к задачам информационного поиска в текстовых массивах, можно вывести основную гипотезу кластерного анализа документов [21]: «Значения близости (связей) между документами в коллекции несут информацию об их совокупной важности, релевантности по отношению к запросам к коллекции». Это означает, что если некий документ отвечает поступившему в коллекцию запросу, то (в пространстве документов коллекции), в непосредственной близости от него, могут быть найдены документы, в большой степени отвечающие данному запросу. Документы, не отвечающие данному запросу, не будут найдены вблизи отвечающих этому запросу документов.
Таким образом, кластерный анализ документов позволяет повысить полноту ответа на запрос, поскольку пользователь, нашедший документ, отвечающий запросу, может запросить и все документы, принадлежащие тому же кластеру. Повышается и точность поиска, поскольку в ответ на запрос будут возвращаться только документы, принадлежащие одному кластеру, объединенные в него на основе своей взаимной близости.
Решением задачи кластерного анализа являются разбиения, удовлетворяющие некоторому критерию оптимальности. Этот критерий может представлять собой некоторый функционал, выражающий уровни желательности различных разбиений и группировок, который называют целевой функцией [25]. Алгоритмы кластеризации так или иначе опираются на условие повышения оптимальности разбиения, и явно или не явно, на каждом шаге стремятся максимизировать эту функцию.
Узловым моментом в кластерном анализе считается выбор меры близости объектов, от которого решающим образом зависит окончательный вариант разбиения объектов на группы при заданном алгоритме разбиения. В каждой конкретной задаче этот выбор производится по-своему, с учетом главных целей исследования, физической и статистической природы используемой информации и т. п [25]. В конечном счете, при определении близости объектов, кластерный алгоритм опирается на одно из двух основных понятий – расстояния и сходства.








