 2015-04-30
2015-04-30 849
849Сложно делать выводы на основе необработанной первичной информации. Аналитику для принятия решения очень часто нужна сводная информация. Совокупные данные намного более информативны тем более, если их можно получить в различных разрезах. В Deductor Studio предусмотрен инструмент, реализующий сбор сводной информации – Группировка. Группировка позволяет объединять записи по полям- измерениям и агрегировать данные в полях-фактах для дальнейшего анализа.
Для настройки группировки требуется указать, какие поля являются измерениями, а какие – фактами. Для каждого факта требуется указать функцию агрегации.
Стандартные варианты агрегации: сумма, среднее, максимум, минимум, количество. Количество – это число агрегируемых значений фактов для каждой комбинации измерений.
1) Допустим, что у аналитика имеется статистика по банкам России за определенный период. Она находится в файле Banks.txt.
Перед ним стоит задача выявления ряда городов, в которых прибыль банков самая большая, для использования этих данных в дальнейшем. Для
этого аналитик должен обратить внимание на следующие поля таблицы из файла: Банк, Филиалы, Город, Прибыль, т.е. информация о названии банка, городе, в котором он находится (филиалы банка могут находиться в разных городах, следовательно, по одному и тому же банку может быть несколько записей с данными по разным городам), и прибыль банка.
Ясно, что для решения поставленной задачи первым делом необходимо найти суммарную прибыль всех банков в каждом городе. Для этого и используется группировка.
Для начала в новом проекте следует импортировать данные по банкам из текстового файла Banks.txt.
Просмотреть исходную информацию можно в виде куба, где измерениями будут Банк и Город, отображаемым фактом – Прибыль.
На шаге Настройка измерений указать по строкам Банк,а по колонкам –
Город (рис. 2.8).
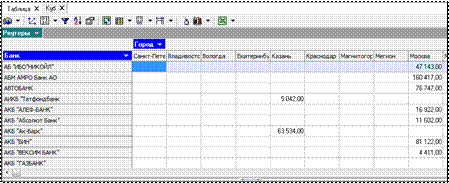
Рисунок 2.8 – Настройка измерений
Вариант агрегации для Прибыли – Сумма.
Но нам нужно получить эти данные не только для визуализации, но и для последующей обработки, следовательно, необходимо применить обработчик Группировка.
2) Группировка по городам.
Находясь в Узле импорта, запустим Мастер обработки. Выберем в качестве метода обработки Группировку данных (рис. 2.9). На втором шаге Мастера установим назначение поля Город как измерение, а назначение поля
Прибыль как факт. В качестве функции агрегации у поля Прибыль следует указать Сумма.
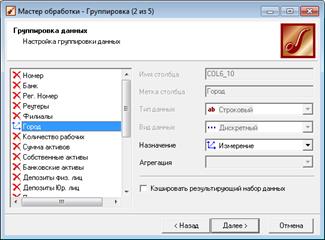
Рисунок 2.9 – Выбор метода обработки
3) Таким образом, после обработки получим суммарные данные по прибыли всех банков по каждому городу. Их можно просмотреть, используя таблицу. Теперь аналитику можно будет выполнять следующий этап обработки данных (рис. 2.10).
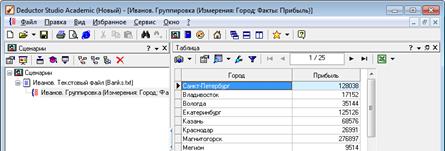
Рисунок 2.10 – Результат обработки
Результаты сохранить в файле L2_3.ded.








