 2015-04-01
2015-04-01 2365
2365Первоначально приводятся несколько общих соображений, влияющих на организацию проектирования онтологий в целом:
1) не существует единственно правильного способа создания модели предметной области (всегда есть альтернативы). Знание того, для чего будет использоваться онтология, и того, насколько детальной она должна быть, существенно влияет на методологию построения моделей. Эффективность того или иного решения (альтернативы) всегда зависит от предполагаемого приложения и ожидаемых расширений;
2) разработка онтологии – это итеративный процесс последовательной детализации и уточнения знаний о проблемной области;
3) понятия в онтологии должны быть близки к объектам (реальным или абстрактным) и отношениям в исследуемой предметной области. Скорее всего, это существительные (объекты) или глаголы (отношения) в предложениях, которые описывают данную область.
Обобщенная методика синтеза онтологий рассматривается в виде циклической процедуры, содержащей следующий набор этапов (шагов).
Шаг 1. Определение области и масштаба онтологии.
На данном этапе необходимо ответить на следующие основные вопросы:
- какую область будет охватывать онтология?
- для чего она будет использоваться?
- на какие типы вопросов должна давать ответы онтология?
- кто будет использовать и поддерживать онтологию?
Ответы на эти вопросы могут измениться в процессе проектирования онтологии, но в любой заданный момент времени они помогают ограничить масштаб модели.
Рассмотрим онтологию компьютерных вирусов. Допустим, что ее необходимо использовать для антивирусных приложений. Тогда в онтологию будут включены понятия, описывающие различные типы вирусов. Если проектируемая онтология будет использоваться для помощи при обработке естественного языка статей в журналах о вирусах, то, возможно, понадобится включить в нее синонимы понятий и информацию о частях речи. Если люди, которые будут поддерживать онтологию, опишут предметную область языком, отличающимся от языка пользователей онтологии, то может потребоваться таблица соответствий между языками.
Один из способов определить масштаб онтологии – это формирование списка вопросов, на которые должна ответить база знаний, основанная на онтологии, т. е. вопросы для проверки компетентности, которые являются, как правило, формальными и не должны быть исчерпывающими.
В области вирусов возможны следующие вопросы для проверки компетентности:
1. Какие характеристики вирусов следует учитывать?
2. Какие вирусы наиболее опасны?
3. Какие характеристики вирусов влияют на их опасность?
4. Какие из файловых вирусов безопасны?
Шаг 2. Рассмотрение вариантов повторного использования существующих онтологий.
На ранних стадиях проектирования всегда целесообразно проверить, имеется ли возможность использовать (или модернизировать) существующие источники данных о предметной области и задаче. Повторное использование существующих онтологий может быть необходимым, если вновь проектируемой системе придется взаимодействовать с другими приложениями, которые уже вошли в отдельные онтологии или контролируемые словари. Многие онтологии уже доступны в электронном виде и могут быть импортированы в используемую разработчиком среду проектирования онтологии. Формализм онтологии часто не имеет значения, так как многие системы представления знаний могут импортировать и экспортировать онтологии. Даже если система представления знаний не может работать напрямую с отдельным формализмом, перевод онтологии из одного формализма в другой обычно не представляет трудностей.
В Web существует значительное количество общедоступных библиотек повторно используемых онтологий – Ontolingua (https://www.ksl.stanford.edu/ software/ontolingua/), DAML (https://www.daml.org/ontologies/) и др. Существует также целый ряд доступных коммерческих онтологий – UNSPSC (www.unspsc.org), RosettaNet (www.rosettanet.org), DMOZ (www.dmoz.org) и др. Могут существовать и онтологии компьютерных вирусов. Однако далее будем считать, что соответствующих онтологий еще не существует, и разработка онтологии будет вестись «с нуля».
Шаг 3. Перечисление важных терминов в онтологии.
Считается полезным исходное составление списка всех терминов, характеризующих предметную область. Например, в число важных терминов, связанных с вирусами, входят термины «заражает», «файловая система», «загрузочный сектор», «память» и т. д. Первоначально важно получить полный список таких терминов, не беспокоясь о пересечении понятий, которые они представляют, об отношениях между терминами, о возможных свойствах понятий или о том, чем являются понятия – классами или слотами.
Следующие 2 шага – разработка иерархии классов и определение свойств понятий (слотов) – тесно переплетены и являются наиболее важными в процессе проектирования онтологии. Сложно выполнить сначала один из этих шагов, а потом – другой. Обычно в иерархии дается несколько формулировок понятий, а затем описываются свойства этих понятий и т. д.
Шаг 4. Определение классов и иерархии классов.
Существует несколько возможных подходов для разработки иерархии классов.
1. Процесс нисходящей разработки, который начинается с определения самых общих понятий предметной области с последующей их конкретизацией. Например, можно начать с создания класса «Вирусы» для общего понятия «вирус». Затем этот класс конкретизируется и создаются его подклассы: «Файловые вирусы, DOS», «Макровирусы», «Интернет-черви» и т. д. Далее можно еще более категоризировать класс «Файловые вирусы, DOS», добавив, например, подклассы «BAT», «DOS32», «WORMS» и т. д.
2. Процесс восходящей разработки, который начинается с определения самых конкретных классов, листьев иерархии с последующей группировкой этих классов в более общие понятия. Например, сначала определяются классы для вирусов PHP и VBScript, затем для этих двух классов создается общий надкласс – «Скрипт-вирусы (вирусы на командных языках)», который, в свою очередь, будет являться подклассом «WORMS».
3. Процесс комбинированной разработки – это сочетание нисходящего и восходящего подходов: сначала определяются более заметные понятия, которые затем соответствующим образом обобщаются и ограничиваются. В рассматриваемом примере можно было бы начать с нескольких понятий высшего уровня, таких, как «Вирус», и конкретных понятий, таких, как PHP и VBScript, а затем соотнести эти понятия с понятием среднего уровня, таким, как «Скрипт-вирусы (вирусы на командных языках)».
Ни один из перечисленных трех обобщенных методов не является предпочтительным. Выбор подхода в большой степени зависит от личного взгляда на предметную область. Чаще всего для разработчиков онтологий самым простым является комбинированный метод, так как понятия, находящиеся «посредине», имеют тенденцию быть самыми наглядными понятиями в предметной области.
Вне зависимости от выбора метода обычно первичным является определение классов. Из списка, составленного на шаге 3, выбираются термины, описывающие типы независимо существующих объектов. В онтологии эти термины становятся классами. Затем классы организуются в иерархическую таксономию на основании ответов на вопрос: если объект является экземпляром одного класса, будет ли он обязательно (т. е. по определению) экземпляром некоторого другого класса? Если класс А – надкласс класса В, то каждый экземпляр В также является экземпляром А. Другими словами, класс В представляет собой понятие, которое является «разновидностью» А.
Например, каждый вирус VBScript – обязательно скриптовый вирус. Поэтому класс VBScript – подкласс класса «Скрипт-вирусы (вирусы на командных языках)».
Шаг 5. Определение свойств классов – слотов.
Классы сами по себе не предоставляют достаточной информации для ответа на вопросы проверки компетентности (см. шаг 1). Для таких ответов необходимы знания о свойствах объектов каждого класса. Поэтому после определения классов осуществляется переход к описанию внутренней структуры понятий, т. е. свойств классов. После исключения из сформированного на шаге 3 общего списка терминов всех терминов-классов большинство оставшихся терминов, вероятно, будут свойствами этих классов. Для каждого свойства необходимо определить, какой класс оно описывает. Выявленные свойства становятся слотами, «привязанными» к соответствующим классам.
Слотами в онтологии могут стать несколько типов свойств объектов:
- «внутренние» свойства;
- «внешние» свойства;
- части (физические или абстрактные), если объект имеет структуру;
- отношения с другими индивидными концептами (объектами того же класса или других классов).
На рис. 5.3 показаны слоты класса «Вирусы». Все подклассы класса наследуют слот этого класса. Например, все слоты класса «Вирусы» будут унаследованы всеми подклассами этого класса. Слот должен быть привязан к самому общему классу, у объектов которого может быть данное свойство.
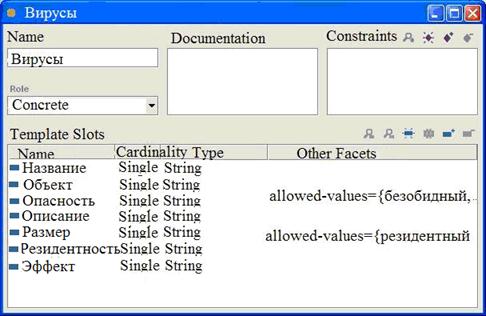
Рис. 5.3. Слоты класса «Вирусы»
Шаг 6. Определение фацетов слотов.
Слоты могут иметь различные фацеты, описывающие тип значения, разрешенные значения, число значений (мощность) и другие свойства значений, которые может принимать слот. Например, значение слота «Название» – одна строка. Т. е. «Название» – это слот с типом значения «Строка». Опишем несколько общих фацетов.
Мощность слота (кардинальность) определяет, сколько значений может иметь слот. В некоторых системах различаются только единичная (возможно только одно значение) и множественная (возможно любое число значений) мощности. Некоторые системы позволяют определить минимальную и максимальную мощности. Минимальная мощность N означает, что слот должен иметь не менее N значений. Установка «0» будет означать, что для определенного подкласса слот не может иметь значений.
Фацет типа значения слота описывает, какие типы значений можно ввести в слот. Наиболее часто используемыми типами значений являются:
- простые скалярные типы (строки, целые и вещественные числа, булевы величины и т. д.);
- списки разрешенных значений (нумерованные слоты; в Protege-2000 тип называется «Symbol» – «символ»);
- экземпляры (слоты-экземпляры позволяют задать в качестве значения экземпляр какого-либо класса; при этом должен определяться список разрешенных классов, экземпляры которых можно использовать в слоте).
На рис. 5.4 представлено определение слота «резидентность». Разрешенным классом для значений этого слота является класс «Вирусы».
Домен слота и диапазон значений слота. Разрешенные классы для слотов типа «Экземпляр» часто называют диапазоном значений слота. В примере на рис. 5.4 класс «Вирусы» является диапазоном значений слота «резидентность». Некоторые системы позволяют ограничить диапазон значений слота, если слот привязан к определенному классу. Классы, с которыми слот связан, или классы, свойство которых слот описывает, называются доменом слота. Обычно, домен слота составляют классы, к которым привязан слот, и необходимости в его определении нет.
Основные правила определения домена слота и диапазона значений слота схожи друг с другом.
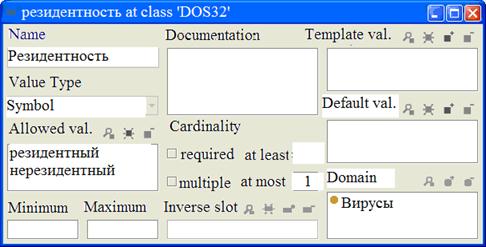
Рис. 5.4. Определение слота «резидентность»
При определении домена или диапазона значений слота находятся наиболее общие классы или класс, которые могут быть соответственно доменом или диапазоном значений слотов. С другой стороны, неэффективно определять слишком общий домен и диапазон значений: все классы в домене слота должны быть описаны слотом, а экземпляры всех классов в диапазоне значений слота должны являться потенциальными заполнителями слота.
Если список классов, определяющих диапазон значений слота или домен слота, включает класс и его подкласс, то подкласс может быть исключен.
Если список классов, определяющих диапазон значений слота или домен слота, включает все подклассы класса А, но не включает сам класс А, то в диапазон значений должен входить только класс А, а не его подклассы.
Если список классов, определяющих диапазон значений слота или домен слота, включает почти все подклассы класса А, то, скорее всего, для определения диапазона значений лучше подходит класс А.
В системах, где привязка слота к классу равнозначна добавлению класса к домену слота, к этой привязке применяются те же правила. С одной стороны, нужно стараться сделать слот как можно более общим. С другой стороны, необходимо гарантировать, что каждый класс, с которым связывается слот, на самом деле имеет свойство, которое представляет слот.
Значение слота может зависеть от значения другого слота, что порождает между слотами 2 отношения, называемых обратными. С формальной точки зрения, излишне хранить информацию и о том, и о другом. Тем не менее, с точки зрения приобретения знаний удобно иметь оба блока информации доступными в явном виде. Это позволяет системе приобретения знаний автоматически заполнять значения для обратного отношения, обеспечивая согласованность базы знаний.
Шаг 7. Создание экземпляров.
Последний шаг – это создание отдельных экземпляров классов. Для определения отдельного экземпляра класса требуется:
1) выбрать класс,
2) создать отдельный экземпляр этого класса,
3) ввести значения слотов.
Относительно последней операции следует заметить, что многие фреймовые системы позволяют определить для слотов значения по умолчанию. Если значение определенного слота одинаково для большинства экземпляров класса, то можно определить это значение как значение слота по умолчанию. При создании экземпляра класса, имеющего данный слот, система автоматически заполняет слот указанным значением. После этого значение в слоте может изменяться на любое другое (допустимое). Т. е. значения по умолчанию не накладывают каких-либо ограничений на саму модель онтологии и никак ее не меняют.

