 2015-04-06
2015-04-06 1626
1626При арифметическом кодировании каждый символ исходного текста представляется отрезком на числовой оси с длиной, равной вероятности его появления, и началом, совпадающим с концом отрезка символа, предшествующего ему в алфавите. Результатом арифметического кодирования является некоторая двоичная дробь из интервала [0, 1).
Пример. Закодировать сообщение «аава».
Вероятность р(а)=3/4; р(b)=1/4.
Пустому слову соответствует весь интервал [0, 1). После получения каждого очередного символа арифметический кодер уменьшает интервал, выбирая ту его часть, которая соответствует вновь поступившему символу.
Процесс кодирования пояснен на рис. 2.1 с учетом табл. 2.1.
Интервал [0, 1) разбивается на части, длина которых пропорциональна вероятностям символов.
На первом шаге берутся первые 3/4 интервала, соответствующие символу “а”. На втором шаге от предыдущего интервала оставляют еще 3/4, соответствующие второму символу “а”. После третьего шага от предыдущего интервала останется его правая четверть в соответствии с положением и вероятностью символа ”b”. На четвертом шаге оставляют лишь первые 3/4 от результата.
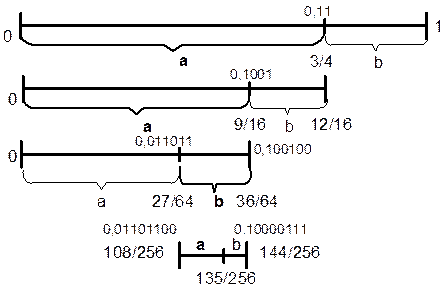
Рис.2.1
Таблица 2.1
| Шаг | Просмотренная цепочка | Интервал (в десятичной форме) | Интервал (в двоичной форме) |
| “” | [0, 1) | [0, 1) | |
| “a” | [0, 3/4) | [0, 0.11) | |
| “aa” | [0, 9/16) | [0, 0.1001) | |
| “aab” | [27/64, 36/64) | [0.011011, 0.100100) | |
| “aaba” | [108/256, 135/256) | [0.01101100, 0.10000111) |
В качестве кода можно взять любое число из диапазона, полученного на шаге 4. Например, 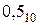
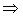
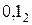 .
.








